
Les services cognitifs ont le vent en poupe et la détection des visages et leur reconnaissance est un sujet très actuel. Il existe des services comme Azure Cognitive Services et Azure Computer Vision mais aussi des services open-source donc gratuits… à faire tourner en local sans passer par le cloud. Nous pouvons aussi y mixer du machine learning et de l’IA.
Introduction à OpenCV
Créée en 2000 par Intel, la librairie OpenCV (Open Source Computer Vision) est une bibliothèque C/C++ temps réel pour le traitement des images. La documentation et les packages Windows, Linux, Mac sont disponibles sur opencv.org. Cette bibliothèque est leader dans son domaine, eElle utilise massivement la STL (Standard Template Library) du C++. Il existe aussi des bindings pour Python, Java, Haskell, Perl, Ruby. Egalement, une version hybride EMGU pour .NET et deux modes d’accélération matérielle :
- CUDA
- OpenCL
Opérations de bases
La gestion des images requiert des classes particulières. Le namespace cv contient de nombreuses classes C++ :
- Scalar pour la couleur
- Rect, Point, Size
- Mat pour les images
Détection de visages via Cascades Haar
Commençons par la détection de visages. La détection d’objets à l’aide des classifieurs en cascade basés sur des fonctionnalités Haar est une méthode de détection d’objets efficace proposée par Paul Viola et Michael Jones dans leur article, « Détection rapide d’objets utilisant une cascade boostée de fonctionnalités simples » dans 2001. C’est une approche basée sur l’apprentissage par machine où une fonction cascade est formée à partir de beaucoup d’images positives et négatives. Elle est ensuite utilisée pour détecter des objets dans d’autres images. Ici, nous allons travailler avec la détection de visage. Initialement, l’algorithme a besoin de beaucoup d’images positives (images de visages) et d’images négatives (images sans visages) pour former le classifieur. Ensuite, nous avons besoin d’extraire des fonctionnalités de celui-ci. Pour cela, les fonctions Haar affichées dans l’image ci-dessous sont utilisées. Ils sont comme notre noyau à convolution. Chaque fonction est une valeur unique obtenue en soustrayant la somme des pixels sous le rectangle blanc de la somme des pixels sous le rectangle noir.
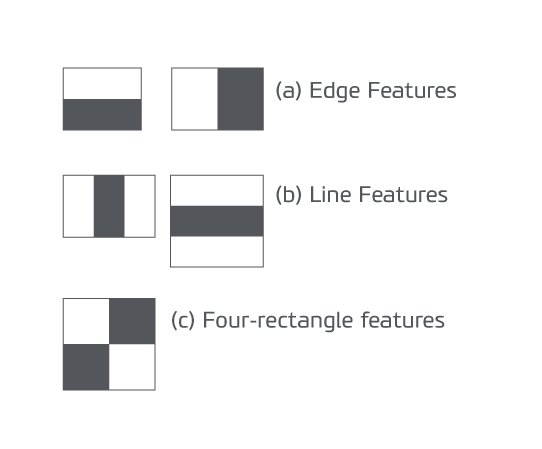
Maintenant, toutes les tailles et les emplacements possibles de chaque noyau sont employés pour calculer beaucoup de dispositifs. (Imaginez à quel point il y a besoin de calcul ? Même une fenêtre 24×24 donne des résultats de plus de 160000 fonctionnalités). Pour chaque calcul de fonction, nous devons trouver la somme des pixels sous les rectangles blancs et noirs. Pour résoudre ce fait, ils ont introduit l’image intégrale. Quelle que soit la taille de votre image, elle réduit les calculs d’un pixel donné à une opération impliquant seulement quatre pixels. Bien, n’est-ce pas ? Ça rend les choses super rapides.
Mais parmi toutes ces caractéristiques, nous avons calculé, la plupart d’entre eux sont hors de propos. Par exemple, considérez l’image ci-dessous. La rangée du haut montre deux bonnes caractéristiques. La première caractéristique choisie semble se concentrer sur la propriété « que la région des yeux est souvent plus sombre que la région du nez et des joues ». La deuxième caractéristique choisie repose sur la propriété « que les yeux sont plus foncés que le pont du nez ». Mais les mêmes fenêtres appliquées aux joues ou à tout autre endroit ne sont pas pertinents. Alors, comment pouvons-nous choisir les meilleures caractéristiques de 160000 et + caractéristiques ? Cela est réalisé par AdaBoost.

Pour cela, nous appliquons chaque fonctionnalité sur toutes les images de la formation. Pour chacune, AdaBoost trouve le meilleur seuil qui classe les faces positives et négatives. Évidemment, il y aura des erreurs, comme de classification. Nous sélectionnons les fonctionnalités avec des taux d’erreur minimal, ce qui permet de classer plus précisément le visage et les autres images.
Le processus n’est pas aussi simple que cela: chaque image se voit attribuée un poids égal au début. Après chaque classification, le poids des images mal classées est augmenté. Alors le processus se répète: de nouveaux taux d’erreurs et de poids sont calculé. Le processus se poursuit jusqu’à ce que le taux d’exactitude ou d’erreur requis soit atteint ou que le nombre requis de fonctionnalités soit trouvé..
Le dernier classifieur correspond à une somme pondérée de ces faibles classifieurs. Elle est qualifiée de faible parce que seul il ne peut pas classer l’image, mais avec d’autres forme un classifieur fort. La documentation dit même que 200 fonctionnalités fournissent la détection avec une précision de 95 %. Leur configuration finale avait environ 6000 caractéristiques. (Imaginez une réduction de 160000 + caractéristiques à 6000 caractéristiques. C’est un gros gain).
Alors maintenant, prenons une image avec une fenêtre 24 x 24 en lui appliquant 6000 caractéristiques. Vérifier si c’est le visage ou pas. Cela apparaît comme inefficace et chronophage. Mais quelle solution est proposée par les auteurs de OpenCV?
Car la région du visage ne constitue pas uniquement l’intégralité d’une image, c’est la raison pour laquelle il est préférable d’opter pour une méthode simple afin de vérifier si une fenêtre correspond à une région du visage, ou non. Si la méthode ne fonctionne pas, il faut se concentrer sur les régions où il peut y avoir un visage. En réalisant cette opération, nous avons passé plus de temps à vérifier les régions du visage possible.
Pour augmenter l’efficacité, les auteurs OpenCV ont introduit le concept de Cascade de classificateurs. Au lieu d’appliquer toutes les 6000 fonctionnalités sur une fenêtre, les fonctions sont regroupées en différents stades de classificateur et les appliquent successivement. Normalement les premières étapes contiennent beaucoup moins de fonctionnalités. Si une fenêtre ne parvient pas à la première étape, jetez-la. Si elle passe, appliquer la deuxième étape de fonctionnalités et poursuivez le processus. La fenêtre qui passe toutes les étapes se révèle être une région du visage. Voilà le plan !
Codage de la détection
Il suffit de charger une image en mémoire et d’utiliser une routine qui se nomme CascadeClassifier::detectMultiScale. L’utilisation de cette classe doit être faite aussi en faisant appel à load() en lui passant un nom de fichier de cascades. OpenCV fournit ces fichiers de données en standard. Il y en a pour le visage, les yeux, le corps, etc.

La routine imread() lit le fichier image pour le stocker dans un objet Mat. Ensuite la routine magique detectAndDraw fait le travail magique !




La routine s’effectue en faisant appel à CascadeClassifier.detectMultiScale pour détecter le visage et par la suite, les yeux.
Reconnaissance faciale avec OpenCv4
Comment identifier un individu par le biais d’une photo ? Pour cela, nous utilisons un module OpenCV « Face », que nous trouvons dans contrib sur Githib.
Le repository Github est disponible ici: https://github.com/opencv/opencv_contrib
Dans le répertoire face, vous trouverez du code pour reconnaitre les visages suivant 3 techniques :
- Eigen faces
- Fisher faces
- Local Binary Pattern Histograms
Utilisation de face
Pour faire les choses dans l’état de l’art, il faut recompiler OpenCV… ou bien incorporer les classes de face dans votre outil. Comment fonctionne face ? C’est très simple, il y a trois étapes :
- Générer un modèle à partir de photos d’individus : c’est l’apprentissage ou training
- Sauvegarder le modèle ou le charger
- Faire une prédiction en fonction d’une image quelconque
L’apprentissage
Il faut créer un fichier de configuration CSV dans lequel on met les data comme indiqué ci-dessous :
Chemin du fichier image ;index ;libellé
Exemple :
D:\Dev\cpp\OCVDetection\x64\Debug\images\CT1.PNG;20;Charlize
D:\Dev\cpp\OCVDetection\x64\Debug\images\CT2.PNG;20;Charlize
D:\Dev\cpp\OCVDetection\x64\Debug\images\CT3.PNG;20;Charlize
D:\Dev\cpp\OCVDetection\x64\Debug\images\CT4.PNG;20;Charlize
D:\Dev\cpp\OCVDetection\x64\Debug\images\CT5.PNG;20;Charlize
D:\Dev\cpp\OCVDetection\x64\Debug\images\CT6.PNG;20;Charlize
D:\Dev\cpp\OCVDetection\x64\Debug\images\CT7.PNG;20;Charlize
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL1.PNG;30;Jennifer
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL2.PNG;30;Jennifer
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL3.PNG;30;Jennifer
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL4.PNG;30;Jennifer
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL5.PNG;30;Jennifer
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL6.PNG;30;Jennifer
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL7.PNG;30;Jennifer
D:\Dev\cpp\OCVDetection\x64\Debug\images\JL8.PNG;30;Jennifer
Il y a 7 photos de Charlize Theron. Son indice est 20.
Il y a 8 photos de Jennifer Lawrence son indice est 30.

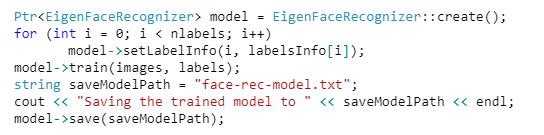
Le training consiste à charger l’ensemble des images dans un vector<Mat> et utiliser la méthode train sur un modèle :
Ensuite, on compare une image (passée en argument sur la ligne de commande) en la passant au modèle :

Voici la liste des images de tests ; les deux premières sont simples mais la troisième n’est pas ressemblante.

Je confronte l’image TEST.PNG au modèle et la sortie est la suivante :
Predicted class = 30 / Actual class = -1.
Name is : Jennifer
Le modèle fait la prédiction que c’est l’indice 30 qui correspond à Jennifer.
Je confronte l’image TEST2.PNG au modèle et la sortie est la suivante :
Predicted class = 20 / Actual class = -1.
Name is : Charlize
Le modèle fait la prédiction que c’est l’indice 20 qui correspond à Charlize.
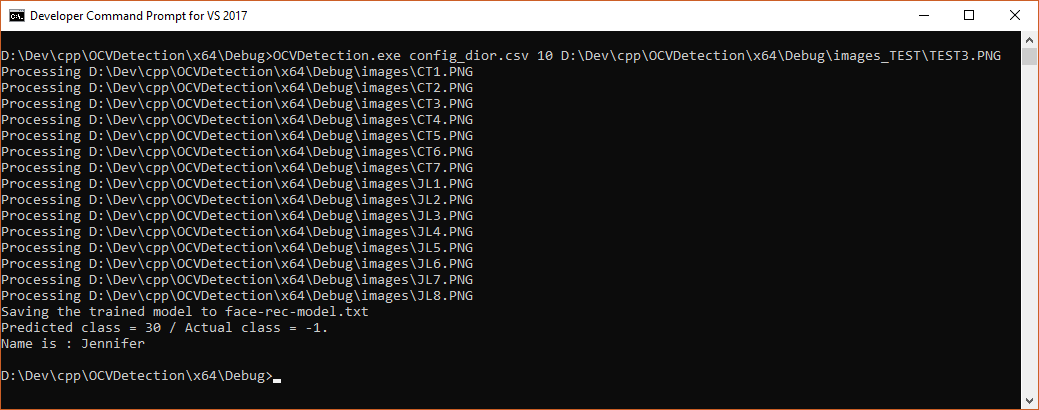
Je fais un dernier essai avec une photo peut prédictible de Jennifer, TEST3.PNG :
Predicted class = 30 / Actual class = -1.
Name is : Jennifer
Le système a quand même fonctionné. Il a prédit la bonne réponse. Magique !
L’objet de l’article n’est pas de documenter l’ensemble des fonctionnalités d’OpenCV mais de démontrer la possibilité d’obtenir « une distance » de résultat. En effet, si nous passons une photo d’une personne inconnue au module, le résultat sortant m’indique que l’analyse est plus proche de telle ou telle personnage mais avec une distance de plus de 13.000. Nous ne connaissons pas l’unité à employer, mais à partir de 10.000, nous avons remarqué que la facture de certitude est de 95%.
Pour rendre les choses ludiques, nous pouvos même coupler ces fonctionnalités à une caméra et effectuer le traitement pour chaque frame de la vidéo.
OpenCV est une librairie très puissante et passionnante à utiliser. Il y a de nombreuses options que nous n’avons pas couvertes comme la détection d’objets et de formes, les comportements de mouvements, etc. Si vous êtes intéressé, une seule adresse : https://opencv.org/

