
Vous le savez, le Machine Learning (ML) consiste à développer des systèmes d’informations capables d’apprendre et de s’adapter sans suivre d’instructions explicites, et ce en utilisant des algorithmes et des modèles statistiques qui analysent et tirent des conclusions à partir d’un historique de données.
Cependant, la conception de ces algorithmes ne constitue qu’une petite partie de l’ensemble du processus global car ces modèles peuvent être contraints par d’autres exigences telles que :
- être capable de s’adapter en continu aux nouvelles données
- assurer systématiquement un certain niveau de performance minimal
- garantir un niveau de performance supérieur des modèles récents par rapport aux modèles anciens
- garantir que le modèle est capable de répondre aux flux de requêtes reçues
- ..
Ces étapes jouent un rôle primordial dans la livraison d’un produit final réussi. Elles demandent des compétences très variées et sont très chronophages. En effet, il n’est pas évident de mettre en place un Pipeline qui permet de répondre correctement aux différentes briques d’un projet Data Science.
Nous allons présenter le service managé Kubeflow de Google Cloud Platform, destiné à concevoir des Pipelines reproductibles et scalables.
Dans cet article, vous aurez également un tutoriel pour mettre en place vous-même un Pipeline sur Kubeflow.
Kubeflow : fonctionnement et avantages
Kubeflow est une plateforme ML gratuite et open-source conçue pour permettre l’utilisation de pipelines ML et ainsi permettre l’orchestration de flux de travail complexes. C’est une sur-couche de Kubernetes destinée à démocratiser l’IA et à répondre aux différentes préoccupations des data scientists et data engineers.
Un Pipeline de Machine Learning consiste à automatiser et à orchestrer les différentes étapes de conception d’un modèle de Machine Learning. Sur Kubeflow, nous allons plutôt traiter ce flux de travail comme une séquence d’étapes distinctes (et modulaires) où chacune de ces étapes est relative à une tâche. Chaque étape va être conçue séparément des autres : elle va avoir un script qui lui est propre et ce script va être enregistré avec ses différentes dépendances sous forme d’image Docker dans ce qu’on appelle un Google Registry privé.
Chaque étape du Pipeline global :
- est basée sur une image Docker préconstruite
- prend en input (et en arguments) les outputs de l’étape précédente
- peut faire passer des outputs aux étapes qui suivent
Un Pipeline est ensuite exécuté sur un cluster Kubernetes de Google contenant plusieurs nœuds.
Voici les différents avantages à travailler sur Kubeflow :
- Historisation et organisation : nous avons accès à l’ensemble de l’historique des exécutions. Nous pouvons regrouper les exécutions par expérience ou encore avoir accès aux différents inputs et outputs des différentes étapes constituant un “run” (exécution). Autre avantage : tout est historisé. Ainsi, par exemple, la question de savoir quelles données ont été consommées par quel modèle ne se pose plus.
- Automatisation : nous pouvons programmer notre pipeline pour mettre à jour le modèle à des intervalles de temps fixes, en nous assurant que notre modèle s’adapte bien aux nouvelles données d’apprentissage au fil du temps.
- Reproductibilité : Comme un pipeline se décompose en plusieurs étapes séquentielles indépendantes, nous pouvons facilement réutiliser une seule étape dans d’autres pipelines. N’importe qui peut relancer un pipeline en uploadant un fichier compilé. Il n’y a ainsi pas de gestion de dépendances, de librairies, etc…
- Découplage de l’environnement : En gardant les étapes d’un pipeline indépendantes, nous pouvons également exécuter différentes étapes dans différents types d’environnements.
- Espace collaboratif : Sur AI Hub, nous avons un catalogue de Pipelines disponibles. Aussi, les data scientists peuvent mettre leurs Pipelines en ligne et les partager ainsi plus facilement avec leurs collègues.
Démonstration
Dans ce tutoriel introductif, nous allons déployer un Pipeline sur Kubeflow pour exécuter les étapes suivantes :
- Requêter des données publiques depuis BigQuery
- Pré-processer les données
- Entraîner un modèle
- Tester le modèle
- Déployer le modèle
1 – Création des pré-requis
Tout d’abord, il faut créer un cluster Kubernetes depuis l’interface utilisateur de Kubeflow puis le déployer. En effet, les calculs des différentes étapes du Pipeline seront effectués sur ce cluster. Quand le déploiement est fini, il faut copier la clé qui va nous permettre de lier n’importe quelle instance à ce cluster. Pour ce faire, il faut cliquer sur Settings à droite du Pipeline dans AI Platform.

Nous allons ensuite créer un notebook depuis AI Platform.
Il est à noter que ce notebook ne sera pas utilisé à des fins d’exploration de données comme le veut l’approche traditionnelle, mais sera utilisé pour concevoir le Pipeline final. Ensuite il faut bien copier la clé du cluster dans une cellule du notebook.
2 – Développement des étapes et construction des images
Comme expliqué auparavant, un Pipeline n’est autre qu’un ensemble d’étapes successives (ou dans certains cas parallèles) où différents inputs et outputs sont nécessaires. Chaque étape doit donc être un script Python indépendant qui prend en entrée des arguments et qui effectue des calculs. Ce script aura son propre Dockerfile contenant ses différentes librairies. Son image va ensuite pouvoir être construite puis poussée dans le Google Registry.
Voici un exemple de code pour construire une étape de bout en bout :
- Script Python
- Dockerfile
- Construction de l’image
|
# export variables # build and push preprocess image # build and push train image # build and push test image |
Nous pouvons ainsi voir les images dans le Google Registry

Fig. Images dans Registry
Il est à noter que certaines étapes sont pré-construites par Google : il est possible de trouver des images qui sont prêtes à être utilisées, en fonction des besoins.
Dans cette démonstration, la première étape qui va requêter les données depuis BigQuery et les stocker sur GCS, ainsi que la dernière étape qui consiste à déployer le modèle sont en réalité des composants pré-construits.
3 – Construction des étapes sur le notebook
Le SDK de Kubeflow va se servir des images poussées dans le Registry pour construire les différents composants du Pipeline. Voici par exemple l’étape pré-process, évoquée précédemment :
|
def preprocess_op(file_gcs_path, bucket_name=BUCKET_NAME): return dsl.ContainerOp( |
4 – Construction du Pipeline
Une fois les différents composants construits, il reste à définir l’ordre de leurs apparitions et les différentes dépendances entre inputs-outputs. Dans notre exemple, une fois les données requêtées depuis BigQuery et pré-processées, elles vont servir à entraîner un modèle (qui sera ensuite testé et déployé). Il est possible d’ajouter des conditions pour le déploiement mais nous ne couvrons pas cette partie dans cette démonstration. Voici le code qui permet de définir le Pipeline :
|
@dsl.pipeline( def pipeline( |
Il est à noter que la commande “.after(previous_step)” permet de définir l’ordre d’exécution des composants.
5 – Exécution et résultats
Pour lancer le Pipeline (on parle de “run” du Pipeline), il faut utiliser le compilateur “compiler” de l’SDK “kfp” qui va générer un fichier tar.gz contenant l’ensemble du Pipeline.
Le fichier tar.gz peut également être partagé avec des collègues qui pourront reproduire le travail depuis n’importe quelle machine.
Voici le graphe généré après l’exécution du Pipeline.
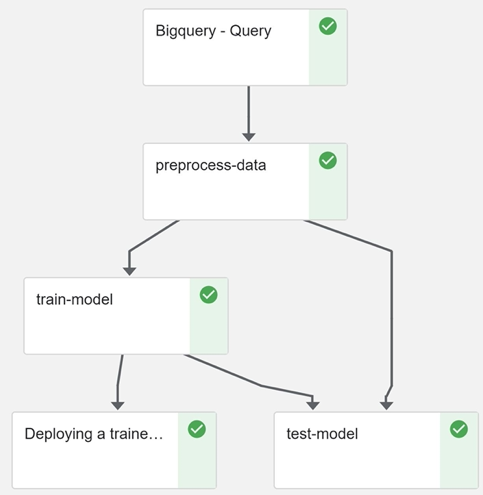 Fig. Pipeline sur Kubeflow
Fig. Pipeline sur Kubeflow
Il est à noter que les différents “runs” sont regroupés par “expérience”, et que chaque étape du Pipeline est historisée avec ses différents inputs et outputs.
Conclusion
Kubeflow présente un certain nombre d’avantages si vous cherchez à construire un Pipeline entier. Il répond parfaitement à la problématique d’historisation des données.
Ceci étant dit, ce service managé nécessite un grand travail de préparation en amont et quelques connaissances de Docker car chaque étape est en réalité un script indépendant conteneurisé. C’est d’ailleurs la conteneurisation qui confère une scalabilité sans limite et une reproductibilité aisée de votre Pipeline.

