
L’Intelligence artificielle (IA) et le big data entrent dans une nouvelle ère, celle du temps réel. Depuis quelques temps, nos projets Data gagnent de la vitesse pour passer en temps réel. Tous les secteurs s’y mettent : retail, banque, énergie, transport, e-commerce…
Il y a trois cas de figures pour envisager le temps réel :
- Il vous permet d’optimiser radicalement votre prise de décisions et d’agir plus rapidement dans des cas d’usage spécifiques tels que : la détection de fraude, l’intrusion informatique, l’analyse de données boursières et financières, la recommandation de produits.
- Le temps réel est impératif dans des cas d’application de type « streaming data », c’est-à-dire des données de types IoT, réseaux sociaux, géospatiales. En effet, le traitement et l’analyse de ce genre de données nécessitent impérativement des techniques en temps réel.
- Enfin, le temps réel est toujours synonyme de nouvelles opportunités business pour vous. L’analytics en temps réel peut vous permettre d’identifier des signaux faibles dans vos données et ainsi d’améliorer vos modèles, vos insights ou tout simplement vos ROI business
Batch Processing / Temps réel
On oppose généralement le « batch processing » (en français, le terme est moins connu sous le nom de « processing par lots ») au « real-time processing » (en français, le « processing en temps réel »).
Le batch processing concerne les cas d’usage offline. Il s’agit d’un mode de traitement asynchrone, c’est-à-dire hors ligne (offline), qui consiste à générer des prédictions sur l’ensemble des données, en une seule fois. Vous retournez alors vos résultats pour construire votre modèle prédictif à partir d’un large historique de données stockées en mémoire. Sur Amazon Web Service (AWS), SageMaker Batch Transform est une méthode de déploiement connue pour ce cas d’usage.
Le real-time processing signifie un processing de flux continus de données avec mise en œuvre d’actions d’alerting en temps réel. Il s’agit d’un mode de traitement synchrone, c’est-à-dire en ligne (online) et sur demande. Par exemple, lorsque qu’un signal atteint ou dépasse un seuil spécifique, une alerte est générée. La durée de traitement est alors de l’ordre de quelques millisecondes.
On parle aussi de stream processing pour l’analyse de flux continus de données ayant une durée de traitement de l’ordre de la seconde ou la minute. On est alors sur du quasi temps réel. Sur Amazon Web Service (AWS), SageMaker Hosting Services est une méthode de déploiement connue pour ces cas d’usage.
Comment faire du « temps réel » avec une architecture Big Data traditionnelle (Exemple applicatif simplifié sur AWS) ?
Avant d’aborder le temps réel, il s’agit de vous présenter le plus simplement possible les couches constitutives d’une architecture traditionnelle Big Data.
L’architecture ci-dessous (schéma 1) donne très schématiquement les principales étapes de traitement de données massives en mode batch sur la technologie AWS.
Rappelons que l’architecture ci-dessous est une architecture qui est asynchrone, c’est-à-dire qui ne permet pas de gérer des prédictions en temps réel.
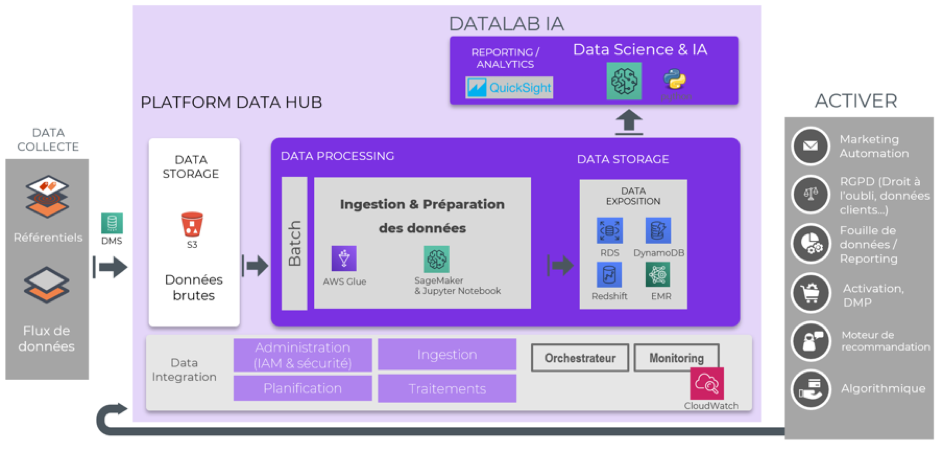
Schéma 1 : Exemple applicatif d’architecture Big Data sur AWS pour un traitement des données en mode « Batch Processing »
Ce schéma d’architecture (schéma 1) présente quatre couches techniques majeures :
1) L’ingestion des données. C’est le processus d’import des données vers l’entrée de l’architecture Big Data. Généralement, les données importées proviennent de différentes sources et sont stockées dans Amazon S3.
S3 étant un espace de stockage sécurisé, hautement disponible et scalable qui permet de gérer tout type de fichiers (json, parquet, jpeg, csv, …).
Nota : Il existe différentes options quant aux choix des outils de migration de données vers Amazon S3 :
- DMS (Database Migration Service) s’utilise généralement dans les cas de migration d’une base de données relationnelle vers une autre.
- Data pipeline permet la migration d’une base de données Amazon Redshift (ou DynamoDB ou RDS) vers S3. Ce peut également être un outil pour transformer vos données.
- AWS Glue est une autre possibilité. Il s’agit d’une solution ETL gérée entièrement par AWS.
A titre d’exemple, sur notre schéma 1, le choix de l’outil de migration s’est porté sur le service DMS (Data Migration Service). Un cas d’école simple fréquemment rencontré correspond au transfert d’une base de données MySQL on-premise vers S3.
2) Le processing des données. C’est le processus de transformation des données brutes en données agrégées et exploitables. Cette étape est généralement réalisée avec Amazon Glue et/ou Amazon Sagemaker.
SageMaker étant un service entièrement géré permettant aux développeurs de créer des variables, de former et de déployer des modèles de machine learning. Cette étape est donc fondamentale pour préparer vos données avant de les utiliser dans votre modèle de machine learning.
3) La Data exposition pour l’analyse des données. C’est l’étape de mise à disposition de vos données pour les métiers. Cette étape permet d’analyser et de valoriser les données. L’exposition des données se fait généralement sur une base de données à faible latence. Ceci permet l’optimisation du temps de lecture/écriture des données et donc d’améliorer la performance de votre architecture.
4) Le DataLab IA correspond à un espace pour travailler sur vos modèles d’IA et de machine learning, du prototypage jusqu’à l’industrialisation. QuickSight est l’outil de reporting et de datavisualisation natif d’Amazon.
Et le temps réel avec une architecture AWS ?
C’est le service Amazon Kinesis qui vous permet de traiter vos données en temps réel.
Trois points forts :
- Kinesis vous permet d’ingérer, de stocker et de traiter des données de flux vidéo, d’audio, des données IoT, … en temps réel. Le processing s’effectue en quelques minutes ou quelques secondes au lieu d’avoir à attendre plusieurs heures (ou plusieurs jours) avec l’architecture traditionnelle, présentée sur le schéma 1.
- C’est un service managé et vos applications en streaming sont exécutées sans que vous ayez à gérer l’infrastructure sous-jacente.
- Il est capable de manipuler à la fois des sources multiples de données à des latences ultra-faibles mais aussi des grandes quantités de données en streaming.
Quel service pour quel cas d’application en temps réel ?
Amazon Kinesis se compose de Kinesis Data Firehose, Kinesis Data Streams, Kinesis Data Analytics et Kinesis Video Streams.
Kinesis Data Streams
C’est un service de diffusion de données en temps réel qui permet de traiter en continu des des gigaoctets de données à partir d’une multitude de sources d’entrée (sur le schéma 2 ci-dessous, les « Data producers ») telles que les PC, mobiles, IoT, sites Web, logs d’application, …
Kinesis Stream permet de créer des partitions/séquences de données ordonnées dans le temps. On nomme ces partitions des « shards » et les données collectées sont disponibles en millisecondes.
Ensuite, les shards sont processés par des « consumers » (par exemple, par des instances EC2). Enfin, il est possible de stocker les flux de données processés dans S3, DynamoDB, Redshift ou EMR. Le stockage en bout de process reste optionnel.
L’analyse en temps réel, la détection des anomalies en temps réel ou la tarification dynamique sont des cas d’usage machine learning fréquemment implémentés avec Kinesis Data Streams.

Schéma 2 : Architecture de base utilisant Kinesis Data Streams
En complément d’information, nous vous invitons à vous documenter sur les différentes modalités d’interaction avec Kinesis Data Streams.
Il existe Kinesis Producer Library (KPL), Kinesis Client Library (KPL) ou encore Kinesis API (AWS SDK).
Kinesis Data Firehose
De la même façon qu’avec Kinesis Data Stream, les « Data producers » sont à l’origine de gigaoctets de données émises en continu. Cependant avec Kinesis Data Firehose, il n’y a pas de shards. L’étape de processing se fait directement (avec une fonction lambda par exemple). Enfin, on stocke les données dans S3.
A noter qu’avec S3 event, vous pouvez ensuite stocker ces données dans une base de données finale de type Redshift (ou DynamoDB) afin d’optimiser les temps de latence de votre application. C’est l’étape de processing qui est optionnelle ici.
Attention : il se peut que vous perdiez quelques observations lors du processing. Utiliser Firehose si ce point n’est pas bloquant pour vous !

Schéma 3 : Architecture de base utilisant Kinesis Data Firehose
Kinesis Data Analytics
Amazon Kinesis Data Analytics a pour but d’assurer le processing et l’analyse des données. Il vous permet ainsi de transformer et d’analyser facilement les données de streaming en temps réel. Et, Data Analytics gère toutes les opérations pour vous et s’adapte automatiquement au volume de vos données.
Une étape intermédiaire consiste à streamer les données d’entrée issues des « data producers » vers Kinesis Data Firehose (ou vers Kinesis Data Streams). Ensuite, le lancement de Kinesis Data Analytics permet d’initialiser l’analyse des données. Les résultats finaux peuvent être stockés dans S3 (ou redshift, par exemple).
L’utilisation de Kinesis Data Analytics est indispensable si vous souhaitez :
- effectuer des requêtes SQL sur les flux continues de données
- créer des KPIs, des dashboards ou des alarmes
- stocker vos résultats dans S3

Schéma 4 : Architecture de base utilisant Kinesis Data Analytics
Kinesis Video Streams
Kinesis Video streams est centré sur l’utilisation de flux vidéo ou audio en continu. Ce sont des webcams, cameras ou micro qui sont ici les « data producers ». Puis, les données sont consommées en continue ou en mode batch (par exemple, par des instances EC2).
Enfin, le stockage se fait dans S3.
L’utilisation de ce service est essentiellement liée à l’exploitation de flux vidéo ou audio en temps réel.
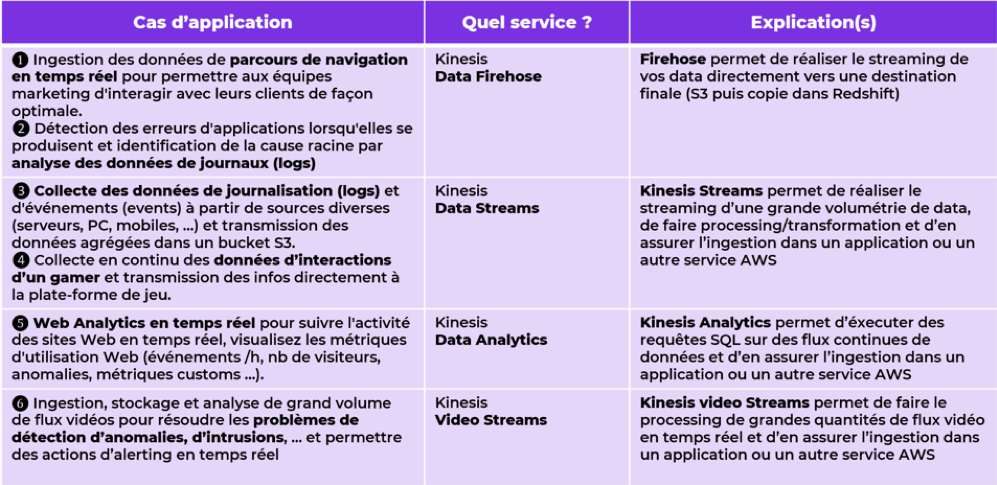
Plus d’exemples de cas d’application en temps réel avec Amazon Kinesis
Le tableau ci-dessous résume quelques grandes typologies de cas d’application en temps réel, selon le type de données d’entrée et le cas d’application.
Conclusion
Cet article présente les différents services Amazon qui permettent l’analyse des données en temps réel. Afin d’aller plus loin dans les notions, nous vous invitons à lire les différentes études de cas sur le site d’Amazon.
Dans un prochain article, nous vous proposerons un tutoriel simple de mise en place d’une architecture en temps réel via Kinesis.

