
Dans notre dernier article, nous avons vu comment extraire les données brutes des pages du Common-crawl et à partir des données de ces pages, nous avons produit quelques statistiques portant sur les langues utilisées dans les pages, les domaines internet des pages ainsi que sur la localisation (niveau pays) des serveurs d’où elles sont publiées.
Aujourd’hui, nous proposons de reprendre les données téléchargées et de constituer un corpus de textes. Nous indexerons ensuite ces données en “text intégral” (full-text en anglais) à l’aide du moteur ElasticSearch. Après cela, nous utiliserons l’application Kibana pour explorer en langage naturel les pages web enregistrées dans ElasticSearch.
Repository git de référence
https://github.com/catherineverdiergo/cc-examples
Préparation de l’environnement
Installation de Apache Spark
- Installez un JDK1.8 et définissez la variable d’environnement JAVA_HOME,
- Ajoutez également $JAVA_HOME/bin dans votre PATH,
- Téléchargez la dernière archive Spark_2.4 depuis
https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz, - Décompressez-la dans le path de votre choix que vous réutiliserez pour définir la variable d’environnement SPARK_HOME.
Installation de l’environnement Python
Nous travaillerons avec un environnement virtuel Anaconda de type biopython que nous allons enrichir avec quelques paquets supplémentaires.
$> conda create -n cc-pyspark biopython python=3.7
$> conda activate cc-pyspark
# Ajout des paquets supplémentaires
(cc-pyspark) $> pip install requests
(cc-pyspark) $> pip install warc3-wet
(cc-pyspark) $> pip install lang-id
(cc-pyspark) $> pip install maxminddb-geolite2
(cc-pyspark) $> pip install jupyter
(cc-pyspark) $> pip install plotly
(cc-pyspark) $> pip install pandas
Description des paquets additionnels :
|
paquet |
description |
|
requests |
Pour dialoguer en https |
|
warc3-wet |
Pour parser les fichiers WARC ou WET |
|
lang-id |
Pour identifier la langue d’un texte |
|
maxminddb-geolite2 |
Pour identifier la géolocalisation d’un serveur |
|
jupyter |
Pour travailler avec Jupyter notebooks |
|
matplotlib + seaborn |
Pour créer des graphiques dans un notebook |
|
pandas |
Dataframes Python exploitables avec plotly |
Installer et lancer ElasticSearch
Deux modes d’installation : directement sur votre machine ou via docker
Directement sur votre machine
Au moment où j’écris cet article, la dernière version disponible est la 7.8.0 et elle peut être téléchargée ici : https://www.elastic.co/fr/downloads/elasticsearch
- Téléchargez l’archive correspondant à votre système d’exploitation,
- L’installation est simple : décompressez l’archive à l’emplacement de votre choix sur le disque et optionnellement,
- Créez-vous une variable d’environnement ES_HOME,
- Lancez ElasticSearch avec : $ES_HOME/bin/elasticsearch (ajoutez .bat sous Windows),
- Vérifiez que votre serveur est on-line en allant sur http://localhost:9200.
Avec Docker
docker run -p 9200:9200 -p 9300:9300 \
-e « discovery.type=single-node » \
–name elastic \
docker.elastic.co/elasticsearch/elasticsearch:7.8.0
Comme expliqué ici : https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
Vérifiez ensuite que la page http://localhost:9200 réponde bien.
Installer et lancer kibana
Les versions ElasticSearch et Kibana doivent toujours être synchronisées.
Nous allons donc installer Kibana7.8.0.
Deux modes d’installation : directement sur votre machine ou via docker
Directement sur votre machine
- Téléchargez l’archive https://www.elastic.co/fr/downloads/kibana et procéder de la même façon qu’avec ElasticSearch,
- Lancez Kibana avec $KIBANA_HOME/bin/kibana(.bat),
- Vérifiez que Kibana fonctionne correctement en allant sur : http://localhost:5601
Avec Docker
Retrouvez l’ID de votre container ElasticSearch avec un :
docker ps
puis lancez :
docker run \
–link elastic:elasticsearch \
-p 5601:5601 docker.elastic.co/kibana/kibana:7.8.0
Vérifiez ensuite que la page http://localhost:5601 réponde bien.
Vous pouvez télécharger les données exemples ou non. Bien entendu, à ce stade, notre index ElasticSearch n’est pas encore alimenté.
Install elasticsearch/spark
- Téléchargez la version ad-hoc de elasticsearch-hadoop depuis :
https://www.elastic.co/fr/downloads/hadoop, - Depuis l’archive téléchargée, extrayez la lib java suivante : elasticsearch-spark-20_2.11-7.8.0.jar et enregistrez la dans le répertoire de votre choix.
La bibliothèque elasticsearch-spark-20_2.11-7.8.0.jar va nous servir à alimenter un index ElasticSearch.
Quelques mots sur ElasticSearch
ElasticSearch est une base de données scalable orientée document.
ElasticSearch, comme le produit concurrent le plus célèbre : Apache SolR, embarque la bibliothèque Java Lucene. Lucene permet de constituer des index inversés à partir d’un corpus de textes.
En mode par défaut, lors de l’insertion de données, ElasticSearch procède (via lucene) à une indexation de tous les champs texte d’un document, ce qui permet d’effectuer des recherches full-text dans les documents.
Bien qu’il s’agisse d’une base de données, l’unité de stockage d’entités dans ElasticSearch ne s’appelle pas “table” mais “index”. Un index Lucene ou ElasticSearch est en fait une table de stockage accompagnée de son index full-text.
Extraction d’un corpus prêt à indexer
Choix des langues
ElasticSearch est nativement doté de modules permettant d’effectuer un preprocessing sur les textes d’un corpus avant d’effectuer son indexation.
Ce preprocessing correspond au travail de l’analyzer associé à l’index.
Le moteur dispose d’un analyzer par défaut (que nous allons utiliser pour simplifier), mais il est possible :
- De construire son propre analyzer (spécifique par langue) ; Pour en savoir plus sur les langues supportées nativement, lisez :
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lang-analyzer.html - D’utiliser des plugins pour pouvoir construire des index pour des langues non supportées nativement. A titre d’exemple, cet article décrit l’usage de plugins pour le chinois, le coréen et le japonais : https://www.elastic.co/fr/blog/how-to-search-ch-jp-kr-part-1
Par contre, il n’est pas possible d’utiliser plusieurs analyzers pour traiter un seul corpus.
Ainsi, si l’on souhaite spécialiser ses analyzers par langue, il faudra également prévoir un index par langue lors de l’intégration des données.
Comme nous souhaitons utiliser l’analyzer par défaut, pour obtenir des résultats assez corrects, nous allons extraire de nos fichiers wet issus de Common Crawl un corpus composé uniquement de textes en anglais et en français.
Pour en savoir plus sur le preprocessing opéré par l’analyzer par défaut d’ElasticSearch, consultez : https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-standard-analyzer.html
Programme d’extraction et résultats
Sur le modèle de l’article précédent, nous avons travaillé sur 4 fichiers WET pour extraire deux datasets en parquet contenant respectivement un corpus français et un corpus anglais.
Pour cette version, nous ne nous sommes pas contentés d’identifier seulement le pays d’hébergement du serveur de domaine mais nous avons également intégré des données plus fines de géolocalisation.
Voir le fichier python:
https://github.com/catherineverdiergo/cc-examples/blob/master/wetesindexcorpus.py
(cc-pyspark) $> PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH \
PYSPARK_DRIVER_PYTHON=`which python` \
PYSPARK_PYTHON=`which python` \
PYSPARK_SUBMIT_ARGS=”local[*] –driver-memory 4g” \
python wetesindexcorpus.py CC-MAIN-2020-16 for_es_index
L’exécution du programme étant assez longue, il est possible de travailler directement sur les corpus résultant, sauvegardé dans le répertoire :
https://github.com/catherineverdiergo/cc-examples/tree/master/for_es_indexing
Création du mapping d’index ElasticSearch
Avant d’intégrer nos données, nous allons créer un mapping pour notre nouvel Index.
On peut considérer cela comme un schéma des données : on pourra y préciser quels champs seront ou non indexés (au sens full-text) et éventuellement y définir un analyzer personnalisé (nous ne le ferons pas sur cet exemple puisque nous avons décidé de nous fier à l’analyzer par défaut).
Nous allons construire notre mapping en nous basant sur le schéma parquet de nos fichiers de sortie. Nous pouvons l’afficher aisément en exécutant les instructions suivantes avec pyspark:
>>> df=spark.read.parquet(‘for_es_indexing’)
>>> df.printSchema()
root
|– url: string (nullable = true)
|– domain: string (nullable = true)
|– date: date (nullable = true)
|– country: string (nullable = true)
|– loc: array (nullable = true)
| |– element: float (containsNull = true)
|– text: string (nullable = true)
|– lang: string (nullable = true)
Pour construire notre mapping ElasticSearch, nous construisons un template ElasticSearch que nous allons intégrer dans le moteur à l’aide de l’API Restful ElasticSearch et de Kibana.
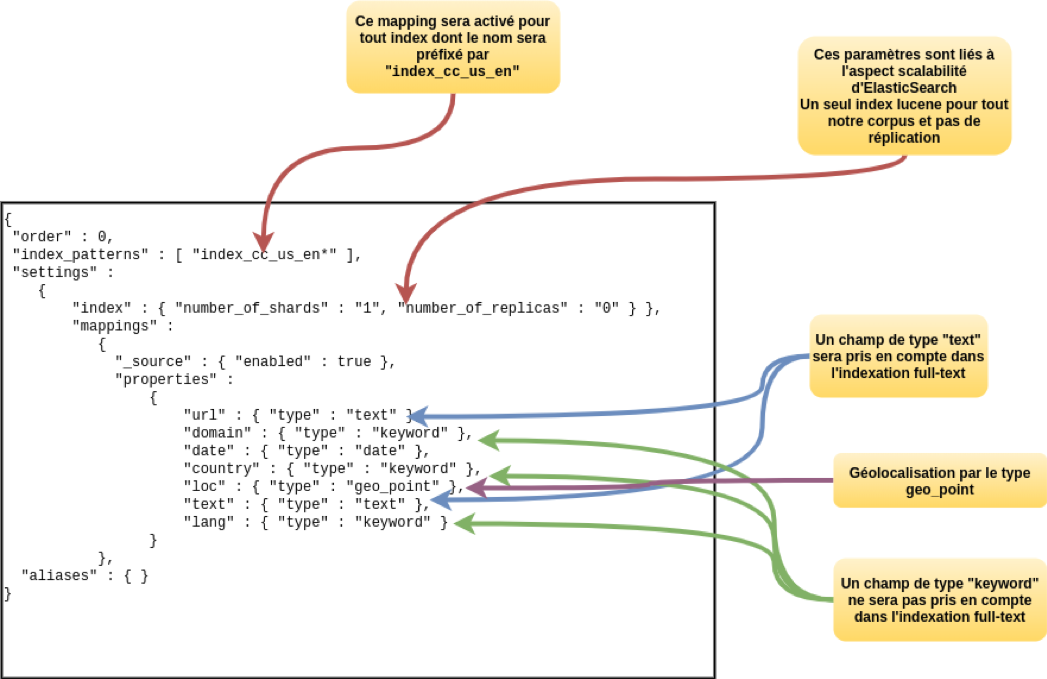
Voici notre template :
{
« order » : 0,
« index_patterns » : [ « index_cc_us_en* » ],
« settings » :
{
« index » : { « number_of_shards » : « 1 », « number_of_replicas » : « 0 » } },
« mappings » :
{
« _source » : { « enabled » : true },
« properties » :
{
« url » : { « type » : « text » },
« domain » : { « type » : « keyword » },
« date » : { « type » : « date » },
« country » : { « type » : « keyword » },
« loc » : { « type » : « geo_point » },
« text » : { « type » : « text » },
« lang » : { « type » : « keyword » }
}
},
« aliases » : { }
}
Et voici quelques éléments pour comprendre comment il est construit :
Pour enregistrer le template sous ElasticSearch, affichez la page Kibana/Dev-tools : http://localhost:5601/app/kibana#/dev_tools/console, et entrez la commande REST suivante :
PUT _template/cc_tpl_1
{
« order » : 0,
« index_patterns » : [ « index_cc_us_en* » ],
« settings » :
{
« index » : { « number_of_shards » : « 1 », « number_of_replicas » : « 0 » } },
« mappings » :
{
« _source » : { « enabled » : true },
« properties » :
{
« url » : { « type » : « text » },
« domain » : { « type » : « keyword » },
« date » : { « type » : « date » },
« country » : { « type » : « keyword » },
« loc » : { « type » : « geo_point » },
« text » : { « type » : « text » },
« lang » : { « type » : « keyword » }
}
},
« aliases » : { }
}
Ensuite exécutez-la à l’aide de la flèche sur la droite du panel (située sur la même ligne que l’instruction REST “PUT _template/cc_tpl_1”).
Enregistrement des données dans un Index
Cela peut se faire facilement avec pyspark et la bibliothèque java elasticsearch-spark-20_2.11-7.8.0.jar que nous avons téléchargée précédemment.
- Placez-vous dans le répertoire du projet,
- Lancez pyspark via la commande suivante :
pyspark –jars $path_to_your_libs/elasticsearch-spark-20_2.11-7.8.0.jar \
–driver-memory 4g
- Puis, dans pyspark, tapez les deux commandes suivantes :
df = spark.read.parquet(‘for_es_indexing’)
(df.write
.mode(« overwrite »)
.format(« org.elasticsearch.spark.sql »)
.option(« es.nodes.wan.only », »true »)
.option(« es.nodes », « http://localhost:9200 »)
.save(« index_cc_us_en_20200630 »))
Pendant que le job traite les données, il est possible de voir le nombre de documents traité depuis l’interface Kibana :
http://localhost:5601/app/kibana#/management/elasticsearch/index_management/indices
Exploration du corpus avec Kibana Discover
Création d’un index pattern
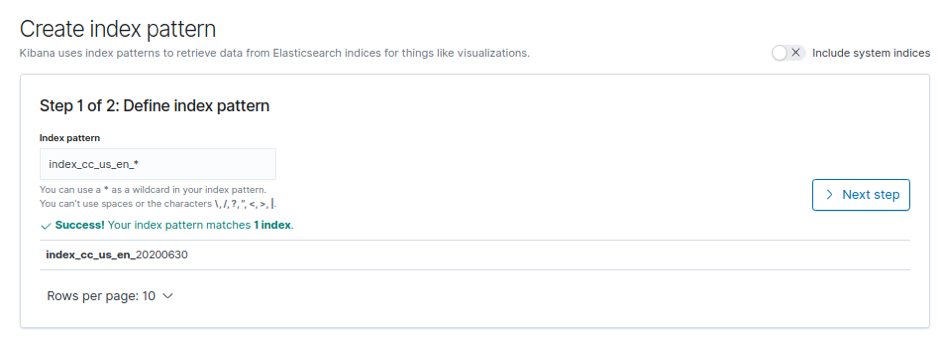
Pour explorer un ou plusieurs index avec Kibana Discover, il faut préalablement créer un “index-pattern” :
Allez sur la page web suivante de kibana :
http://localhost:5601/app/kibana#/management/kibana/index_pattern?_g=()
et créez un index pattern avec le pattern suivant: « index_cc_us_en_*”
A l’étape suivante, sélectionnez le champ “date” comme référence temporelle :
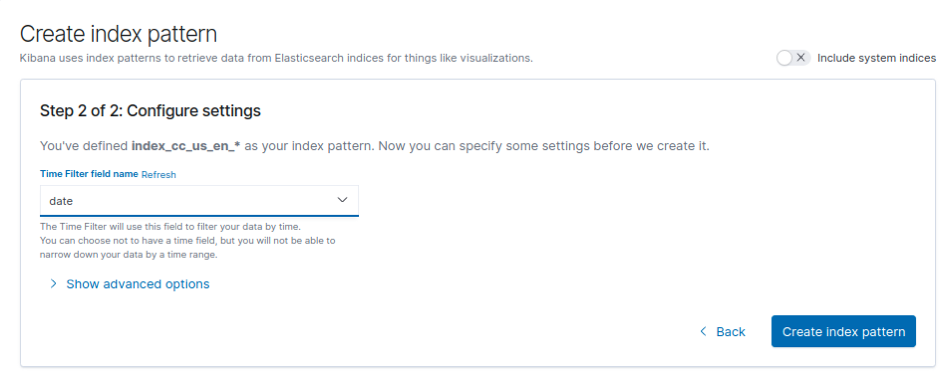
Puis validez en créant votre index-pattern.
Explorer avec Kibana Discover
Allez à la page Discover de Kibana : http://localhost:5601/app/kibana#/discover
Sélectionnez votre index-pattern et réglez l’intervalle de temps à 1 an pour voir apparaître les premiers documents indexés :
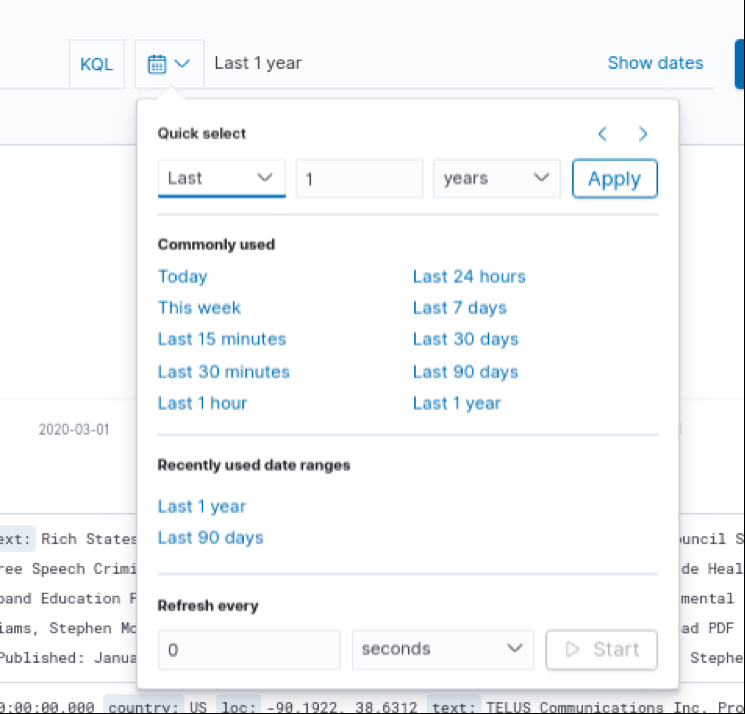
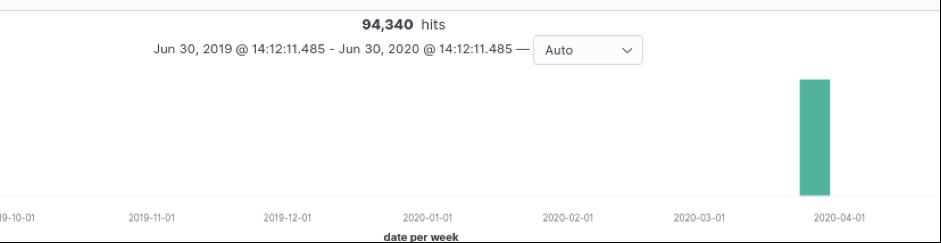
Sur l’histogramme de Kibana Discover, nos documents sont tous rassemblés à la même date : le 23 mars 2020 (date du crawl de Common Crawl) :
Il est maintenant possible d’explorer notre corpus en entrant des requêtes full-text, par exemple :
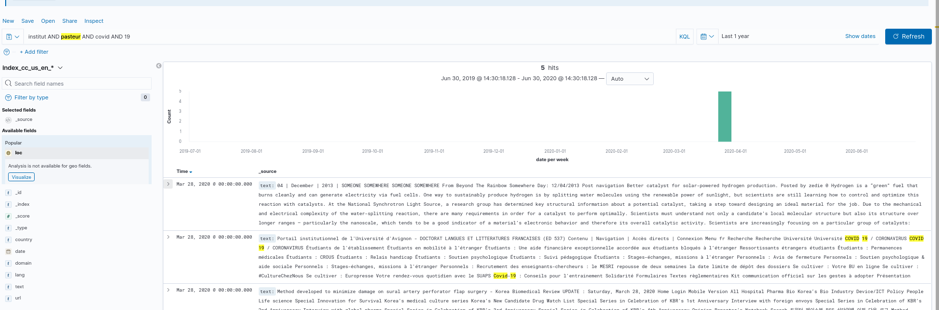
Si vous tentez plusieurs types de recherche, vous pouvez constater que le texte contenu dans les fichiers WET ne contient certes plus la partie HTML des pages crawlées mais que le texte résultant qui comporte beaucoup de “bruit” car tous les textes contenus dans les header/footer(têtes/pieds) des pages persistent dans le document texte résultant.
L’idéal serait sans doute d’appliquer un preprocessing préalable à l’intégration dans ElasticSearch en essayant d’éliminer des textes et/ou les paragraphes de moins de trois lignes par exemple.
Créez un dashboard avec une carte géographique sous Kibana
L’objectif est d’exploiter les données de géolocalisation intégrées dans le dataset afin d’avoir une idée de la répartition géographique des serveurs proposant les pages Web en français et en anglais que nous venons d’indexer.
Allez sur la page Kibana / Dashboard : http://localhost:5601/app/kibana#/dashboard
- Cliquez sur le bouton “create new” et sélectionnez un object “Map”:
,
- Repositionnez votre intervalle temporel d’exploration à 1 an (comme précédemment lors de l’usage de Kibana / Discover),
- Cliquez ensuite sur votre droite (“Add layer”) et sélectionnez “Documents” :
- Sélectionnez ensuite l’index-pattern créé plus haut (le champ de type geo_point est automatiquement sélectionné car il est unique par document),
- Sélectionnez enfin le radio-bouton “Show clusters when results exceed 10000”.
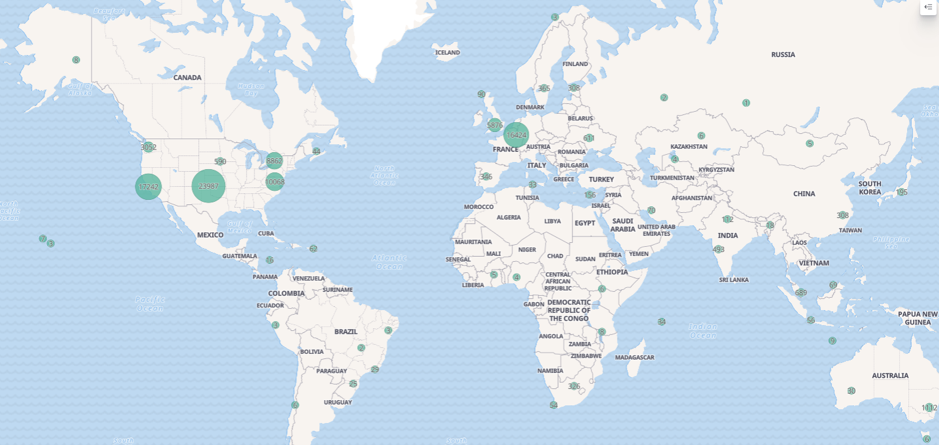
Vous obtenez alors une carte donnant la répartition géographique des serveurs d’où proviennent les pages de notre corpus.
On obtient une carte de ce type :
Pour savoir comment mapper ces données de géolocalisation dans les index ElasticSearch (plusieurs méthodes sont possibles), référez-vous à :
https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-point.html
Conclusion
Cet article clôt ce cycle consacré au programme : “AWS Open Data Project”.
Nous espérons que ces petites publications vous auront donné soit envie de travailler avec les données publiques présentes dans ces projets, soit avoir des idées pour exploiter certains datasets et enrichir vos propres applications.

