
Le développement de l’Open Data
Depuis environ les années 2000, un nombre grandissant d’États et d’Administrations mettent à disposition un partie des données qu’elles produisent.
En effet, au même titre que leurs acteurs militants du logiciel libre considèrent que les progrès technologiques doivent faire partie du bien commun, ce même paradigme est apparu pour la data que certains ont qualifiée de nouvel “Or Noir du XXIème siècle”.
La multiplication des sources de données publiques ne s’est pas faite en un jour et les militants de la libération de la donnée ont bien souvent eu maille à partir avec la justice : on peut évoquer à ce sujet le destin tragique d’Aaron Schwartz (qui fut accusé d’avoir diffusé la quasi-totalité du catalogue des articles de recherche accessibles depuis le MIT), mais aussi la situation peu enviable de Julian Assange (qui publia en 2010 sur son site WikiLeaks des documents classifiés sur la 2ème guerre d’Irak).
Si les sources de données ouvertes se multiplient, les fonds publics ne semblent plus en mesure de financer les infrastructures permettant de supporter ou d’exploiter ces mannes de données de plus en plus massives.
C’est dans ce cadre-là qu’Amazon Web Services a monté son programme AWS Open Data.
AWS Open Data Program
AWS Open Data Program est un programme ouvert à toutes les organisations.
Il permet d’obtenir gratuitement des infrastructures de stockage (buckets, disques) et de calcul (instances EC2, clusters). En échange, l’organisation doit s’engager à publier les données qu’elle produit avec les ressources AWS mobilisées.
Bien sûr, pour obtenir les ressources gratuites d’AWS, il est nécessaire de présenter préalablement un dossier solide permettant de justifier de l’intérêt commun porté par le projet candidat.
Petite cartographie des projets
A ce jour, le programme “AWS Open Data” héberge 149 projets.
Toutes les données sont publiques : il suffit d’avoir un compte AWS et une paire de clefs IAM pour pouvoir y accéder.
Pour consulter l’ensemble des projets disponibles : https://registry.opendata.aws/
Voici une petite cartographie (non exhaustive) de la nature des datasets qu’on peut y trouver :
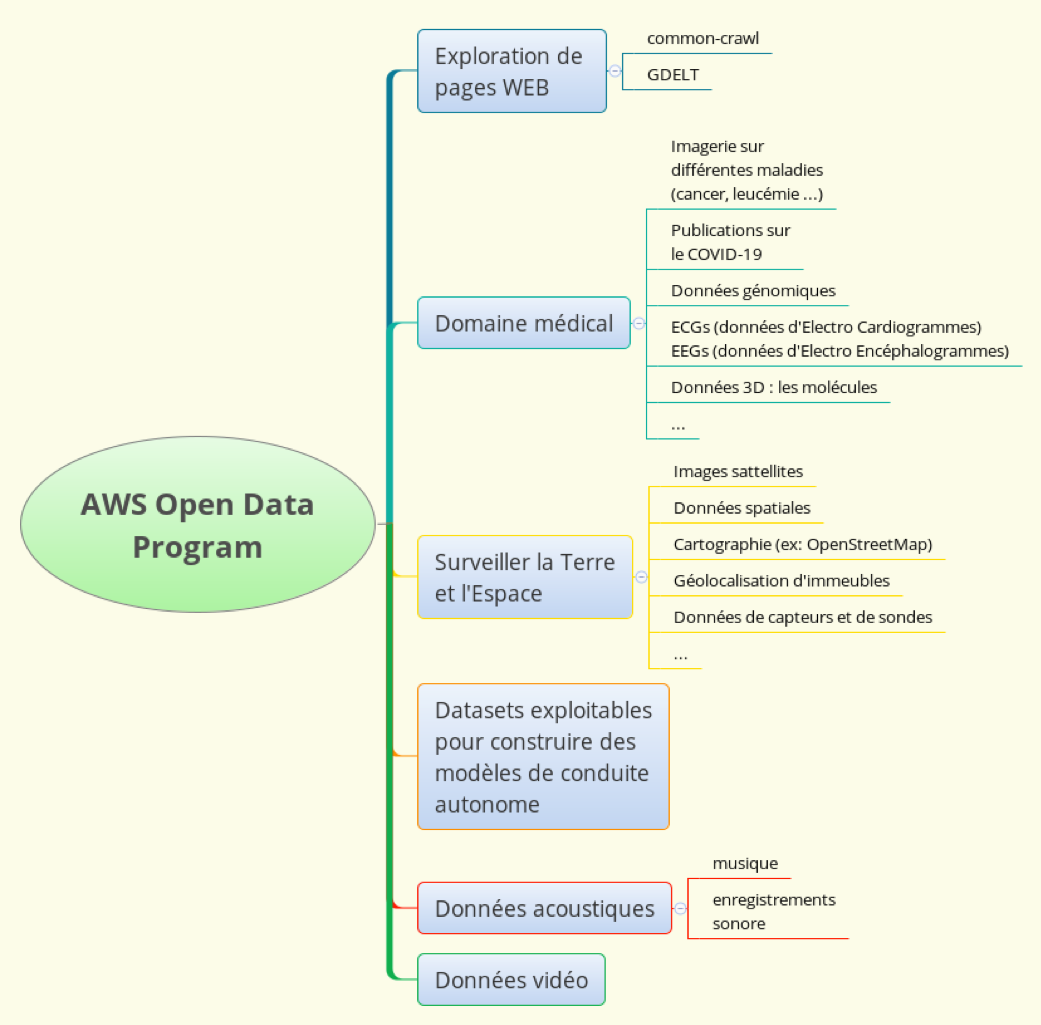
Focus sur 2 projets : Common-Crawl et GDELT
Common-crawl
Common-crawl est un projet dont l’ambition est de constituer des photographies (snapshots) du WEB.
Une fois par mois et pendant une semaine en continu, un crawler est lancé et construit de gigantesques archives de pages web.
Le dernier crawl réalisé (Mars/Avril 2020) contient 56000 archives pour un volume de plus de 62To (https://commoncrawl.org/2020/04/march-april-2020-crawl-archive-now-available/).
Bien entendu, ces archives ne contiennent pas la totalité du WEB, mais elles constituent un ensemble représentatif de pages issues de sites de références dans tous les pays du monde et dans l’ensemble des pages collectées, jusqu’à 160 langues différentes sont représentées (voir: https://commoncrawl.github.io/cc-crawl-statistics/plots/languages).
Les pages sont crawlées avec une version dérivée du crawler Open Source Apache Nutch (https://github.com/commoncrawl/nutch).
Elles sont disponibles sous format WARC (Web archives), en HTML, mais également sous format WET (archives composées de pages text c’est à dire épurées de l’ensemble des balises HTML les composant).
Les archives .wet sont donc beaucoup plus légères que les archives .warc et peuvent permettre d’alimenter assez aisément un moteur de recherche.
L’ensemble des archives Common-Crawl représentent donc une manne pour :
- constituer des corpora multilingues ayant des volumes plus conséquents que Wikipédia (https://dumps.wikimedia.org/other/static_html_dumps/);
ces corpora peuvent permettre de construire de nouveaux modèles capables de répondre aux tâches de NLP (https://github.com/Kyubyong/nlp_tasks). - proposer de nouveaux moteurs de recherche;
- peuvent être une source riche en contenu pour les historiens, les sociologues qui étudient l’évolution du monde et des sociétés.
Note importante concernant l’exploitation des données common-crawl:
Le contenu des pages disponibles dans les archives common-crawl ne peut pas être exploité directement de façon commerciales. En effet, certaines pages sont issues des rédactions des journaux en ligne et leur contenu peuvent relever de la législation sur le droit d’auteur.
Par contre, il est tout à fait possible de construire de la valeur à partir de ces données : nouveau modèle NLP, modèle de prédiction de navigation WEB …etc…
Tout ce qui est construit à partir de ces données et qui est nouveau peut être par contre exploité commercialement.
Pour donner quelques idées, voici une série de projets construits à partir des données common-crawl: https://commoncrawl.org/the-data/examples/
GDELT
GDELT signifie Global Database Event Language and Tone
site web: https://www.gdeltproject.org/
L’objectif du projet GDELT est de crawler et d’analyser des pages WEB provenant de diverses sources d’information : les sources explorées sont le plus souvent des journaux en ligne, mais aussi des contenus institutionnels ou encore des compte twitter remarquables.
L’objectif final est de pouvoir produire à partir de chaque analyse réalisée une cartographie des événements géopolitiques remarquables.
L’analyse GDELT se base sur l’ontologie CAMEO (Conflict and Mediation Event Observations). voir http://eventdata.parusanalytics.com/data.dir/cameo.html
Pour avoir une idée de ce que peut être une ontologie, consulter : https://fr.wikipedia.org/wiki/Ontologie_(informatique).
Pour avoir une idée des différents types de référentiels couramment utilisés dans l’analyse massive de documents, voir:
http://blog.sparna.fr/2013/12/07/ontologie-thesaurus-taxonomie-web-de-donnees/
L’ontologie CAMEO répertorie tout ce qui est en rapport avec :
- la diplomatie;
- les relations internationales;
- les conflits, les troubles sociaux, incidents industriels, …
L’ontologie CAMEO est susceptible d’évoluer dans le temps car elle contient des entités telles que:
- les acteurs de la scène internationale avec leurs typologies;
- un ensemble de points de géolocalisation d’intérêt;
- un ensemble d’événements pouvant relier les acteurs (guerre, traité, sommet, assassinat …etc…).
A chacun de ces événements est associé un score sur l’échelle dite de Goldstein (cette échelle varie de -10 à +10, ces valeurs extrêmes correspondant respectivement au plus négatif et au plus positif).
A chaque analyse, GDELT produit une archive avec les événements identifiés avec leur géolocalisation. (voir http://data.gdeltproject.org/events/index.html)
L’équipe produits également des GKG (Global Knowledge Graph) donnant une idée des interactions entre les acteurs au cours des dernières analyses. (voir http://data.gdeltproject.org/gkg/index.html)
Conclusion
L’essor du programme AWS Open Data (voir https://aws.amazon.com/fr/opendata/) montre l’importance majeure qu’ont pris les principaux fournisseurs de services cloud dans les programmes de recherche aux USA.
Google Cloud Platform propose lui aussi un certain nombre de données ouvertes la plupart du temps disponibles sur BigQuery (https://datasetsearch.research.google.com/). Google a également racheté la plateforme de Datascience Kaggle et met gratuitement à la disposition des data-scientists des dernières unités TPU (https://www.kaggle.com/docs/tpu) et propose des infrastructures CPU ou TPU plus anciennes sur Colaboratory (https://colab.research.google.com).
Seront-ils demain, devant les Etats, les seuls à pouvoir proposer des solutions pour financer des programmes de recherche de plus en plus coûteux capable de répondre aux nouveaux défis de l’humanité ?
Pour aller un peu plus loin…
Nous verrons dans un prochain article comment explorer quelques archives common-crawl afin de produire quelques analyses statistiques.

