Cet article se décompose en 2 parties :
- Un rappel de l’ évolution des architectures applicatives depuis le début des applications informatiques vers les applications en micro-services (partie 1) en explicitant le pourquoi et les avantages de chaques évolution qui amènent à l’ utilisation de service mesh
- Un volet plus technique (partie 2) qui décrit comment les services mesh sont optimisés pour répondre aux besoins et commodités fonctionnels attendus tout en étant performants sur des applications fortement évolutives en termes d’ utilisateurs et de résilience.
Évolution des architectures applicatives :
Les architectures applicatives évoluent sans cesse, autrefois monolithiques, elles sont devenues orientées services (SOA – Service Oriented Architecture) et aujourd’hui elles se modernisent encore avec la mise en place des architectures micro-service.
Monolithique
Dans une architecture monolithique, tous les composants applicatifs sont compilés, packagés et testés comme une seule instance. Les principaux défauts de cette approche sont :
- Choix d’architecture unique
- Environnement de développement et langages de programmation unique
- Cadence de déploiement par release (Cycle en V ou W)
SOA
Dans une SOA, une application se décompose en plusieurs briques (Front/Middle/Back et Provider/Consumer) qui communiquent entre elles au travers de bus de messages (ESB) via des protocoles réseau, tels que Ethernet/IP.
Les SOA permettent la réutilisation des composants (la contrainte à ne pas négliger est la standardisation des échanges entre les briques lors du développement des briques)
C’est la solution actuellement majoritairement utilisée pour les grands SI des entreprises (en 2022).
Les principaux avantages d’un SOA :
- Réutilisation des briques (composants)
- Architecture scalable et résiliente
- Maintenance plus aisée, car chaque brique peut être maintenue indépendamment
La principale limitation est le bus de message (ESB) qui devient de fait un SPOF (Single Point of Failure) de l’application, en particulier une saturation/panne de ce bus impacte toutes les briques techniques.
Micro-services
Les micro-services représentent la dernière évolution des SOA. Ce ne sont plus des composants techniques réutilisables (et configurables), mais des services à base de containers qui sont créés pour des fonctions applicatives spécifiques aux métiers (moteur de recherche, inventaire, media sociaux, e-commerce, gestion utilisateur, etc …).
Ces services sont indépendants les uns des autres avec des interfaces standardisées de communication (les fameuses API) et peuvent être écrites dans des langages de programmation différents, être développés avec des IDE différents, utiliser des bases de données différentes notamment.
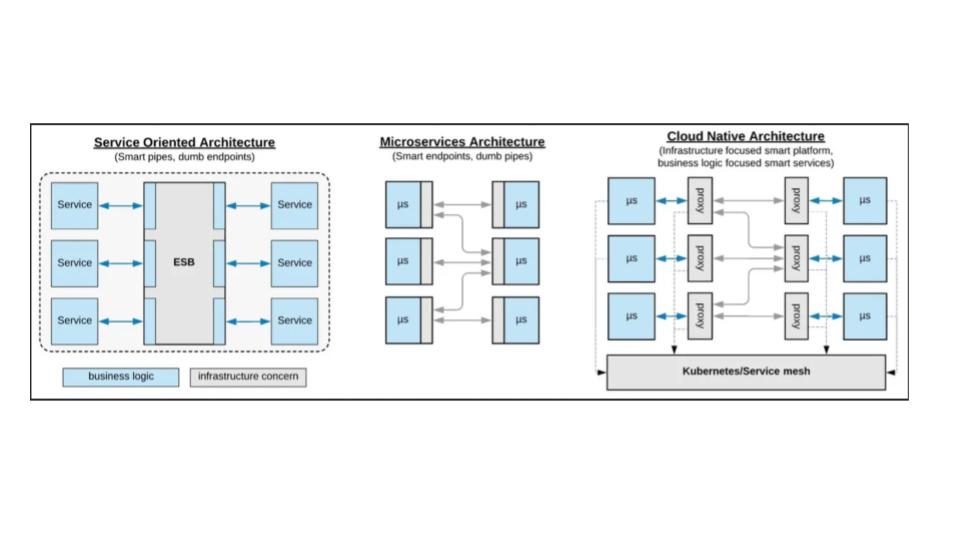
La gestion du réseau et du stockage qui permet la scalabilité et la résilience (gestion des pannes) sont traités de manière totalement différentes des SOA. En particulier la standardisation des protocoles de messages utilisée par les ESB a été poussée encore plus loin avec la mise en place de communication inter-services via des API RESTful.
Cette standardisation permet de définir précisément les opérations possibles entre les différents services : opérations POST/PUT, GET, PUT/POST/PATCH, DELETE
Cette standardisation apporte néanmoins son lot de contraintes et nécessite généralement une refonte des designs applicatifs :
- Indépendance entre le client et le serveur
- Sans gestion de sessions au niveau serveur (stateless)
- Interface uniforme et standard : le serveur expose des ressources et utilise des opérations précises et définies
- Les applications se comportent de la même manière quel que soit les services intermédiaires traversés entre le client et le serveur
En résumé
Les applications en micro-services apportent une réelle valeur ajoutée par rapport aux SOA ou bien évidemment aux architectures monolithiques, en termes de cycle de développement, de maintenance, de montée de version, de gestion des retours arrière, de scalabilité, de résilience, de performance, de facilité de migration sur les clouds publiques (car tout est standardisé) MAIS cela passe souvent par une redéfinition complète de l’application pour supporter cette standardisation.
Pourquoi utiliser un service mesh dans une architecture micro-services ?
Partant du principe que l’avenir est aux applications micro-services, il existe plusieurs moyens de gérer les interconnexions entre les services sous-jacents.
Le socle technique commun de ces services est apporté par les containers et par des nœuds (Machines virtuelles ou physiques) qui portent ces containers.
Sans entrer dans les détails qui dépassent les ambitions de cet article, disons que les containers (et surtout les pods composés de containers) portent des fonctions applicatives avec des interfaces standardisées (voir I.) et c’est leur orchestration par Kubernetes (K8s) et leur interconnexion qui permet de créer des applications.
Pour interconnecter ces services (pods / containers), il est nécessaire de gérer les interfaces réseaux des containers au travers d’un type de plugin : les CNI (Container Network Interface).
Les plus utilisés à ce jour (en 2022) sont : Pile réseau linux native, OVS/OVN (Openshift), Calico, Weave, Flannel.
Les CNI sont utilisés par K8s mais n’en font pas partis : K8s est aussi installé sous forme de containers et utilise les CNI pour sa propre gestion de la connectivité. Ainsi chaque nœud possède un plugin CNI qui est configuré dynamiquement lorsque les pods sont créés par K8s et qu’ils doivent se connecter entre eux (soit au sein du nœud, soit inter-nœud).
La puissance des différents CNI s’expriment au travers de leurs fonctionnalités : support des stratégies/règles réseaux, utilisation de protocoles de routage entre les nœuds, pas d’utilisation de tunnels mais plutôt d’overlay, utilisation d’ eBPF, notamment.
Il est important de bien garder à l’esprit que les réseaux traditionnels (Ethernet/IP) ont été conçus pour permettre la résilience/scalabilité au niveau de l’infrastructure et non au niveau de l’application.
L’augmentation du nombre de connexions accroît de manière géométrique les possibilités de pannes potentielles réseau et, par conséquent, des applications qui l’utilisent, en conséquence, avec le passage des applications monolithiques (quelques connexions réseaux), aux applications type SOA (quelques dizaines de connexions) aux micro-services (plusieurs milliers de connexions en fonction du nombre de pods), la pression sur la fiabilité du réseau s’accroît fortement.
Micro-services et K8s fonctionnent donc ensemble : K8s fournit la répartition de charge, la résilience et la scalabilité mais n’intervient pas dans la gestion de la connectivité entre les différents services/pods.
Pour gérer cette couche complexe et fondamentale sur l’interaction entre les différents services/pods sans s’appuyer sur l’infrastructure et l’expertise réseau, le service mesh est la brique manquante.
Un service mesh est une couche d’infrastructure de faible latence qui apporte une communication fiable, rapide et sécurisée entre les services applicatifs (portés par les pods) utilisant des APIs.
En particulier, les différents défis et complexités qu’il doit adresser sont :
- Multitudes de Endpoint à superviser, sécuriser, gérer la montée en charge
- Vision opérationnelle globale impossible à centraliser
- Audit, conformité, sécurité distribuée et fortement décorrélés entre les services
- Code et librairies applicatives hétéroclites
Le service mesh répond à cette problématique en traitant spécifiquement les points suivants :
- Communication interservices (Pods) : Chiffrement et Découverte des services disponibles
- Reroutage d’un faible pourcentage de requêtes
- Observabilité (au sens SRE) : Traçabilité et supervision
- Vision globale de l’infrastructure qui permet une résolution des incidents/problèmes beaucoup plus efficace
- Résilience : gestion des pannes et rétablissement du service automatique
- Gestion native du Blue/Green et du mode Canary pour tester les montées de version sur un périmètre d’abord restreint (Canary) puis à plus large échelle (Blue/Green)
Il permet de bien séparer la partie applicative pure des services de connexion/MCO (maintien en condition opérationnelle : gestion du trafic réseau, des erreurs et des pannes, récupération des traces et supervision).
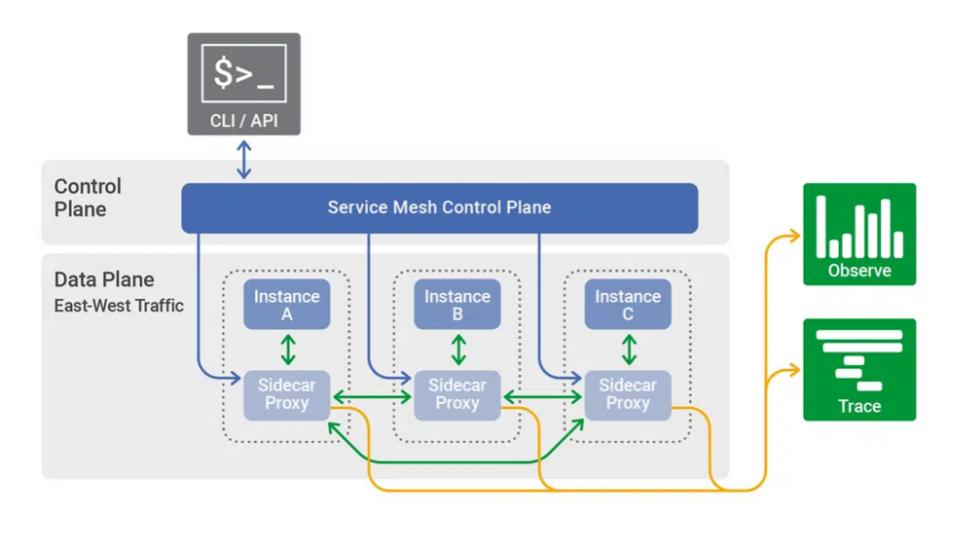
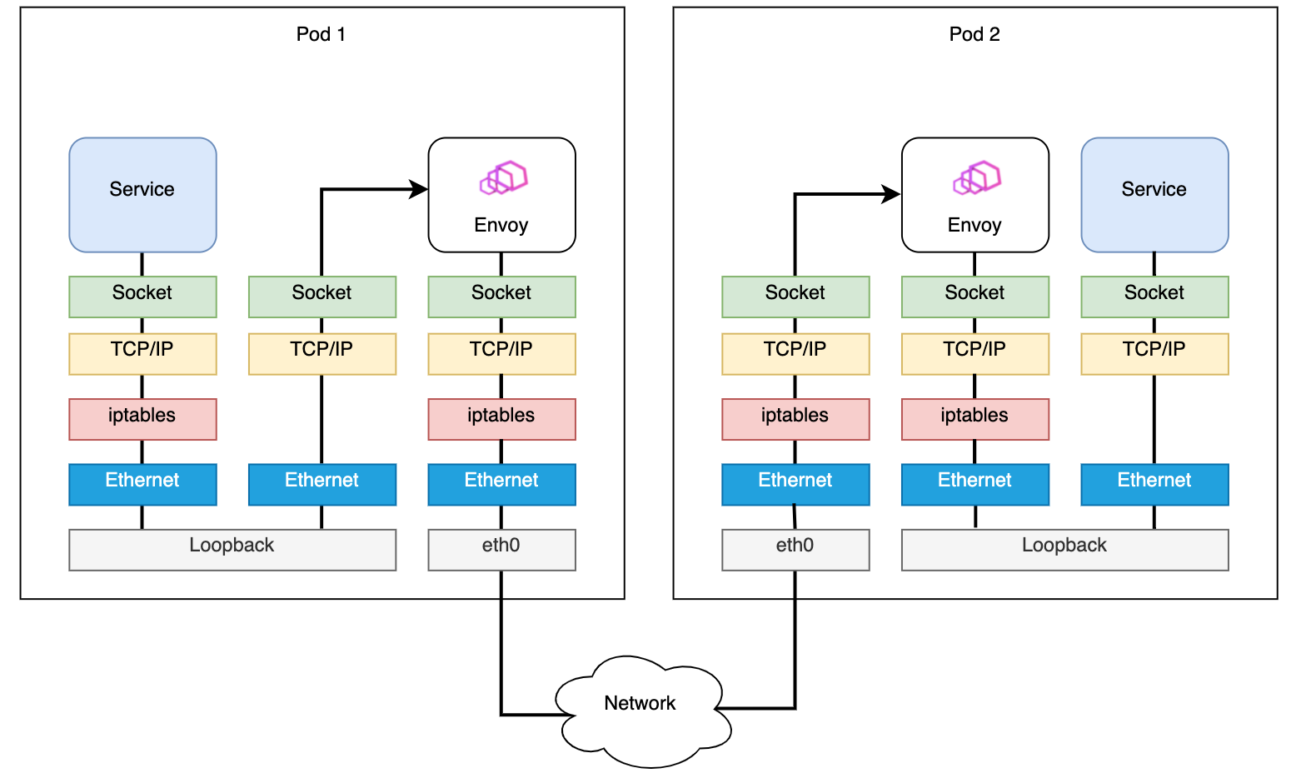
Techniquement son implémentation est souvent réalisée en mode « sidecar » au niveau du pod, toutes ses fonctions non-applicatives sont alors portées dans un container spécifique appelé proxy : c’est le data plane du service mesh
A cela s’ajoute un control plane qui permet de générer et de déployer de manière centralisée les informations de configuration des proxies du data plane.
Le control plane se connecte au data plane via des APIs sécurisées et propose une interface graphique (GUI), un accès en ligne de commande (CLI) et des APIs pour piloter le service mesh (de manière programmatique : via un provider Terraform ou des chart HELM par exemple ou de manière manuelle : GUI /CLI).