
Aujourd’hui nous présentons notre dernier article de la série autour de l’utilisation des services autoML cloud. Il s’agit de la solution proposé par Microsoft : Azure Machine Learning automatisé.
Avant d’aller plus loin, une brève présentation d’Azure Machine Learning s’impose.
Présentation d’Azure Machine Learning
Azure Machine Learning est un environnement pour faire du machine learning (ML) et permet d’entrainer des modèles hautement performants et adaptés aux besoins des entreprises.
Le principal avantage de la solution est qu’il est possible de produire des modèles ML avec des connaissances limitées en machine learning, sans avoir à gérer d’infrastructure pour l’entraînement des modèles, ni même la mise en production de ces derniers.
Pour ce faire, Azure Machine Learning se base sur une console logicielle, Azure Machine Learning Studio, qui possède plusieurs interfaces pour réaliser un cycle ML complet :
- Notebooks permet d’écrire votre code dans des blocs notes. Cet outil est généralement populaire chez les data scientists et data engineers.
- Concepteur est une interface « glisser/déposer » pour préparer les données, créer et déployer des modèles de machine learning.
- ML automatisé accompagne les utilisateurs du début jusqu’à la fin d’un cycle ML, en permettant l’automatisation du processus. Cet outil est populaire pour des néophytes sans réelles connaissances en machine learning.
Ces outils sont accompagnés par des ressources qui enrichissent Azure Machine Learning Studio comme le stockage de jeu de données, la gestion des expériences (ou cycle ML) et de modèles déployés. Ces ressources sont partagées dans le même espace de travail que les outils présentés au-dessus. Par exemple, dans la ressource « expériences », on peut trouver une expérience menée par l’outil « Concepteur » puis une autre par l’outil « ML automatisé ».
Le cas d’usage qui va suivre sera traité avec ML automatisé.
Azure Machine Learning Automatisé
Formulation du problème de machine learning
Notre problème est le suivant : nous devons trouver le meilleur modèle capable de prédire la progression de la maladie du diabète chez 442 patients, un an après leur inclusion dans l’étude et à partir de 10 variables prédictives. Ainsi, à partir de ces 10 variables calculées sur l’année N, notre modèle doit être capable de prédire pour chaque patient le niveau de progression de la maladie (valeur quantitative) à l’année N+1.
Il s’agit d’une problématique de prédictions sur des données structurées (table) : nous allons donc utiliser Azure Machine Learning Automatisé.
Les données
Il s’agit du jeu de données publiques Diabetes, de la librairie Azureml qui contient nos 10 variables de départ : l’âge du patient, son sexe, son indice de masse corporelle, sa pression sanguine moyenne et 6 mesures de sérum sanguin.
Ces 10 variables ont été obtenues pour chaque patient diabétique. Ce jeu de données contient 442 observations, c’est-à-dire 442 patients diabétiques. (Se reporter à la documentation du jeu de données, pour plus d’informations).
Objectif du modèle : il s’agit de résoudre un problème de régression.
Le modèle doit être capable de prédire une mesure quantitative qui représente la progression chiffrée de la maladie pour chacun des patients diabétiques, un an après le début de l’étude.
Etapes clés de mise en œuvre de ML Automatisé
- Configuration d’Azure Machine Learning Studio (image 1)
- Création de l’instance ML automatisé (image 2)
- Prototypage de l’expérience ML automatisé jusqu’à son déploiement (images de 3 à 13)
Début du tutorial détaillé
Vous devez impérativement, avant de lancer ML Automatisé, comprendre à quelle problématique business vous avez à faire. Vous devez préparer vos données en amont et comprendre ce que vous cherchez à résoudre comme problème data. En effet, ML automatisé ne pourra résoudre ces points à votre place
1. Microsoft Azure Machine Learning Studio
Avant de débuter notre projet, vous devez créer sur Azure ML votre propre espace de travail et choisir votre abonnement. Dans notre cas, nous utilisons l’abonnement gratuit proposé par Azure (Plus de détails disponible sur ce site). Une fois que cela est fait, vous pouvez ouvrir Azure ML Studio. Comme détaillé ci-dessus, plusieurs outils sont proposés pour créer votre propre cycle ML. Nous choisissons ML automatisé pour notre démonstration.
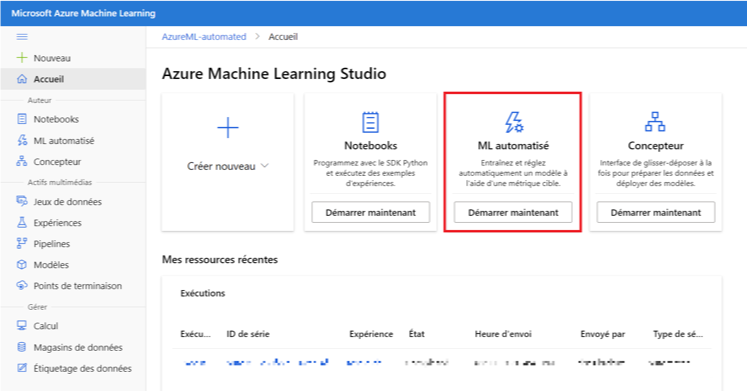
Image 1 : Choix de l’outil ML automatisé
2. Création d’une instance ML automatisé
Nous commençons par créer une nouvelle instance de ML automatisé. Nous pouvons remarquer qu’Azure nous accompagne dans la prise en main de l’outil en nous suggérant notamment la documentation adaptée ou en nous proposant de faire des tutoriaux pour apprendre à réaliser des tâches spécifiques.
Ces tutoriaux pour faire vos premiers pas avec l’outil sont une aide précieuse que nous vous recommandons.
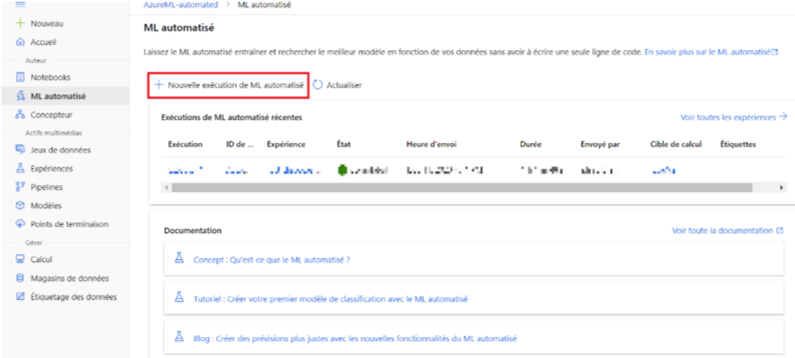
Image 2 : Création de l’instance ML automatisé
3. Choix du jeu de données
L’exécution de l’instance débute par la création du jeu de données. Différentes sources de données sont proposées. Pour notre cas d’étude, nous prendrons le jeu de données public Diabetes disponible depuis la librairie d’Azure.
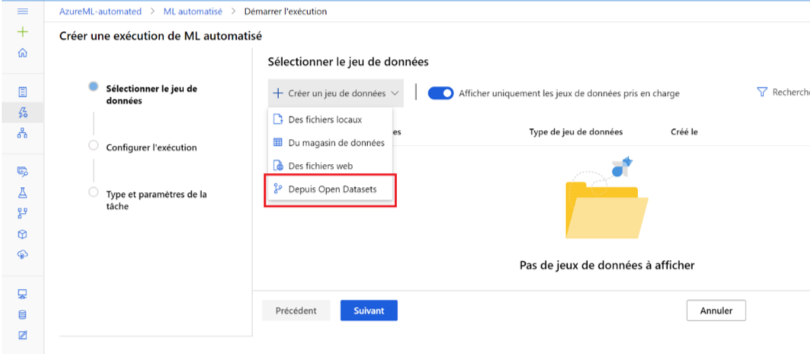
Image 3 : Choix du jeu de données
4. Configuration de l’exécution de l’expérience
Une fois le jeu de données sélectionné, nous devons configurer l’exécution en créant une nouvelle expérience ou en sélectionnant une expérience existante.
Remarque : Si vous souhaitez entraîner plusieurs fois le jeu de données avec des modèles différents, il sera préférable de sélectionner la même expérience.
Dans notre cas, nous créons une nouvelle expérience en lui attribuant son nom et la variable cible de notre modèle. Il s’agit de la variable à prédire, la variable quantitative qui nous informera à quel point la maladie a évolué en un an. Enfin, nous devons choisir un ensemble de machines (ou cluster) de calcul. Il est impératif de bien choisir la puissance de la machine en fonction de notre besoin. Nous cliquons sur « Créer une capacité de calcul ».
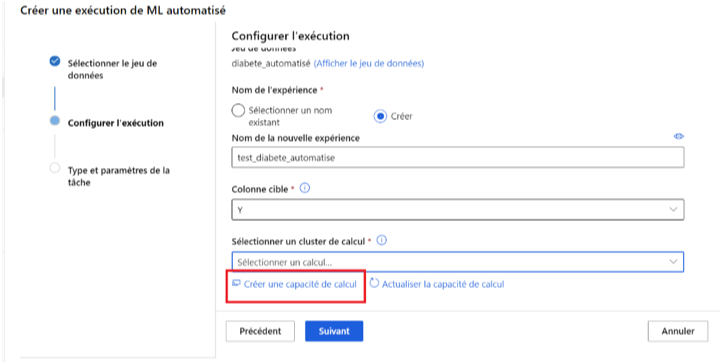
Image 4 : configuration de l’exécution
5. Configuration des paramètres de cluster de calcul
En première partie de la configuration du cluster, nous choisissons le type de machine virtuelle, optimisée CPU dans notre cas d’étude c’est-à-dire « Processeur » (et non GPU). En effet, ce type de machine virtuelle est optimisé pour exécuter un grand nombre de tâches séquentielles et sera adapté pour construire un modèle ML à partir de nos données.
Nous adoptons donc la machine « Standard_D11_v2 » pour notre cas d’utilisation.
En seconde partie de la configuration du cluster, nous définissons les règles dites d’Autoscaling du cluster : le nombre minimal de nœuds est à choisir ainsi que le nombre maximal de nœuds.
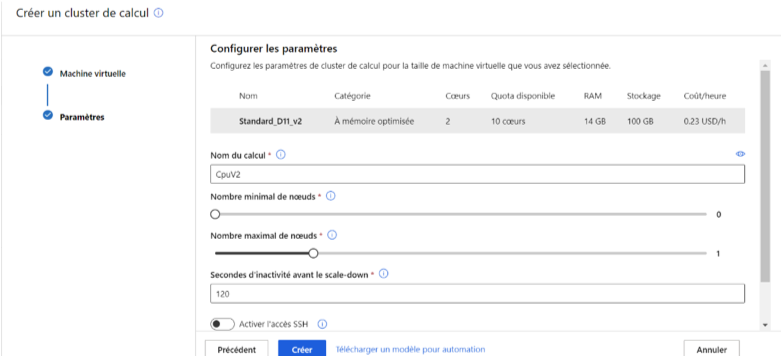
Image 5 : Configuration du cluster de calcul
6. Choix du type du problème
Après avoir sélectionner le jeu de données et configurer l’exécution, nous sommes à la dernière étape avant de lancer l’automatisation de l’expérience Quel type et quels paramètres de la tâche faut-il configurer ?
Nous devons choisir le type de problème que nous voulons résoudre. ML Automatisé en propose trois :
- Classification
- Régression
- Prévisions de série chronologique
Nous sommes face à un problème de régression car il s’agit de prédire des valeurs numériques et continues.
Ensuite nous verrons les paramètres de configuration supplémentaires et les paramètres de caractérisation. Ces deux étapes (7 et 8) sont facultatives mais importantes car elles permettent de mieux contrôler le déroulement de notre expérience.
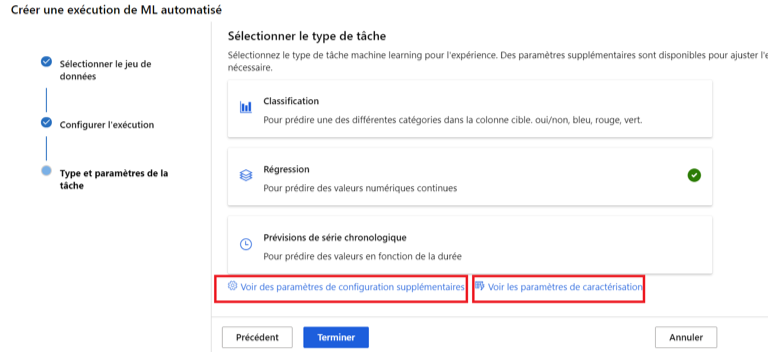
Image 6 : Choix du type de problème
7. Configurations supplémentaires
ML Automatisé nous propose plusieurs métriques selon notre type de problème (régression, classification, séries chronologiques).
Nous choisissons l’erreur quadratique moyenne normalisée qui est une métrique de performance adaptée à notre modèle de régression.
Il est très important de choisir la bonne métrique à optimiser selon votre cas d’étude.
Ensuite nous pouvons choisir de ne pas utiliser certains algorithmes durant l’entraînement. Cette possibilité est à considérer avec précaution. En effet si vous n’êtes pas certain de votre choix de modèles, vous pouvez laisser cette option vide.
Enfin comme critère de sortie, nous avons le choix entre définir le nombre d’heures d’entraînement et/ou définir un seuil de score de performance à atteindre. Au vu de notre jeu de données, 1H d’entrainement devrait suffire pour obtenir de bons résultats.
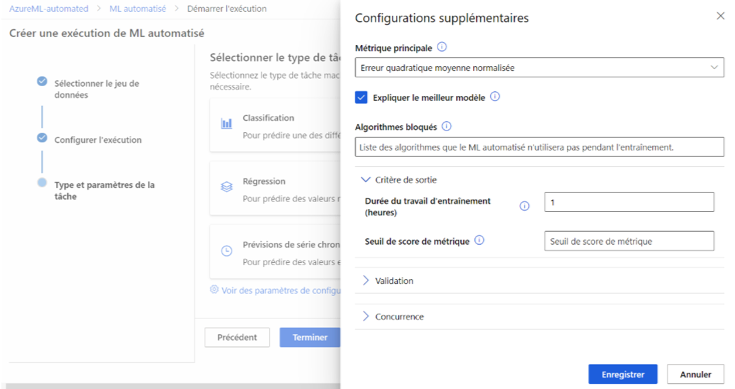
Image 7 : Configurations supplémentaires
8. Paramètres de caractérisations
La caractérisation représente la dernière étape avant de lancer l’automatisation. Azure ML Automatisé nous offres plusieurs possibilités :
- Inclure/Exclure une variable
- Choisir le type d’une variable
- Traiter les variables manquantes
Certaines variables ne sont pas utiles pendant la phase d’entrainement mais elles permettent de mieux expliquer les résultats du modèle. Nous pouvons donc les exclure avant de lancer l’entrainement.
Concernant le choix du typage des variables, Azure ML Automatisé peut se tromper sur le type. Ce qui est normal car personne ne connait mieux votre jeu de données que vous, pas même ML Automatisé ! Il est donc préférable de ne pas laisser en « Automatique » la configuration du typage des variables.
Enfin, nous avons aussi la possibilité de définir la manière de traiter les variables manquantes par imputation (avec la moyenne, la médiane, la valeur la plus fréquente, etc).
Une fois ce paramétrage fini, l’entrainement est lancé. Il ne vous restera plus qu’à patienter.
Remarque : Ces changements seront naturellement pris en compte pour l’entrainement.
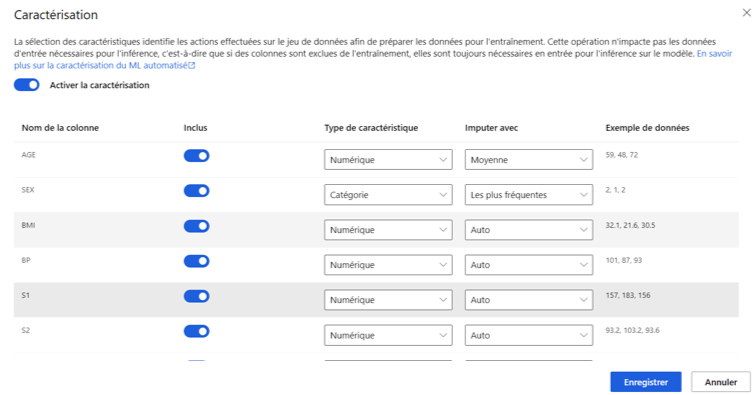
Image 8 : Caractérisation
9. Résultat de l’exécution
L’entraînement est terminé. ML Automatisé nous propose le détail du meilleur modèle, c’est-à-dire celui qui a obtenu les meilleures performances. Dans notre exemple, notre modèle obtient un très bon score RMSE=0.16. Le modèle retenu se nomme « VotingEnsemble ». Il est à noter que ML Automatisé prend en charge des méthodes ensemblistes de vote et d’empilement de modèles (Se référer à la documentation pour plus de détails).
Remarque : Notons que l’entraînement de l’ensemble de l’exécution inclut plusieurs étapes :
- pre-processing des données
- transformations de données
- le choix du/des modèle(s)
- les hyper paramètres à optimiser pour chaque modèle
- Les modèles retenus
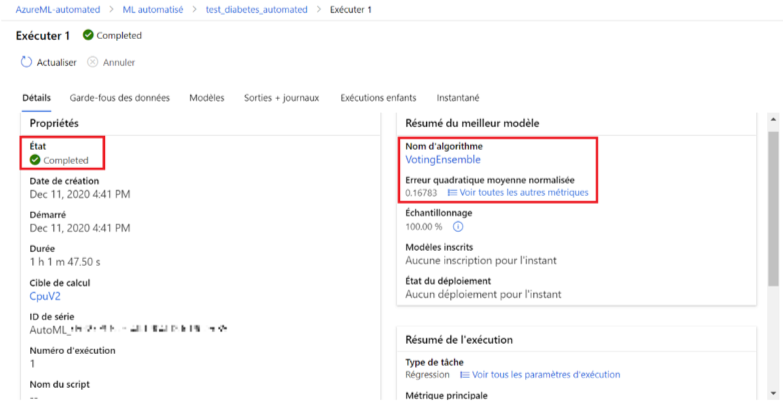
Image 9 : Résultat du modèle
Nous pouvons constater dans l’onglet « Modèles » qu’une multitude de modèles ont été générés. Il n’y a pas de concept de modèle final, vous choisissez le modèle le plus adapté à votre besoin. Nous en parlerons dans la section du déploiement.
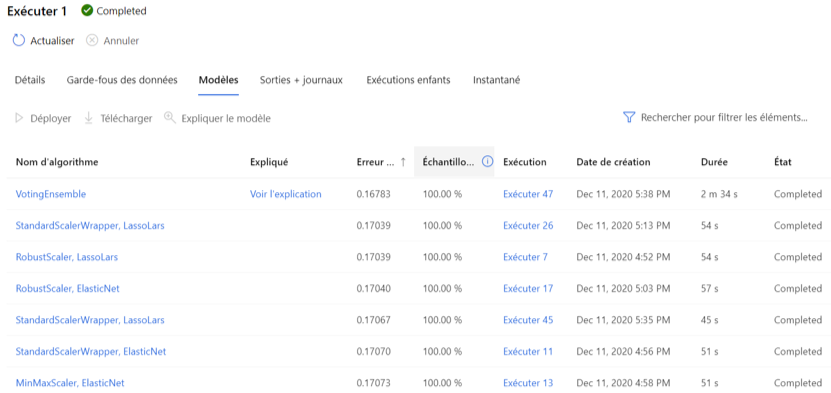
Image 10 : Ensemble de modèle générés
Pour plus de détails, nous avons accès à l’architecture du modèle de notre choix.
Remarque : Pour obtenir le visuel ci-dessous, vous devez cliquer sur le modèle que vous voulez puis allez dans l’onglet « Détails ». En bas de la page vous trouverez « JSON brut ».
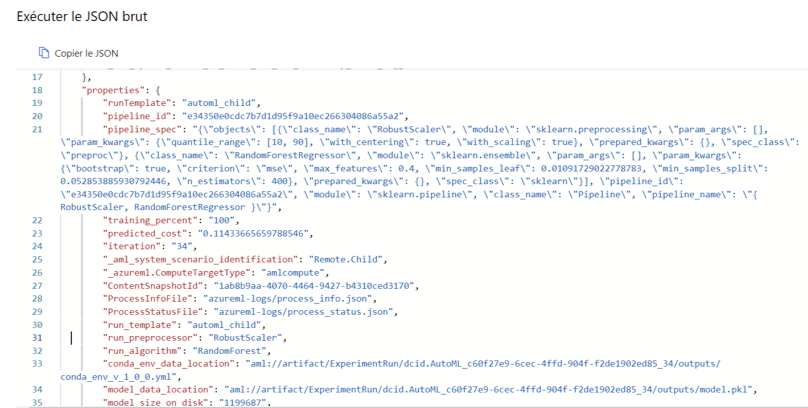
Image 11 : Architecture d’un modèle
10. Explication des prédictions
Il est toujours important de trouver une explication claire quant à des prédictions issues de modèles ML. C’est pourquoi ML Automatisé met à votre disposition deux niveaux d’explications des prédictions :
- Le premier niveau est général : L’importance des variables sur l’ensemble des prédictions vous est communiquée, comme nous pouvons le voir dans l’image qui suit :
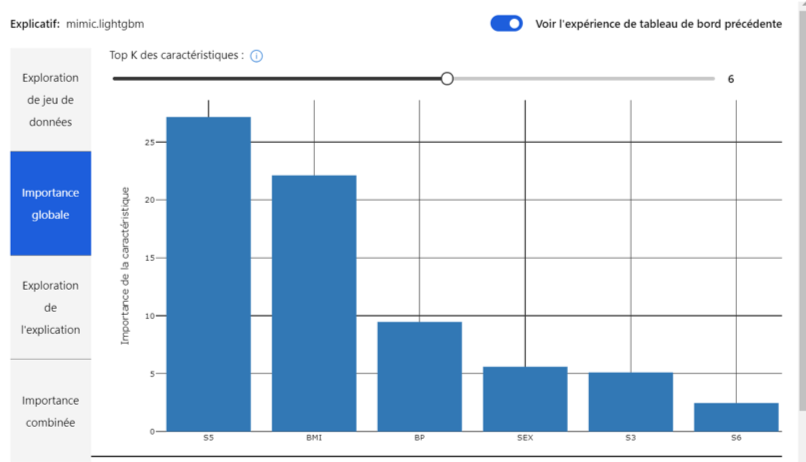
Image 12 : Importance globale
Ici nous constatons que la cinquième mesure de sérum sanguin impacte le plus la variable à prédire (au global).
Remarque : Pour obtenir le visuel ci-dessus vous devez cliquer sur un modèle puis allez dans l’onglet « Explications (préversion) » puis Importance globale.
- Le second niveau est plus précis :
L’importance des variables pour chaque ligne de prédictions est communiquée. Il s’agit donc de l’impact ou le poids de chaque variable sur chaque prédiction :
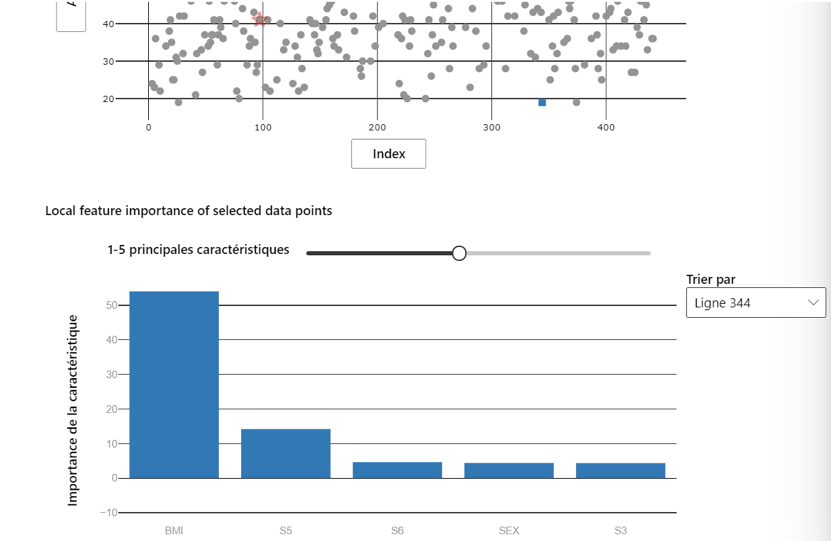
Image 13 : Importance locale
Ici nous constatons que pour cette personne diabétique en particulier, c’est l’indice de masse corporelle qui influence le plus le résultat de la prédiction.
Remarque : Pour obtenir le visuel ci-dessus vous devez cliquer sur un modèle puis allez dans l’onglet « Individual feature importance » puis Importance globale.
ML Automatisé met aussi à disposition d’autres visualisations pour explorer le jeu de données et avoir une meilleure compréhension de ce dernier.
11. Déploiement du « meilleur » modèle
Une fois tous les modèles obtenus, il faut sélectionner celui qui sera déployé. Nous pouvons choisir celui qui est recommandé par ML Automatisé mais s’agit-il du meilleur choix ? En effet avant de choisir son modèle, il faut d’abord se demander si ce modèle répond à notre problématique. Par exemple si notre modèle doit être utilisé sur un téléphone, nous préférerons un modèle plus léger en termes de poids même s’il possède de moins bonnes performances que celui qui est optimale mais très lourd.
12. Les coûts engendrés par Azure ML Automatisé
Il existe un coût pour l’utilisation de l’ensemble de la démarche. Dans un premier temps Azure ML Studio est gratuit, cependant les clients paient les coûts associés aux ressources Azure consommées comme les coûts de calcul et de stockage.
Dans un second temps, lorsque nous utilisons une machine virtuelle avec 64 GB de mémoire et 16vCPU (Usage normal & Région Europe & Instance B16MS), cela coute 0.768$ l’heure d’utilisation quel que soit la tâche effectué (traitement, entrainement, déploiement). Nous pouvons baisser ce prix en réservant la machine pendant un an, ainsi le prix sera de 0.45$ l’heure ou effectuer une réservation pendant trois ans avec un prix de 0.29$ l’heure.
Par exemple, si nous déployons notre modèle avec une machine comme celle décrite au-dessus (sans réservation) pendant 1 mois, le prix à payer sera de (1 machine * 0.768$) * (24 * 30) = 552.96$
Autre exemple, si nous entrainons un modèle pendant 10 heures à l’aide d’une machine comme celle décrite au-dessus, le prix sera de (1 machine * 0.768$) * 10 heures = 7.68$.
Ces exemples concrets vous montrent combien il est important de choisir l’instance la plus adaptée à votre cas d’usage.
A noter également, que les prix sont donnés à titre indicatif : ils varient légèrement selon d’autres paramètres comme la région où se situe l’instance, le moment où l’instance fonctionne dans la journée, ect)
Conclusion
Azure Machine Learning Automatisé est la solution parfaite pour vous si vous souhaitez développer un modèle ML mais que vous n’êtes pas un data scientist ou un data engineer. L’utilisateur possède à la fin de l’exécution une bonne compréhension des résultats obtenus tant grâce à la transparence des modèles générés que grâce aux explications des prédictions.
Les différentes visualisations faites par cet outil ont une réelle plus-value durant la restitution des résultats.
N’oubliez pas qu’Azure ML automatisé n’est pas responsable de la qualité du jeu de données en entrée, c’est à vous de l’enrichir avec des indicateurs pertinents pour répondre à votre problématique business. Une fois que votre jeu de données d’entrée est prêt à l’emploi, les bénéfices à utiliser Azure ML automatisé sont nombreux.
Pour plus de détails sur les points abordés durant cet article, nous vous invitons à consulter les liens suivants :
- Azure Machine Learning : https://azure.microsoft.com/fr-fr/services/machine-learning/
- Azure ML Automatisé : https://azure.microsoft.com/fr-fr/services/machine-learning/automatedml/
Si vous n’avez encore lu les deux premiers articles de la série :

