
Nous avons vu ensemble dans notre dernier article la solution autoML Tables de Google. Aujourd’hui nous poursuivons cette série d’articles avec la présentation de la solution autoML d’Amazon : Amazon SageMaker Autopilot.
Avant d’approfondir avec vous cette solution et pour bien comprendre le contexte, une brève présentation des services de Machine Learning (ML) d’Amazon s’impose.
Amazon a développé plusieurs services prêt à l’emploi pour lesquels aucune expérience en machine learning n’est exigée. Par exemple, Amazon Textract est un service qui permet d’extraire automatiquement du texte (ou des données à partir de documents numérisés).
Il existe également :
- Amazon Rekognition pour l’analyse d’images et de vidéos à partir de méthodes de deep learning (identification d’objets et de scènes dans des images ou flux vidéos, détection d’anomalies visuelles)
- Amazon Comprehend pour le traitement du langage naturel (compréhension de la nature positive ou négative du message textuel, reconnaissance de la langue, d’un lieu géographique)
- Amazon Polly pour l’analyse de signaux vocaux (robots conversationnels, conversion de signaux audio en texte).
D’autres services existent et permettent de traiter des cas d’usages variés, sans connaissances préalable en machine learning. En contrepartie, Amazon vous facturera l’utilisation des services choisis.
Nous allons nous pencher vers un service différent proposé par Amazon. Il s’agit d’Amazon SageMaker qui permet non pas d’utiliser un service déjà entrainé mais de créer, former et déployer rapidement et facilement soi-même des modèles de machine learning.
Présentation d’Amazon SageMaker
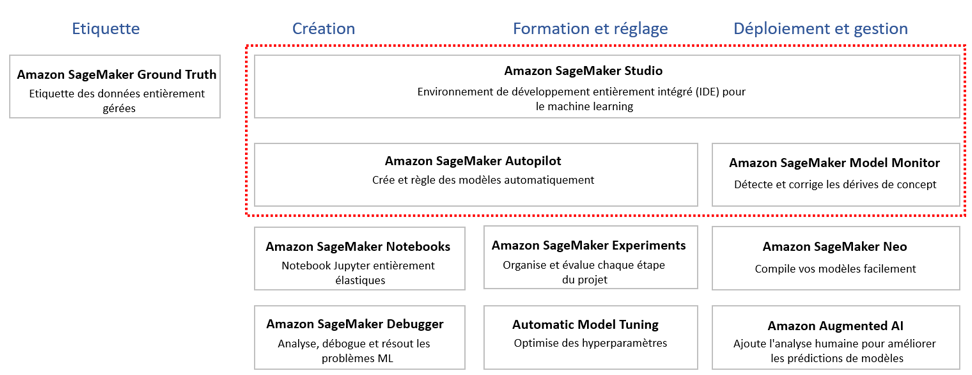
Source : Amazon SageMaker
Amazon SageMaker possède tous les composants pour effectuer un projet ML. Nous allons présenter les composants utiles pour nous aujourd’hui (Cf. Zones encadrées en rouge de l’image ci-dessus) :
- Amazon SageMaker Studio est un environnement de développement entièrement intégré ou IDE qui permet de réaliser tout le cycle d’un projet machine learning. Il fournit une interface visuelle qui permet de gérer les différentes expériences, de créer des modèles automatiquement, et de déboguer. En bref, Amazon SageMaker Studio unifie plusieurs outils en une seule interface.
- Amazon SageMaker Monitor permet de garder une bonne qualité du modèle déployé en détectant des dérives qui se produisent dans le temps entre les données utilisées pour la création du modèle et celles utilisées pour générer des prédictions. Amazon SageMaker Monitor envoi automatiquement des alertes. Cet outil est intégré dans Amazon SageMaker Studio.
- Amazon SageMaker Autopilot permet d’entraîner et de déployer des modèles automatiquement en travaillant sur des données structurées (CSV, txt, Excel) pour résoudre des problèmes de prédictions et de classification, tout en gardant une visibilité et un contrôle complet. Cet outil est aussi intégré dans Amazon SageMaker Studio.
Le cas d’usage qui va suivre sera traité avec Amazon SageMaker Autopilot.
Amazon SageMaker Autopilot
Formulation du problème de machine learning
Notre problème est le suivant : nous devons trouver le meilleur modèle qui est capable de reconnaître des chiffres écrits à la main. A partir d’une image représentée par une matrice de 64 valeurs, ce modèle doit être capable de prédire la valeur du chiffre représenté.
Il s’agit d’une problématique de prédictions sur des données structurées : nous allons donc utiliser Amazon SageMaker Autopilot.
Dans le cadre de cette problématique, nous utiliserons, en supplément pour notre cas d’usage, une base de stockage des données (Amazon Simple Storage Service ou S3).
Les données
Il s’agit du jeu de données publiques de la librairie python Scikit-learn nommé load_digits. Ce dernier contient la description matricielle des 10 premiers chiffres allant de 0 à 9.
Chaque observation représente une image de taille 8×8 qui est décrite par 64 variables explicatives d’entrée. Ce jeu de données contient 1797 observations au total. (Se reporter à la documentation du jeu de données, pour plus d’informations).
Ces données permettent de résoudre un problème de classification multiple.
Objectif du modèle : il doit être capable de classer un chiffre inconnu et prédire s’il s’agit d’un 0, d’un 1, 9 …
A noter que de nombreux cas d’usage peuvent être résolus par Amazon SageMaker Autopilot :
- Prédiction du risque de churn clients
- Prédiction des prix
- Problématique de détection de fraudes au moyen de paiement
- Prédiction de réponses (Y/N) à une proposition commerciale
Etapes clés de mise en œuvre d’Amazon SageMaker Autopilot:
- Création du compte IAM (image 1)
- Export du jeu de données public en fichier CSV vers S3 (image 2)
- Vérification des données dans S3 (image 3)
- Prototypage de l’expérience Autopilot jusqu’à son déploiement (images de 4 à 12)
Ici, le but n’est pas de montrer les performances de SageMaker Autopilot avec des données compliquées. Il s’agit de comprendre les concepts de base de ce service.
Début du tutorial détaillé
Vous devez impérativement, avant de lancer SageMaker Autopilot, comprendre à quelle problématique business vous avez à faire. Vous devez préparer vos données en amont et comprendre ce que vous cherchez à résoudre comme problème data. En effet, SageMaker Autopilot ne pourra résoudre ces points à votre place
1 – Création du compte IAM
Vous êtes sur le point de débuter avec Amazon SageMaker Studio. Il faut d’abord créer un utilisateur et lui attribuer un rôle. Une fois que cela est fait et que le statut de votre compte est prêt, vous pouvez ouvrir Studio.
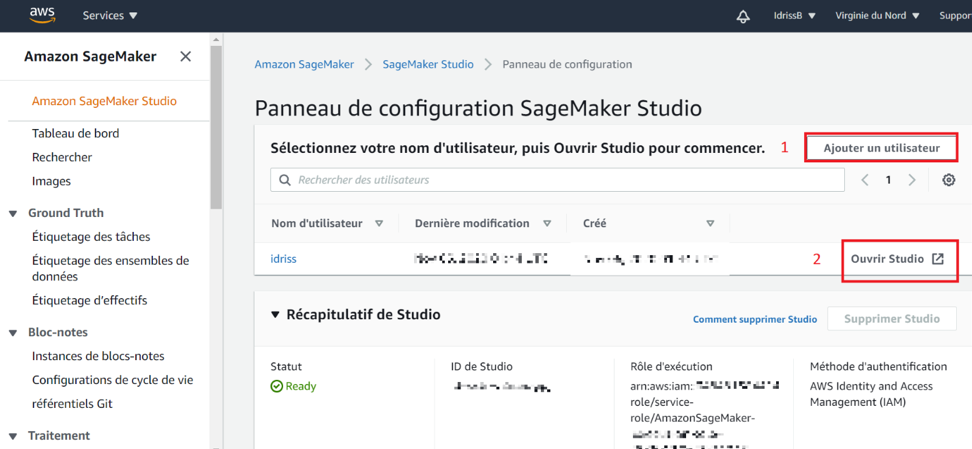
Image 1 : Création de compte
2 – Chargement et export en fichier CSV du jeu de données vers S3
Vous êtes dans Jupyter Lab, allez dans « File » et créez un notebook avec comme Kernel Python3 (Data Science). Ce Kernel (ou noyau) est le plus adapté pour des projets de machine learning.
La première cellule vous permettra de charger les données dans Studio. Après exécution, le fichier « digits.csv » apparait dans l’arborescence du projet. Ici le chemin spécifié est juste « digits.csv » car le notebook sur lequel nous exécutons notre code est hébergé dans Studio.
La deuxième cellule vous permet de charger les données dans S3 qui est le système de stockage d’Amazon. Ce seront les données d’entrées du modèle.
Ici nous avons assigné la variable prefix à « sagemaker/DEMO_purpose » mais vous pouvez choisir l’arborescence que vous voulez.
Remarque : Veuillez copier le chemin obtenu, nous en aurons besoin lorsque l’on créera le modèle.
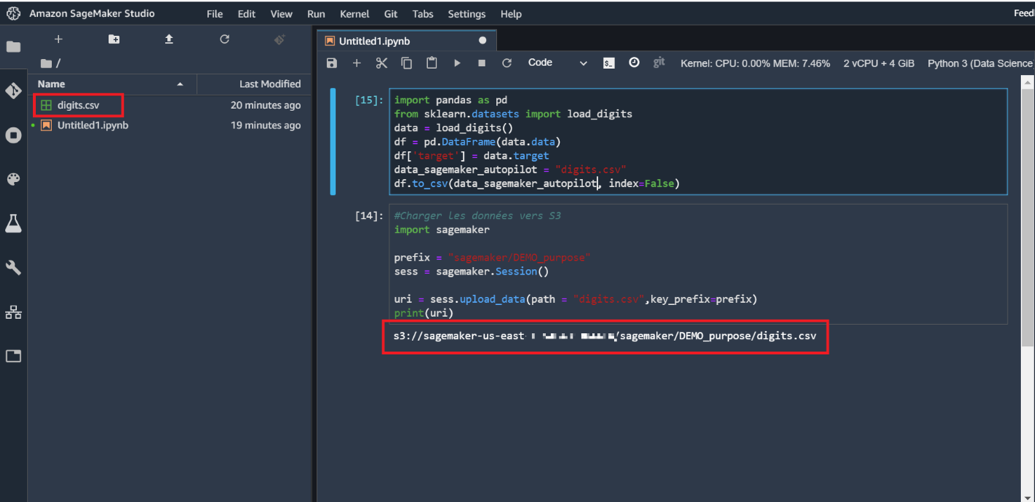
Image 2 : Chargement et export en fichier CSV du jeu de données vers S3
3 – Vérification des données dans S3
Cette étape est optionnelle : elle permet de savoir si les données ont bien été chargées dans le service S3. Pour ce faire, il faut suivre l’arborescence que vous avez créé (ici, « sagemaker/DEMO_purpose ») afin de trouver le fichier CSV comme convenu.
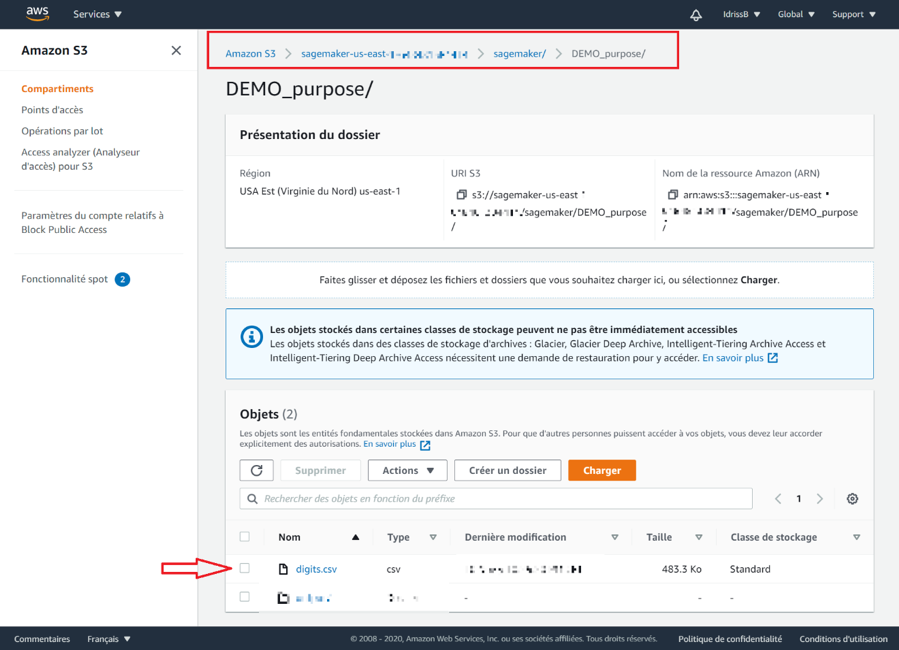
Image 3 : Arborescence des données dans S3
4 – Création de l’expérience
Dans cette étape, beaucoup de choix sont à faire, il faut :
- affecter un nom à cette expérience.
- cliquer sur « Enter S3 bucket location » et coller le chemin que nous avions copié à l’étape 2. C’est le chemin qui indique l’emplacement des données dans S3.
- spécifier la colonne cible, dans notre exemple elle se nomme « target ».
- dans la section Output, mettre le même début de chemin qu’en entrée en terminant par « sagemaker/DEMO_purpose/output ».
Ce dossier « output » contiendra toutes les sorties du modèle :
- Les pre-processing de données
- Les transformations de données
- Les optimisations des hyper paramètres des modèles
- Les notebooks générés
- Les modèles retenus
Nous discuterons de chaque étape par la suite de cet article.
Ensuite nous devons choisir le type de problème que nous voulons résoudre. SageMaker Autopilot en propose quatre :
- Auto
- Classification
- Régression
- Classification multiclasse
Si vous cochez « Auto », vous laissez Autopilot déterminer la nature du problème. Il n’y a aucun problème à cela car Autopilot comprendra assez vite le type de problème. Par contre vous devez faire attention avec ce choix car vous n’aurez pas la possibilité de choisir la métrique à optimiser vu qu’Autopilot l’aura choisi pour vous. Cela peut être problématique si vous avez des données déséquilibrées. Autopilot va automatiquement choisir une métrique qui n’est pas nécessairement la plus adaptée.
Dans notre cas il s’agit d’un problème de classification multiclasse avec comme métrique à optimiser, l’Accuracy. En effet nos données sont bien équilibrées entre les 10 classes.
Enfin nous devons choisir si nous souhaitons aller jusqu’au bout de l’expérience :
- Le choix « Non », nous emmène jusqu’à la suggestion de candidats potentiels. Un candidat potentiel est un pipeline qui combine une étape de pré-traitement des données à une étape de formation de modèle avec un algorithme de machine learning. En d’autres termes, il nous est présenté ce qui aurait pu être utilisé pour l’entrainement des modèles.
Cette option est intéressante car nous pouvons étudier et optimiser ce qu’Autopilot aurait effectué durant les étapes de création de candidats sans pour autant exécuter ces derniers. Vous vous demandez surement comment nous pouvons modifier ces étapes. Nous répondrons à cette question par la suite.
- Sinon le choix « Oui » effectue l’entrainement directement.
Mais, il ne nous donne pas l’opportunité de pouvoir modifier les candidats proposés par Autopilot. Dans notre cas nous voulons exécuter toute l’expérience afin d’observer les choix d’Autopilot.
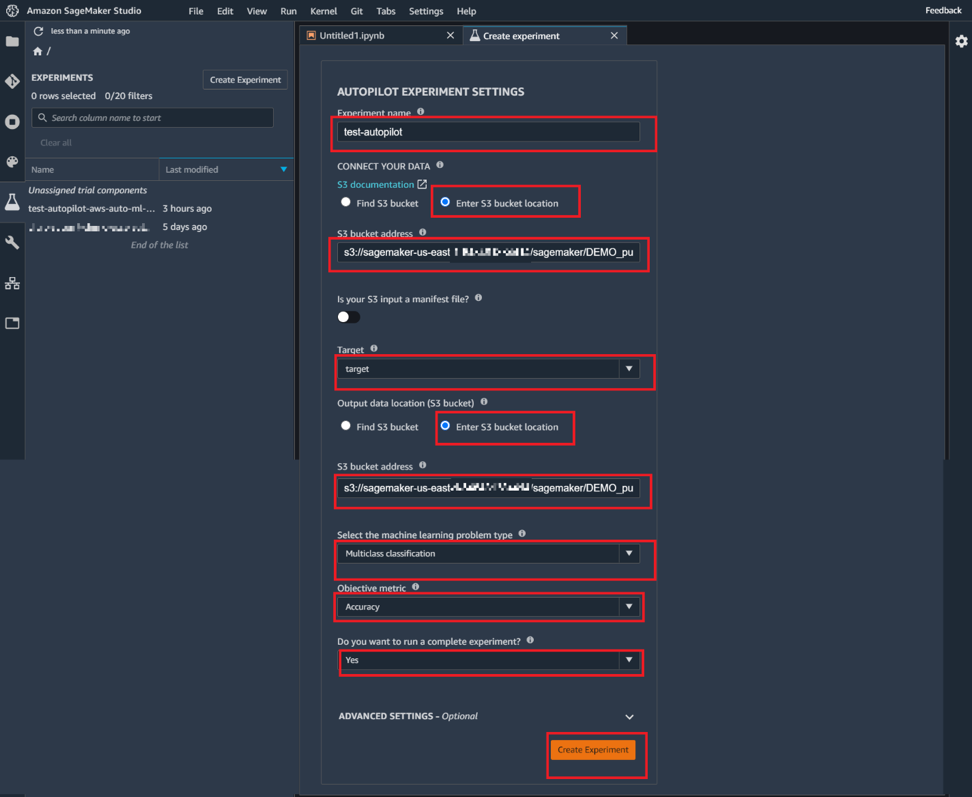
Image 4 : Création de l’expérience
5 – Etape 1 & 2 : Pre-processing & Candidate Définition generated
Après la création de notre expérience, l’interface nous affiche l’ensemble des étapes de l’entrainement des candidats : du « pre-processing » jusqu’au « Model Tuning ».
Durant les étapes de « pre-processing » et « Candidate Définition generated », Autopilot va analyser statistiquement le jeu de données puis rédiger des scripts de pré-traitement, sans oublier la génération de deux notebooks qui reprennent l’ensemble des étapes effectuées par Autopilot.
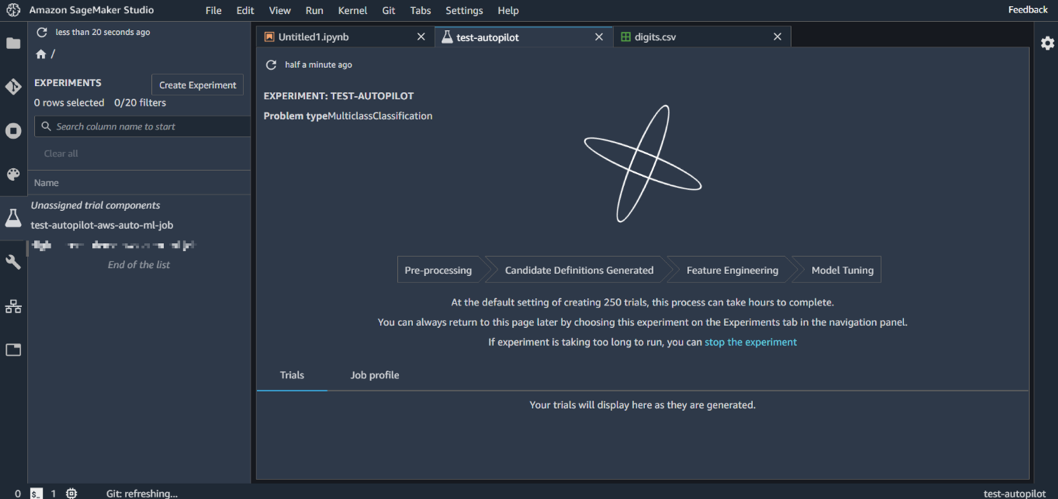
Image 5 : L’ensemble des étapes d’entrainement
C’est là qu’Autopilot aurait mis fin si nous avions coché « Non » lorsqu’il nous a demandé si nous voulons allez au bout de l’expérience (dans le formulaire de création de l’expérience). Vous l’aurez compris, Autopilot n’aurai effectué que ces deux premières étapes.
6 – Feature Engineering
Par la suite, Autopilot passe à l’étape de « Feature Engineering » qui applique des transformations sur les données et trouve les algorithmes qui correspondent au mieux au problème traité, générant ainsi plusieurs candidats.
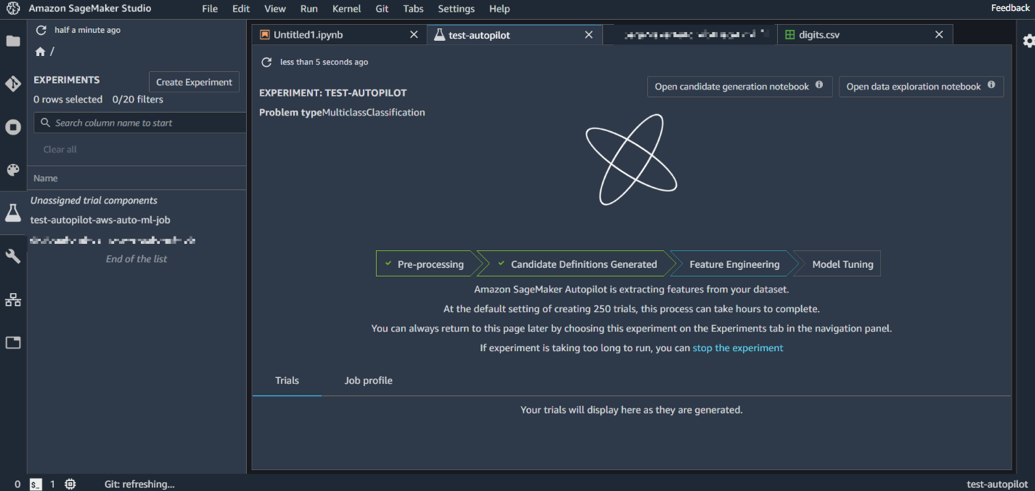
Image 6 : Feature engineering
En attendant que l’exécution soit achevée, nous allons parler des deux notebooks générés à la suite des deux étapes précédentes. Nous allons d’abord détailler celui de l’exploration des données puis celui de la génération des candidats.
Remarque : Ces notebooks sont disponibles sur S3 dans le dossier « output ». Tout ce que l’on va voir à l’intérieur peut être exécuté, il ne s’agit pas de pages HTML.
7 – Exploration des données
Le but de ce notebook est de nous fournir des analyses statistiques sur notre jeu de données. Cette image nous montre que l’outil a identifié le nombre de lignes utilisées pour l’entraînement, le type de problème, la variable cible, et ses valeurs.

Image 7 : Exploration des données
Nous pouvons voir également dans ce notebook quelques analyses pour mieux comprendre notre jeu de données :
- Pourcentage des valeurs manquantes
- Statistiques descriptives
Toutes ces analyses pourraient être faites par un expert de la data. Ici, elles ont été générées automatiquement par Autopilot.
8 – Définition de la génération de candidats
L’exploration des données est utilisée comme base pour nous proposer des candidats potentiels.
Ce second notebook résume toute la démarche faite par Autopilot de la définition des candidats au déploiement d’un modèle.
Tout d’abord il nous montre le script de chaque candidat. Comme celui que l’on peut voir dans l’image ci-dessous. Ici il s’agit du premier candidat qui se nomme « dpp0-xgboost ». Il nous explique les transformations qu’il va effectuer sur les données. Par exemple, il va appliquer la transformation « RobustImputer » sur les variables numériques. Vous pouvez cliquer sur chaque objet pour avoir plus de détails.
Puis, le script décrit la configuration du candidat comme le type d’instance nécessaire, sa taille, l’algorithme choisi, etc.
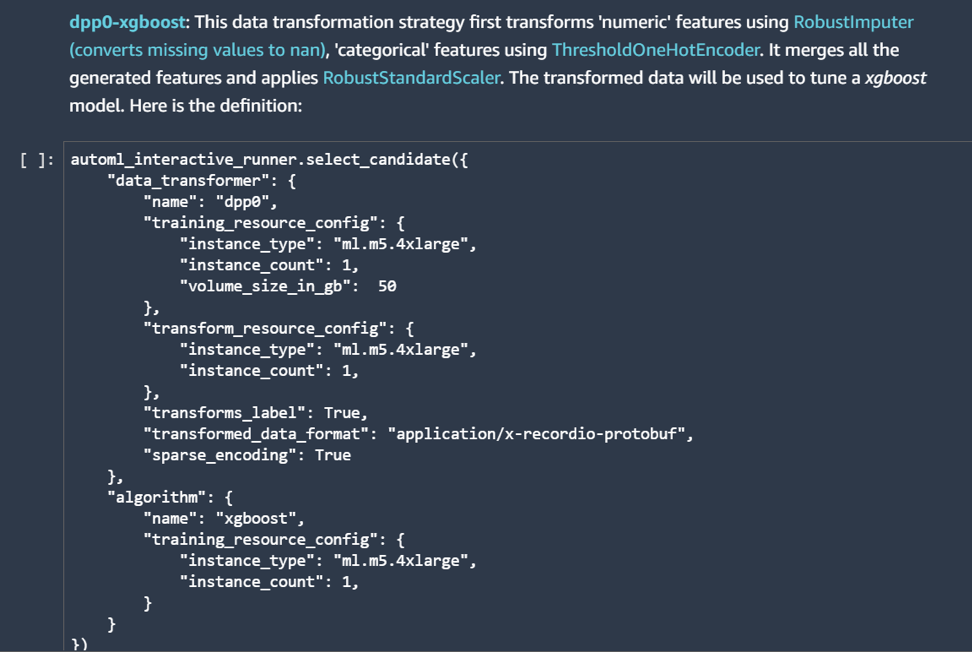
Image 8 : Génération des candidats
Par la suite, nous obtenons des détails sur la manière qu’Autopilot va :
- exécuter ces candidats
- optimiser les hyper paramètres sur chacun d’entre eux
- sélectionner le meilleur modèle et le déployer
Notons que ce notebook n’effectue aucune action. Il explique seulement tout le processus.
Ces deux notebooks auraient pu être ignorés mais si on est un expert de la donnée, on se doit de maitriser le cycle ML proposé pour pouvoir optimiser les choix d’Autopilot à n’importe quelle étape et l’expliquer à son équipe.
9 – Model Tuning
Une fois le process « Feature Engineering » terminé, c’est au tour de la dernière étape « Model Tuning ». Elle se base sur les candidats générés pour tester et trouver les meilleurs hyper paramètres pour obtenir 250 modèles (ou configurations) possibles.
Remarque : Pour obtenir le visuel ci-dessous, vous devez faire un clic droit sur le nom de l’expérience présente sur le menu gauche puis choisir « Open in trial component list »
Cette image a été prise pendant l’exécution de la dernière étape. Autopilot nous montre en temps réel, d’une part les modèles « complété » et d’autre part ceux « en cours » accompagné du résultat obtenu.
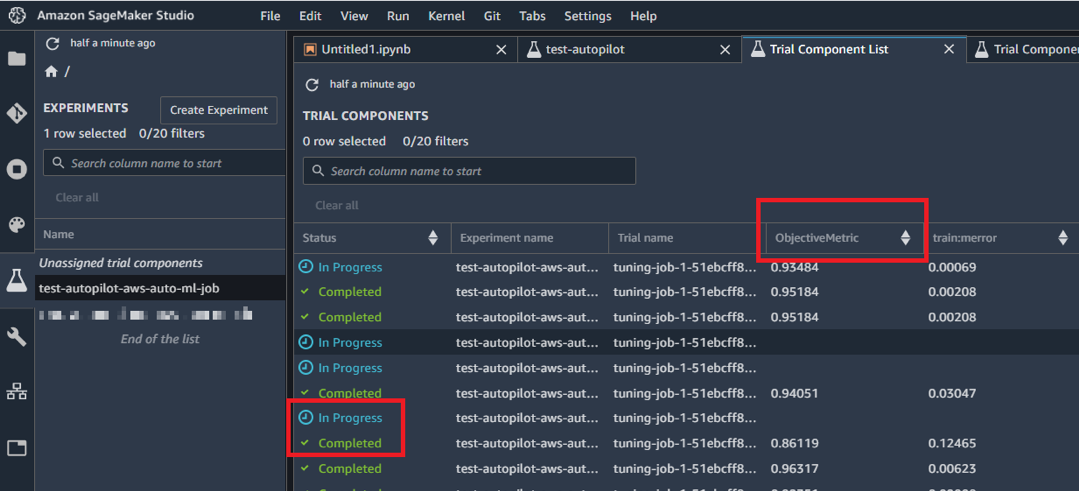
Image 9 : Entrainement en cours
Après un long moment d’attente, tous les modèles sont complétés. Le meilleur modèle obtient un très bon score de 0.985.
Remarque : N’oubliez pas que le dossier « output » dans S3 contient toutes les étapes et les modèles obtenus d’Autopilot.
10 – Architecture d’un modèle
Il faut savoir qu’Autopilot utilise deux algorithmes de machine learning :
- XGBoost (eXtreme Gradient Boosting)
- Apprenant linéaire
Il n’y a pas de concept de modèle final. Autopilot nous propose 250 modèles possibles et c’est à nous de faire un choix.
Remarque : Pour obtenir le visuel ci-dessous, vous devez faire un clic droit sur le nom d’un modèle puis choisir « Open in trial details »
Cette image nous montre le détail d’un modèle donné. Ici dans l’onglet « Parameters », nous avons accès à toutes les valeurs des hyperparamètres du modèle.
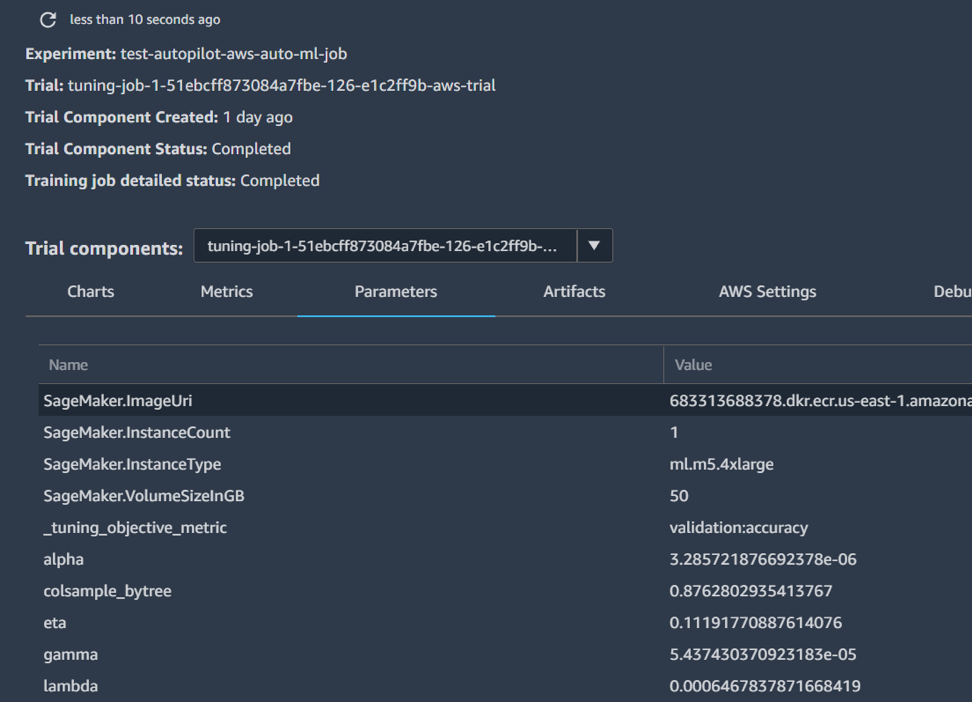
Image 10 : Hyper paramètres du modèle
L’onglet « Metrics », nous montre les scores obtenus pour différentes métriques.
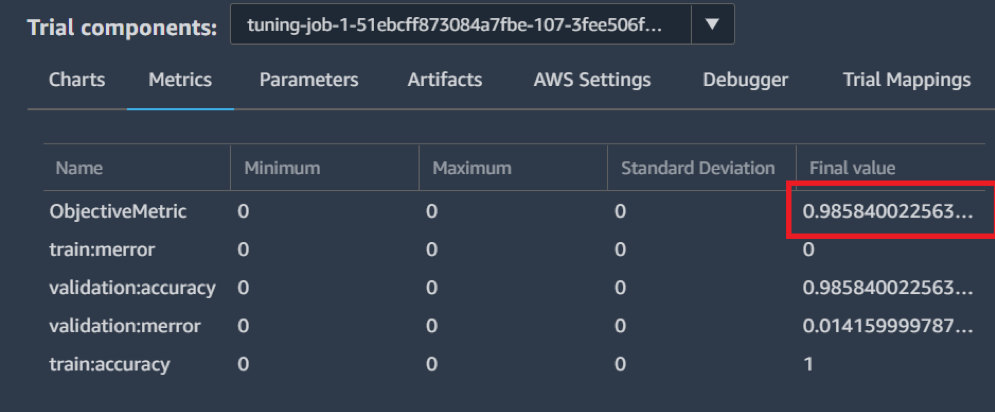
Image 11 : Résultat du modèle
11 – Déploiement du « meilleur » modèle
Une fois tous les modèles obtenus, il faut sélectionner celui qui sera déployé. Nous pouvons choisir celui qui a obtenu la meilleure performance mais s’agit-il du meilleur choix ? En effet avant de choisir son modèle, il faut d’abord se demander si ce modèle répond à notre problématique. Par exemple si notre modèle doit être utilisé sur un téléphone, nous préférerons un modèle plus léger en termes de poids même s’il possède de moins bonnes performances que celui qui est optimale mais très lourd.
Dans notre cas nous voulons déployer le modèle le plus performant car nous n’avons aucune contrainte. Il existe deux types de déploiement :
- prédiction en ligne
- prédiction par lot ou batch
Remarque : Pour obtenir le visuel ci-dessous, vous devez faire un clic droit sur le nom d’un modèle choisi puis « Deploy Model »

Image 12 : Déploiement du modèle
A noter que c’est lors du déploiement du modèle que nous utiliserons Amazon Sagemaker Monitor, en effet il déclenchera automatiquement des alertes si il y’a un décalage entre les données utilisées pour la création du modèle et celles utilisées pour générer des prédictions. La raison pour ce décalage peut être multiple :
- variable(s) manquante(s)
- variable(s) ayant un mauvais typage (« chaîne de caractère » au lieu d’un type « date » par exemple)
- changement de la distribution d’une variable
12 – Les coûts engendrés par Autopilot
Il existe un coût pour l’utilisation de l’ensemble de la démarche. Dans un premier temps Amazon SageMaker Studio est gratuit, nous payons que les composants que nous utilisons dedans.
Dans un second temps, il est obligatoire de créer un notebook pour avoir un support de travail et créer donc notre cycle ML. Lorsque nous créons un notebook Jupyter avec une puissance de 64 GB de mémoire et 16 vCPU (Région Europe & Instance Standard), cela coute 1,28$ l’heure d’utilisation quel que soit la tâche que l’on effectue (traitement, entrainement, déploiement).
Par exemple, si nous déployons notre modèle pendant 1 mois, le prix à payer sera de (nombre d’heures par mois) * (prix par heure) donc 24*31*1.28 = 952.32$
Conclusion
Les systèmes autoML, décrits comme étant des « boîtes noires », sont aujourd’hui très critiqués par leur manque de transparence. Amazon SageMaker Autopilot s’est différencié en permettant d’avoir une visibilité et un contrôle complet sur l’ensemble du cycle machine learning. Il a pour but de démystifier le machine learning avec une volonté de faire évoluer la connaissance de l’utilisateur. Mais, cet outil attend de vous que le jeu de données contienne des indicateurs pertinents pour répondre à votre problématique business, en effet vous ne devez pas négliger les sessions de réflexions intenses avec les experts métiers. Une fois cette étape terminée, vous pourrez tirer pleinement profit d’Amazon SageMaker Autopilot.
Pour plus de détails sur les points abordés durant cet article, nous vous invitons à consulter les liens suivants:
- Amazon SageMaker : https://aws.amazon.com/fr/sagemaker/
- Article Amazon Sagemaker Autopilot : https://assets.amazon.science/e8/8b/2366b1ab407990dec96e55ee5664/amazon-sagemaker-autopilot-a-white-box-automl-solution-at-scale.pdf

