
On vit dans une ère où la génération massive de données par les SI est devenue la norme. Lorsqu’elles sont bien exploitées, ces données peuvent aider les entreprises à évoluer et optimiser l’expérience de leurs clients. Pour en tirer le maximum il faut bien savoir quel type de traitement à préconiser. Il doit être en mesure de garantir la complétude ainsi que la fiabilité de l’information tirée.
Plusieurs architectures sont utilisées pour le traitement massif des données. Ces architectures peuvent être divisées en deux catégories :
1. Architectures Traditionnelles
- Lambda
C’est l’architecture la plus connue dans le monde de Big Data, elle combine le traitement en temps réel avec le traitement par lots tout en séparant les 2 pipelines. Le mode d’écriture supporté par cette architecture est « append-only » et donc pas d’écrasement de données (Overwrite). Les données sont « immutables » et sont ordonnées implicitement par le temps d’arrivée (en utilisant le timestamp)
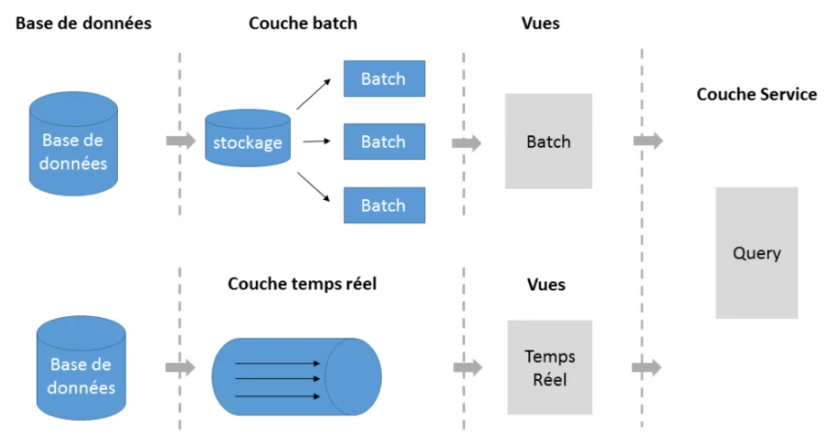
Figure 1 : Architecture Lambda
Elle est composée de 3 couches :
- Couche dite ‘Speed Layer’ (temps réel)
- Elle a pour but de minimiser le temps de latence
- Les données traitées ne sont pas bornées
- Les résultats de ce traitement ne sont pas forcément précis et aucune correction n’est possible
- Les données issues de cette couche sont généralement stockées dans des bases NoSQL
=> Cette couche sacrifie la précision aux dépens du temps de latence
- Couche ‘Batch’ (pour le traitement par lots)
- Sauvegarde les données avant de lancer les traitements
- Traitement régulier mais pas fréquent
- Les données traitées sont bornées
- Fournit des vues complètes et précises grâce au fait qu’elle dispose d’une vue globale sur l’ensemble de données
- La correction et recalcul sont désormais possibles
=> Cette couche sacrifie le temps de latence pour garantir une bonne précision
- Couche dite ‘Serving Layer’ :
- Expose les vues issues des deux couches citées précédemment aux utilisateurs
- Fournit des vues précalculées et est capable d’en générer d’autres à partir des données déjà traitées
- Architecture Kappa
A été introduite comme une solution alternative à Lambda vu la simplicité de sa mise en œuvre.
Elle cherche à fusionner les deux couche Stream Layer et Batch Layer en une seule couche capable de faire des traitements dites proches du temps réel (Near Real Time Processing). Cette couche permet de stocker les données temporairement (donc pas de stockage permanent). Généralement on utilise les ‘messaging queues’ (ex : Apache Kafka) pour le stockage. Le plus grand avantage de Kappa par rapport à Lambda c’est le fait qu’avec une seule application on peut réaliser les deux types de traitements, ce qui n’est pas les cas dans Lambda où les deux couches sont découplées et chacune est lancée par sa propre application.
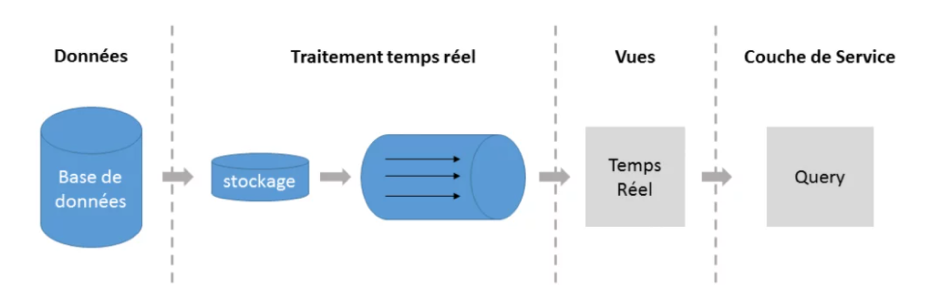
Figure 2 : Architecture Kappa
2. Architecture moderne : L’architecture Delta
D’une manière générale, le terme Delta exprime un changement incrémental. Dans le monde de la Data, un changement incrémental c’est la différence entre deux états des données après avoir subi une opération de création/modification.
L’architecture Delta est une amélioration significative de Lambda avec une inspiration de Kappa. Elle utilise un pipeline unifié pour les chaines temps réel et Batch ; et un système de stockage partagé (le Delta Lake) tout en ajoutant la capacité de faire des transactions dites ‘ACID compliant’.
Les données ne sont plus immutables et chaque entrée en streaming est considérée comme un ‘delta’
Cette architecture se base sur 3 catégories de tables :
Bronze Tables : Ce sont les tables créées depuis les données brutes issues des différentes sources de données (Systèmes IoT, fichiers CSV/Json, RDBMS (Relational DataBase Management Systems) etc…).
Silver Tables : C’est une version plus raffinée et « clean » des données. A ce stade, on peut faire des jointures entre des tables Bronze et les données générées par la chaine temps réel.
Gold Tables : Ces tables sont utilisables par les équipes métiers pour les interroger et générer des rapports et Dashboards.
La figure suivante illustre cette architecture :
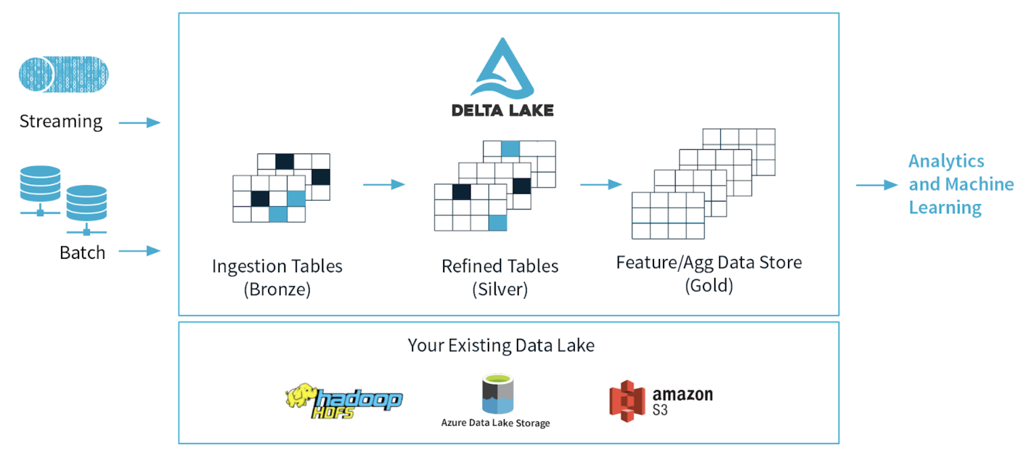
Figure 3 : Architecture Delta
En utilisant Databricks on peut illustrer cette architecture comme suit :
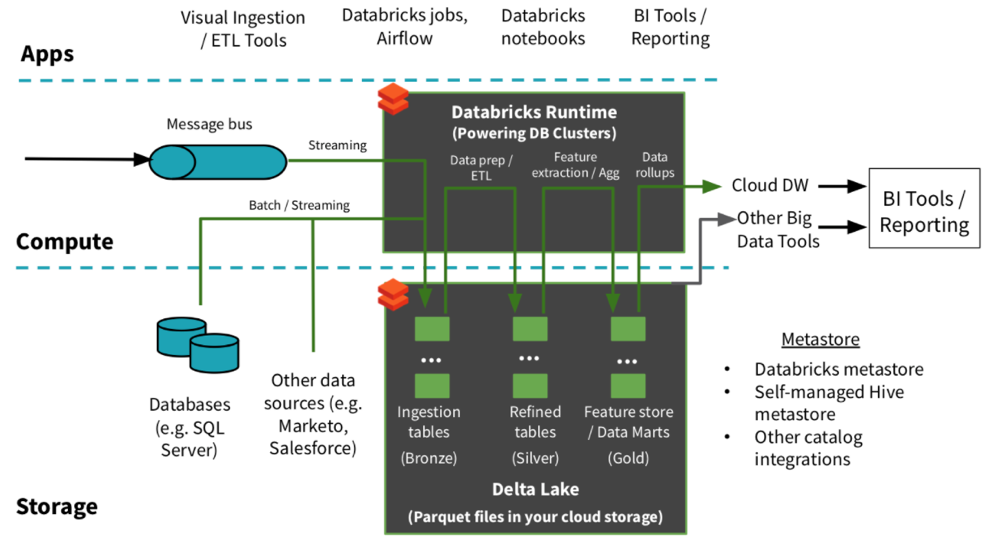
Figure 4 : Architecture Delta avec Databricks
3. Exemple de création d’un pipeline Delta
Les données utilisées pour cette démo ont été récupérées de Kaggle (https://www.kaggle.com/gpreda/covid-world-vaccination-progress) et ont subi des modifications pour des besoins de simplifications. Elles contiennent des informations sur le progrès de la campagne de vaccination dans le monde entier.
On commence par définir le schéma des données utilisées comme suit :

Et les variables qu’on va utiliser. Il s’agit des différents chemins des dossiers qu’on va alimenter :

a. Chaine Batch
- Dans cette première partie on va lancer un traitement par lots et on va sauvegarder le résultat au format Delta. On s’arrêtera au niveau des Bronze Tables sans lancer la suite de traitements pour la construction des Silver et Gold tables pour des fins de simplicité :

b. Chaine Streaming
- Durant cette deuxième partie, on va lancer la chaine Streaming en entier pour construire les tables des différents niveaux (Bronze/Silver/Gold). Dans un premier temps, on commence par la lecture des fichiers sources de type .csv en mode streaming en ingérant un seul fichier à la fois :

- On sauvegarde l’output sous format Delta dans un dossier qu’on va utiliser après afin de créer la table externe pour les Bronze Tables. Il est à noter que c’est le même dossier qu’on a utilisé dans la chaine Batch. Petit rappel : une table externe c’est une table dans laquelle les données ne sont pas sauvegardées dans la base de données. Elles sont sauvegardées dans des fichiers externes et référencés ensuite lors de la création de la Table.

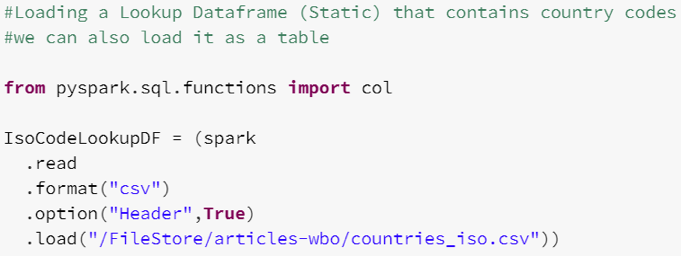
- On crée un Dataframe (collection de donnée distribuée qui organise les données sous forme de lignes/colonnes) à partir d’un fichier contenant les ISO Codes des pays afin de faire la jointure après :
- On crée ensuite un autre Dataframe présentant les Silver Tables en faisant la jointure entre les tables bronze avec la table statique qu’on a chargé précédemment en utilisant le champs « iso_code » comme clef de jointure et en supprimant les lignes contenant des valeurs nulles :

- On écrit le résultat dans le dossier référencié par le Silver Table :

- On fait l’écriture en streaming des résultats des agrégations effectuées sur les Silver Tables dans le dossier représentant les Gold Tables. Il s’agit d’un comptage de nombre de personnes vaccinées par pays :

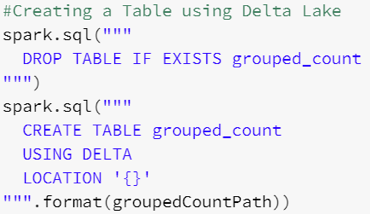
- On crée une table à partir du dossier externe de la Gold Table stockée au format Delta :
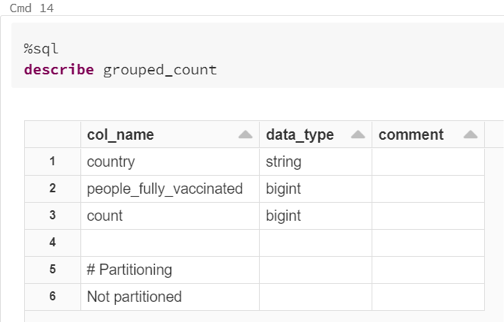
- Cette table a le schéma suivant :
- On crée les « Materialized Views » : Ce sont des vues matérialisées où les données sont dupliquées

- On lance des requêtes d’interrogation sur ces Vues : il s’agit de la requête SQL suivante qui a pour but de compter le nombre de personnes vaccinées par pays :

Conclusion :
La mise en place d’une telle architecture est désormais possible grâce à l’intégration native de Deltalake et Spark avec Databricks ce qui nous offre une puissance et flexibilité de traitement de données.

