
DAT, HLD, LLD, schéma technique, readme : autant de types de livrables indispensables pour décrire nos projets informatiques, mais qui deviennent au fil du temps un véritable casse-tête à mettre à jour. Ils pourraient même sembler bien éloignés de l’outillage réservé au code informatique. Et s’il était possible de rendre ces livrables dynamiques, au même rythme que du code ? C’est effectivement le cas, notamment grâce à la philosophie docs-as-code, et l’utilisation de Terraform et terraform-docs.
Les retombées positives sont immédiates :
- Gain de temps grâce aux concepts de réutilisation et d’automatisation,
- Pérennité d’une documentation qui se met à jour automatiquement avec le code,
- Garantie d’une documentation juste qui suit les évolutions du projet.
Docs-as-code à la rescousse
Au milieu des années 2010, Riona MacNamara partage le constat avec ses collègues du pauvre niveau général de la documentation des projets chez Google. Ils décident donc de l’améliorer et lancent alors le projet “g3doc”.Depuis cette impulsion et les conférences qui ont suivi, plusieurs développeurs et informaticiens ont ensuite documenté cette approche sur un site communautaire “Write the Docs”, où ils définissent ainsi la Documentation as Code :
You should be writing documentation with the same tools as code.
Cette philosophie inclut entre autres l’utilisation de la syntaxe Markdown, du versioning avec Git, etc.Pour le fun, j’ajoute qu’on pourrait même la rebaptiser “e-Docs-as-Code”, histoire d’en faire un palindrome
Erreurs & dérives
Revenons quelques instants à la nature des documents qui nous intéressent. Un document d’architecture, que ce soit un Document d’Architecture Technique (DAT), un High-level design (HLD), d’un Low-level design (LLD), schéma technique ou encore d’un descripteur de code (readme), est constitué d’informations statiques (techniques, fonctionnelles) qui sont donc consignées manuellement.
Par conséquent, il y a de forts risques que la documentation soit fausse, pour deux raisons essentielles :
- Qui dit traitement manuel dit erreurs humaines : les informations peuvent être incomplètes, voire erronées, parfois notamment à cause d’écarts avec l’implémentation réelle.
- Au fil du temps la documentation finira inexorablement par dériver… et ce même si elle était correctement rédigée au début du cycle de vie du projet (notamment si suffisamment de temps lui a été consacré), et même si elle a pu bénéficier de mises à jour ultérieures.
Seule solution viable : rendre la documentation dynamique.
Par quels mécanismes ? Non seulement en la complétant automatiquement à partir du code Terraform via réutilisation de ses variables d’entrée, de sortie, etc. ; mais aussi en s’assurant qu’elle soit toujours à jour, en l’associant au cycle de vie du code Terraform, ce qui permet la génération de la documentation à chaque exécution.
Voyons ensemble comment cela fonctionne, au travers de quatre exemples :
- Trois exemples avec Terraform,
- Un exemple avec terraform-docs.
1. Documentation dynamique avec Terraform
Concrètement, comment rendre variable un texte ? Dans la trousse à outils de Terraform, deux outils essentiels ouvrent la voie à la variabilisation du texte : l’interpolation pour les modèles de chaînes de caractères (string templates interpolation) et la fonction templatefile.
L’interpolation consiste simplement à substituer des variables, en adoptant une syntaxe reconnue par Terraform :
${InterpolationVariable}
Dans la suite de cet article, on se référera aux variables d’interpolation pour désigner les variables adoptant cette syntaxe au sein d’un fichier modèle rédigé dans un autre langage que HCL (HashiCorp Configuration Language).
La fonction templatefile propose, à partir d’un fichier modèle (template), d’obtenir un rendu (rendering). On peut bien sûr conserver le rendu comme simple variable de sortie, mais on va surtout chercher à l’injecter dans un nouveau fichier grâce à une ressource de type local_file. On peut même combiner les variables de sortie de plusieurs modules pour obtenir un fichier unique. Le fichier sera donc généré à la volée à chaque exécution.
Cette fonction est recommandée par Hashicorp à partir de Terraform 0.12 en lieu et place de la data source template_file, qui finira sans doute par être dépréciée.
Ces deux concepts peuvent alors être associé et exploités dans nombreux cas de figure :
- Script d’initialisation système en bash, type AWS user data ou Azure cloud-init,
- Documentation projet,
- Schéma vectoriel XML avec diagrams.net (anciennement draw.io),
- Etc.
⚠ Attention, une fois qu’un fichier est utilisé comme modèle pour Terraform, cette syntaxe de variables devient exclusive à l’usage d’interpolation par Terraform.Cela pourra donc poser problème si le fichier de modèle est rédigé dans un autre langage utilisant également cette syntaxe : Terraform remplacera systématiquement la variable d’interpolation par la valeur associée, ce qui aura pour conséquence de “casser” le script du point de vue de l’autre langage.
Exemple #1 : Interpolation simple de variables dans un fichier Markdown
La rédaction de documentation au format Markdown est une bonne habitude, car c’est un format simple à rédiger puis à relire, non propriétaire, et que de nombreux outils du marché permettent de manipuler.Dans ce premier exemple, voici comment interpoler des variables simples de type string, number ou bool (pour les autres types, voir l’exemple d’interpolation complexe).

- Les variables d’interpolation sont directement intégrées au texte au format Markdown en utilisant la syntaxe ${…}.
- La cohabitation de cette syntaxe avec celle de Markdown ne pose aucun problème. La première ligne sera formatée en gras et titre de niveau 1.

- La fonction template_file (ligne 2) charge le fichier modèle au format Markdown.
- Les variables d’interpolation sont associées à des variables d’entrée Terraform (lignes 4-5).
- Les noms des variables d’interpolation peuvent donc différer par rapport à ceux des variables d’entrée Terraform (attention toutefois aux confusions).
- On peut modifier les variables d’entrée Terraform grâce à des fonctions, comme par exemple passer la première lettre de chaque mot en majuscule ons avec la fonction title (ligne 4).
L’argument filename (ligne 8) forge et le chemin & nom du fichier à créer à partir de l’argument content (ligne 2).

- La déclaration de la variable Environment (lignes 7-11) n’inclut pas la vérification de la casse. Pour cela il aurait fallu lui intégrer un bloc de règles de validation syntaxique avec une regex en condition.

- Les variables d’interpolation ont bien été remplacées par les valeurs des variables d’entrées Terraform, puis formatées comme prévu par la syntaxe Markdown.
Exemple #2 : Interpolation de labels dans un schéma vectoriel XML
Rien de pire qu’un schéma technique faux… Oui, mais comment peut-on manipuler un schéma comme du code ? Grâce aux schémas vectoriels qui s’expriment… en XML ! Il va donc être possible de créer un fichier modèle et de lui fournir des variables d’interpolation, comme précédemment.Outre sa gratuité, diagrams.net (anciennement draw.io) permet l’export de schémas vectoriels au format XML, ce qui permet d’interagir ensuite facilement avec eux.
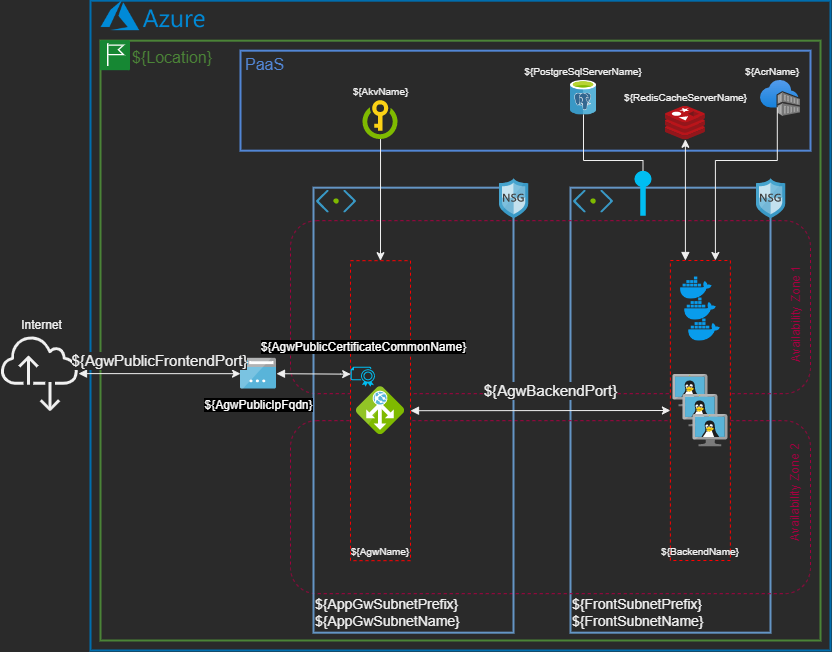
- Les labels des objets ont simplement été édités à la main dans l’éditeur graphique de diagrams.net, toujours en utilisant la même syntaxe ${…}.
- On peut faire afficher toutes sortes de chaînes de caractères : ID, nom, adresse IP, etc. issues des attributs de modules, ressources ou data sources.
- Dans un schéma, il n’est a priori possible d’interpoler que des chaînes de caractères, comme décrit dans l’exemple précédent, mais pas de listes (cf. exemple suivant pour voir la syntaxe associée).
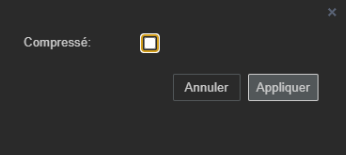
- Afin de permettre à Terraform d’interagir avec le contenu XML, il faut bien penser à décocher l’option “Fichier > Propriétés > Compressé”. Cette option est actuellement disponible tant sur le client lourd que sur l’application web.
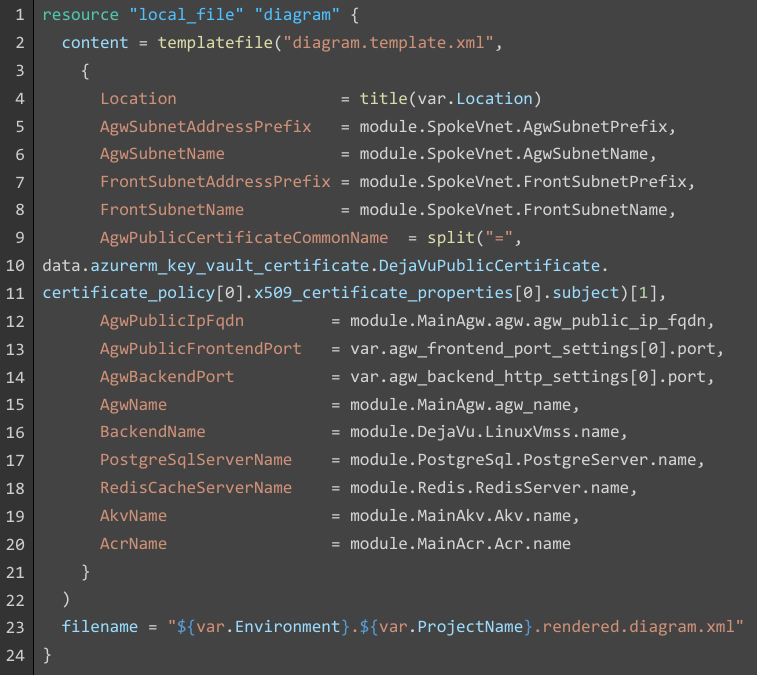
- Certaines variables ne sont pas accessibles en sortie de module, car les ressources Terraform associées ne les proposent pas en attribut. Il faut alors invoquer les variables qui ont été fournies en entrée du module (lignes 13-14).
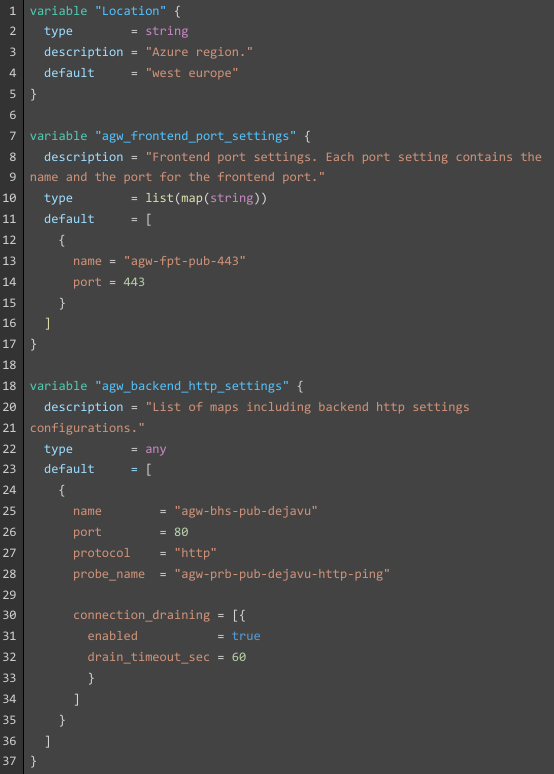
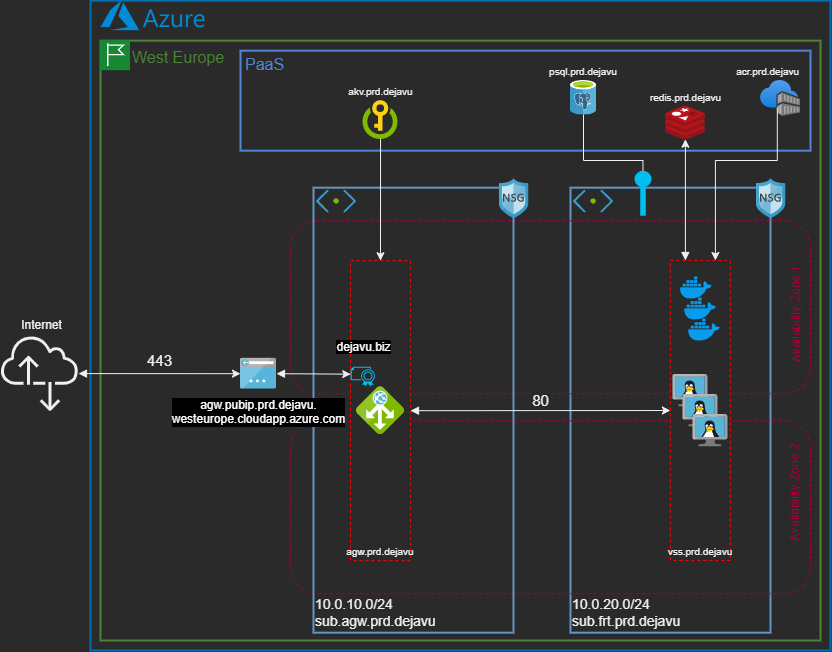
Exemple #3 : Interpolation de variables avec directives dans un fichier Markdown.
Comment gérer l’interpolation dans des cas plus complexes, lorsque les scripts Terraform intègrent des expressions conditionnelles, ou des boucles avec les méta-arguments count ou for_each ?
Terraform propose pour cela l’utilisation des directives if et for (string templates directives) qui peuvent être intégrées dans les fichiers modèles.Ces directives peuvent être imbriquées de façon récursive (nested), ce qui ouvre la voie à de multiples possibilités (et à une certaine complexité…).
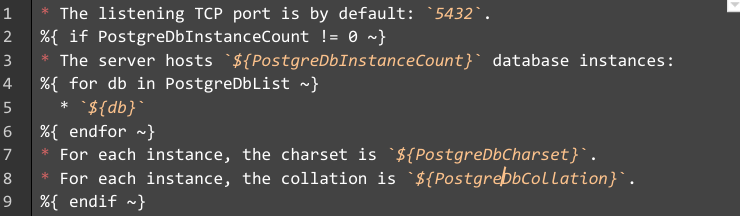
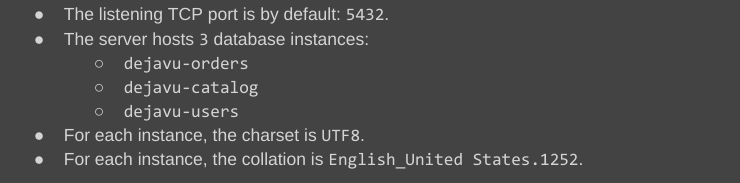
- La directive if (ligne 2) évalue une condition non nulle sur la variable PostgreDbInstanceCount, afin de décider s’il faut afficher ou non l’ensemble du bloc suivant, jusqu’à l’expression de fin de directive %{? endif ~} (ligne 9).
- La directive for (ligne 4) effectue une itération sur la variable PostgreDbList qui est de type list, jusqu’à l’expression de fin de directive %{? endfor ~} (ligne 6).
- L’utilisation de directives au sein du texte peut rapidement mettre le bazar dans les retours à la ligne et devenir un vrai casse-tête dans la mise en page d’un fichier Markdown (c’est du vécu !).
Afin de pouvoir écrire chaque directive tranquillement sur sa propre ligne et gagner en lisibilité dans le fichier modèle, il faut alors utiliser le symbole de tilde avant la fermeture de l’accolade dans chaque expression de directive:- { if … ~}
- { else … ~}
- { endif … ~}
- { for … ~}
- { endfor … ~}
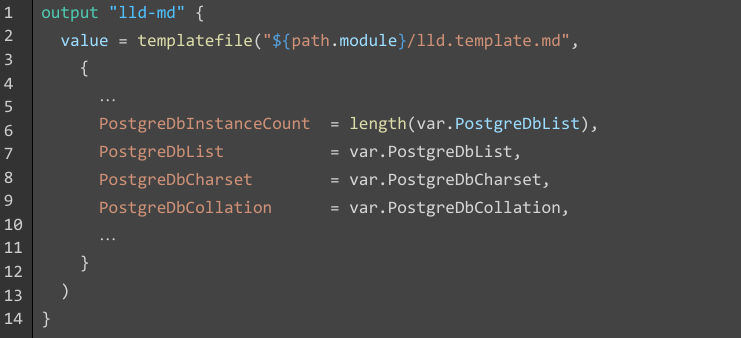
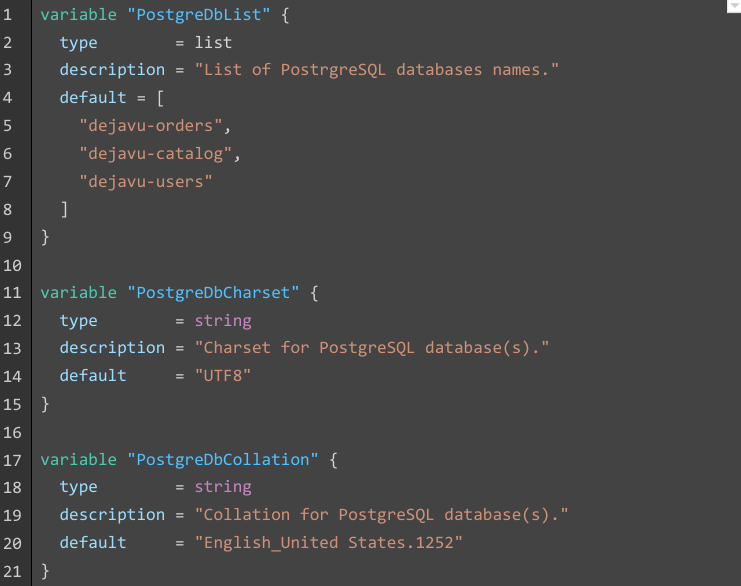
- Dans cet exemple, on pourrait faire la remarque que le code déroge au principe DRY en créant la variable supplémentaire PostgreDbInstanceCount uniquement pour le fichier modèle en Markdown, au lieu de réutiliser la variable existante PostgreDbList.
- En effet, il est tout à fait possible d’appliquer n’importe quelle fonction (ici la fonction length) sur une variable d’interpolation, y compris lorsqu’elle est évaluée à l’intérieur au sein d’une directive if ou for.
- Cela fonctionne parfaitement, mais uniquement lorsque la liste n’est pas vide. Si la liste est vide (PostgreDbList = []), alors l’évaluation de la directive échoue, tandis qu’elle n’échoue pas si elle est effectuée au niveau du script Terraform.
- De fait, il est donc bien indispensable de déclarer cette nouvelle variable pour l’usage du fichier modèle et éviter un éventuel échec à l’exécution.
- Le cas des variables de type map est particulier. Avec elles, il faut employer la syntaxe suivante afin d’afficher la valeur associée à chaque label :
- ${variable.label1}
- Attention, le label appelé par la variable d’interpolation doit exister, sinon Terraform retournera une erreur et refusera de dépasser le stade du plan.
En cas de doute sur l’existence d’un label (typiquement : la structure d’une map qui peut varier d’une instance à l’autre, comme par exemple pour des Azure Network Security Group), il faut alors utiliser les fonctions can ou try dans le fichier modèle.
2. Interpolation itérative de variables avec terraform-docs
Tenir à jour un fichier readme décrivant l’usage d’un script ou de modules Terraform peut rapidement devenir une corvée, notamment à cause du grand nombre de variables d’entrée et de sortie qu’un readme se doit de présenter. Et qui dit corvée dit tâche qui passera rapidement aux oubliettes, avec pour conséquence un fichier readme obsolète.
Heureusement, terraform-docs permet de s’affranchir de cette tâche pénible, à condition bien entendu d’avoir préalablement correctement documenté son code Terraform et plus précisément ses variables.
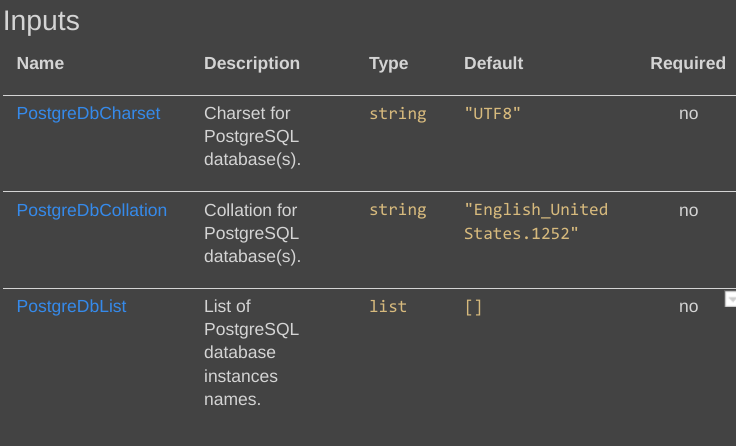
En effet, terraform-docs propose de générer un fichier au format Markdown, à l’aide d’un fichier modèle (template) en YAML et d’une syntaxe extrêmement simple pour les variables d’interpolation. Par exemple, pour invoquer toutes les variables d’entrée il suffit d’écrire :
{{ .Inputs }}
Ici, terraform-docs se charge ensuite seul d’effectuer l’itération sur l’ensemble des variables d’entrée. Puissant, rapide et on ne peut plus simple !
Outre une syntaxe d’interpolation différente, terraform-docs est un exécutable distinct de Terraform, à installer soi-même. Il n’est pas maintenu par HashiCorp.
Terraform-docs doit donc être lancé à part. Mais alors, s’éloigne-t-on de la promesse d’intégration d’une documentation dynamique au cycle de vie du code Terraform ?
Pas du tout ! Outre l’exécution manuelle, il est donc bien prévu de s’intégrer à une stratégie de pre-commit (local ou en pipeline CI/CD), grâce à un hook. Une fois le hook configuré, pre-commit permet de déclencher la mise à jour la documentation à chaque git commit.
Exemple #4 : documentation automatique avec terraform-docs
Un petit exemple vaut mieux que de longs discours : regardez plutôt.

- La syntaxe est hyper simple : tant mieux !
- Les variables d’entrée sont celles de l’exemple 3.
Conclusion
Au travers de quatre exemples concrets, nous avons vu comment la documentation (texte : par exemple au format Markdown, mais aussi schéma : par exemple au format XML) peut être variabilisée et être mise à jour à chaque exécution de Terraform ou de terraform-docs.
Et ensuite ?Afin d’aller plus loin et industrialiser votre approche, il sera judicieux de placer vos fichiers modèles à côté du code qu’ils accompagnent, c’est-à-dire dans chaque module Terraform, en suivant la logique modulaire prônée par HashiCorp (réutilisation, industrialisation, regroupement, etc.).
La prod ou la doc !
Enfin, pour tirer pleinement profit de votre “e-Docs-as-Code” en toute sérénité, il faudra constamment garder à l’esprit les éléments suivants :
- Lors de la construction du fichier modèle, attention au piège d’une syntaxe trop complexe, qui peut entraîner des échecs à l’exécution et potentiellement bloquer un déploiement en production !
- Afin d’éviter d’ avoir à faire un choix cornélien entre “la prod ou la doc” (le choix est généralement vite fait !), il faut absolument adopter une démarche qualité comme pour tout code : tester, tester, et tester encore les différentes valeurs que peuvent prendre les variables d’interpolation.
Remerciements
- Alexandre Boué, initiateur de la docs-as-code avec Terraform et qui m’a transmis sa passion pour Terraform & AWS.
- David Frappart, avec qui nous avons poussé le modèle jusqu’à la documentation automatisée des exported templates Azure, et qui a repéré le premier le projet terraform-docs.
Bibliographie
1 Présentation de g3docs par Riona MacNamara en 2015 https://www.usenix.org/conference/srecon16europe/program/presentation/macnamara

