1. Evolution des architectures
Ces dernières années, les paradigmes de l’informatique changent profondément :
- Avènement du Cloud public : AWS en précurseur, Azure et GCP en challenger
- Rationalisation et l’industrialisation des métiers IT : Segmentation Datacenter, Socle technique, Virtualisation, Sécurité, Applications
- Virtualisation des fonctions réseau (NFV) : Firewall, Load-Balancer, Proxy notamment
Toutes ces révolutions permettent de répondre aux demandes d’agilité des développements applicatifs et aux métiers de se concentrer sur leurs cahiers des charges fonctionnels en tenant moins compte des contraintes techniques et financières (paiement à l’utilisation réelle) sous-jacentes.
Cette agilité s’appuie sur l’automatisation des déploiements (CI/CD, DevOps), et une infrastructure capable de produire des environnements virtuels (VM, Container ServerLess) répliqués, résilients et scalables dont les développeurs n’ont plus à se soucier au niveau de la structure de leur code.
Si cette révolution est en marche pour la virtualisation (Les solutions existent et sont en production : KVM, AWS/Nitro, VMWare, Hyper-V, OpenStack, Hyper-convergence, etc ..) et permet de fournir du compute et du stockage à la demande (résilients, scalable et facturés à l’utilisation), la révolution réseau a plus de mal à se mettre en place.
2. Problématique de la virtualisation du réseau
En effet la problématique réseau a longtemps été liée à des problèmes de performances technologiques pures : temps de traitement électronique, temps de latence, algorithme de correction d’erreurs, débit.
Avec l’augmentation de la puissance des CPU et la miniaturisation des puces, le traitement de certaines taches réseau ont pu être envisagées :
- D’une part en mode software (par opposition au mode full Hardware/ASIC) en virtualisant et distribuant les fonctions (NFV)
- D’autre part en gérant le switching/routing sous forme de processus système via des protocoles standardisés tels que : OVSDB, NetConf ou OpenFlow.
Toutes ces avancées ont permis l’émergence des solutions, dorénavant très médiatisées, SDN (Software Defined Network).
Les principes sous-jacents sont:
- Séparation du Control Plane / Data Plane
- Automatisation et Programmation par API des éléments du réseau (Virtuels ou Hardware)
- Indépendance vis-à-vis des constructeurs de matériel / éditeur de solutions
- Visibilité dynamique de la topologie du réseau (car gestion et remontées de traces centralisées) et gestion/optimisation temps réel des flux réseau
A partir de cette définition très générique (et théorique) des solutions SDN, il est utile de revenir à une description succincte des architectures réseau actuelles (dites « legacy ») pour comprendre l’engouement pour le SDN et les choix protocolaires qui ont été envisagés pour sa mise en œuvre.
Les design réseau « standards » en Datacenter ont jusqu’ici été construits sur des modèles hiérarchiques en 3 couches : Cœur/Agrégation/Accès avec propagation et distribution de VLANs (et apprentissage des MAC) pour que la communication entre les serveurs (et les applications) puisse s’établir.
De plus cette architecture permet de créer plusieurs réseaux logiquement séparés pour traiter des besoins d’administration, de sécurité, de séparation front/back.
Avant la virtualisation, cette architecture ne présentait pas de défauts majeurs : les flux entre les serveurs physiques remontaient sur les switch d’agrégation pour les communications niveau 2 et sur les cœurs pour le niveau 3 (routage externe / interne). Les utilisateurs accédaient par le niveau 3 pour consommer les applications et les applications communiquaient entre elles par ce même niveau 3.
On parlaient alors de flux Nord-Sud et les « tuyaux »/cartes étaient dimensionnés en conséquence. Les applications étaient PHYSIQUEMENT localisées sur des serveurs identifiés et il y avait peu de changement sur les plans d’adressage, la numérotation des VLANs, l’agrégation des routes, les tables MAC, bref sur la topologie réseau.
Un exemple de topologie datacenter 3 Tiers Cisco :
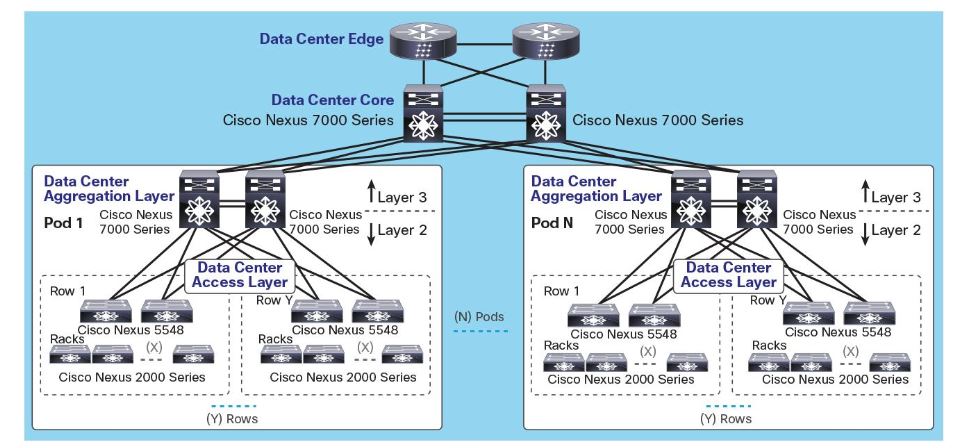
Avec la virtualisation massive (et la résilience associée), la nature des flux a changé : Les Hyperviseurs ou Les container permettent de générer des contextes serveurs (VM ou Container) sur tout le parc physique (y compris entre datacenter) et normalement sur tous les VLANs engendrant des flux Est-Ouest massifs, qui explosent les limitations techniques des architectures « legacy » : Nombre de VLANs, Table de MAC Address, Nombre de SVI, Bande passante, notamment.
3. Problématiques du SDN
Afin de traiter ce nouveau type de topologie, les solutions SDN ont dû envisager de nouveaux protocoles pour connecter des segments L2 à travers des réseaux L3 sans remettre en cause toutes les architectures existantes et surtout le fonctionnement des applications « legacy ».
Cette virtualisation des réseaux (i.e. la création d’un réseau dit « overlay » à base de tenants sur un réseau sous-jacent traditionnel « underlay », chaque tenant pouvant être de type L2 ou L3 avec la notion de VLANs/Subnet/IP/MAC et surtout la possibilité de déplacer les VM/Serveurs facilement) doit permettre de s’abstraire des limitations techniques et physiques des réseaux sous-jacents et de leur interconnexion.
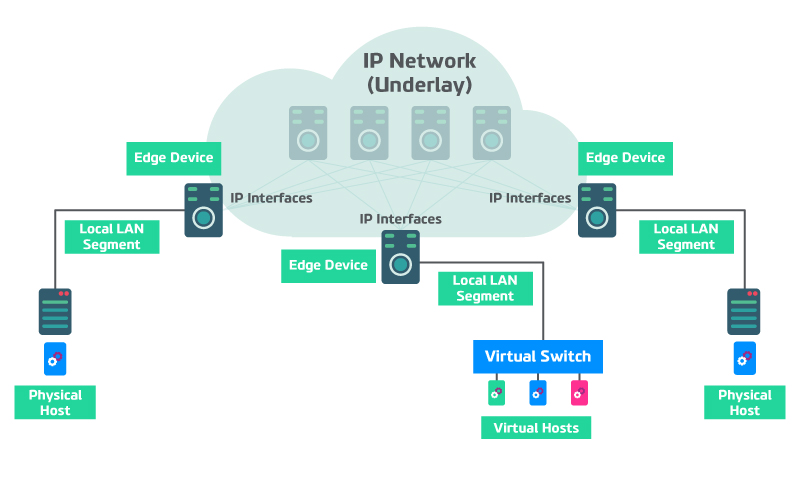
Représentation du réseau Underlay :
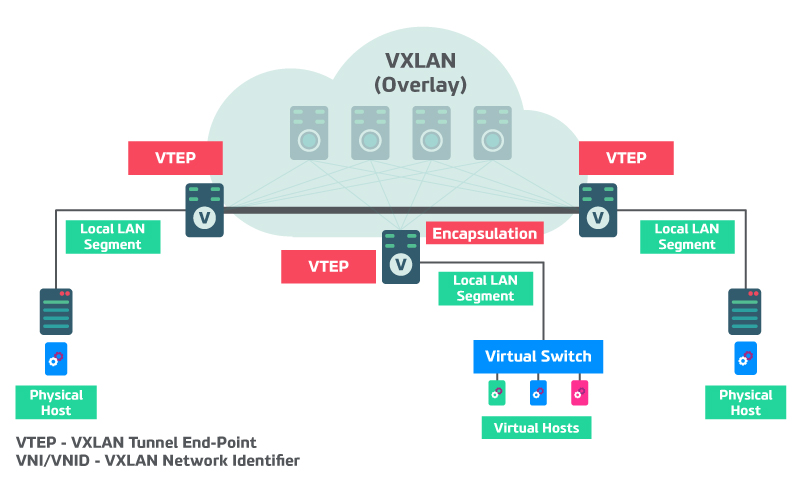
 Représentation du réseau Overlay :
Représentation du réseau Overlay :
Les protocoles de virtualisation et d’isolation de ces tenants sur les architectures actuelles sont étudiés par le groupe de travail IETF NVO3 ((V)irtualisation par (O)verlay des (N)réseaux par utilisation de techniques L3).
Pour simplifier, le but de ce groupe de travail est de traiter les problématiques suivantes :
- Augmentation massive du nombre de réseau dans une même organisation (société)
- Augmentation exponentielle du nombre de nœuds (VM) sur des milliers de serveurs physiques
- Déplacement des VMs (réplication / résilience)
- Provisioning dynamique et automatisé des tenants
- Adressage IP indépendant par tenant
- Isolation des tenants entre eux
- Optimisation du data plane (Forwarding) : évitement des chemins sous-optimaux
4. VxLAN
Une des réponses apportées par ce groupe est : VxLAN (Développé par VMWare et supporté par le NVO3) qui va générer des overlay L2 sur du L3 et répondre aux besoins d’interconnexion multi-tenants sur réseau L3 (Il existe d’autres protocoles comme NVGRE ou NTT, mais qui répondent à d’autres besoins non abordés dans cet article) :
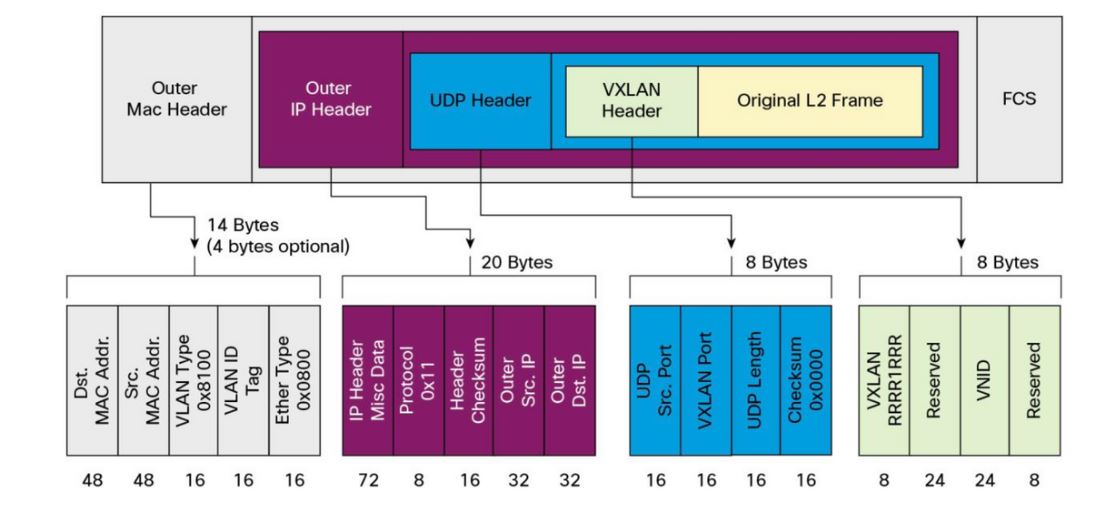
- Trame VxLAN : Trame UDP sur IP encapsulant la trame L2 provenant du tenant
- En s’appuyant sur des protocoles L3 matures et éprouvés, le VxLAN hérite d’ECMP (Equal-Cost MultiPath)
- Le port UDP source est un hash de l’entête MAC interne à la trame pour permette la répartition de charge.
- Limitations repoussées : 2^24 VxLAN possibles (VNI)
- Isolation : Seuls les nœuds dans le tenant peuvent communiquer entre eux
- Chaque tenant est indépendant et possède son adressage/MAC propre qu’il peut partager avec d’autres tenants
- Tagging (802.1q) extérieur possible sur la trame VxLAN pour isoler le trafic sur un LAN sous-jacent.
- Notion de VTEP : VxLAN Tunnel End Point qui porte les entrées/sorties du tunnel VxLAN.
- Compatibilité : Les VM ne « voient » pas si elles sont sur un VLAN ou un VxLAN
Description de la trame VxLAN :
5. Famille d’adresses EVPN
Pour traiter cette contrainte, sur des réseaux IP/MPLS (les plus déployés dans les grandes organisations), des services supplémentaires ont été ajoutés : BGP-Based EVPN (RFC 7432) pour traiter le Flood&Learn (trafic BUM) inhérent à VxLAN (RFC 7348 → VxLAN ne préconise pas de control plane sur l’overlay).
En particulier EVPN introduit les notions suivantes :
- EVPN se positionne en tant que control plane du réseau overlay.
- EVPN est similaire à du L3VPN MPLS pour Ethernet
- EVPN s’appuie sur une extension du protocole MP-BGP qui doit savoir gérer de nouvelles informations d’accessibilité de la couche réseau (EVPN NLRI). Ces informations sont transportées par des familles d’adresses MP-BGP spécifiques
- En particulier, dans les nouveaux types de routes NLRI se trouve « MAC/IP Advertisement Route » qui permet d’apprendre les MAC address venant des PE distants (Remote Learning) en s’appuyant sur les mécanismes BGP en évitant d’utiliser les mécanismes multicast sur l’ underlay.
- Pour les annonces entre les CE et les PE, EVPN met en place un nouveau type d’objet : « Ethernet Segment » avec comme identifiant un ESI unique pour toutes les instances EVPN du réseau de l’organisation.
- Ces ESI prennent en compte le multi-homing actif-actif type : LACP.
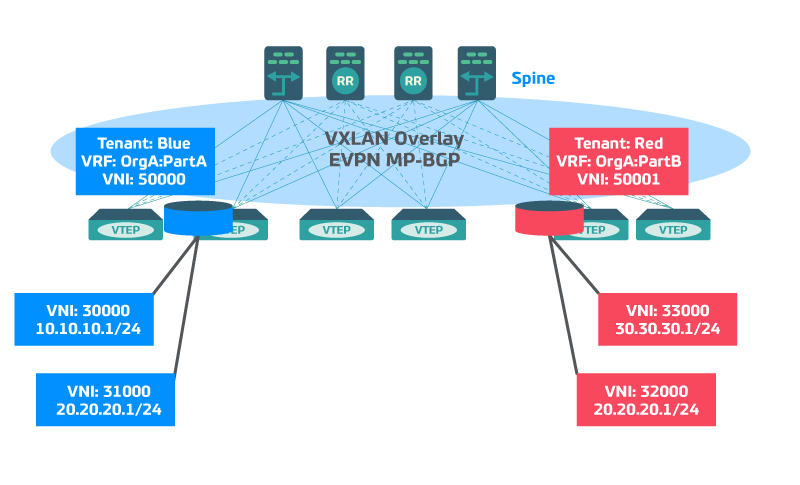
Représentation d’un réseau Spine&leaf Multi-tenant VXLAN MP-BGP EVPN :
Le but de cet article était de mettre en évidence les transformations profondes sur les architectures réseau avec des protocoles utilisés qui sont encore en cours de développement pour répondre au défi de migration des architectures traditionnelles vers des solutions SDN, indispensable pour dépasser les limitations techniques sur les réseaux actuels.
Les entreprises passeront de l’exercice théorique à la mise en production à grande échelle par la compréhension de ces concepts (et la stabilisation des ces « nouveaux » protocoles) et en maîtrisant techniquement ce qu’apportent des solutions telles que : ACI, Nuage Networks, Contrail, ou NSX.
Une étude de cas est l’utilisation de la solution Nuage Networks pour gérer des hyperviseurs, des serveurs physiques et des switch gérant des VTEP hardware pour piloter indifféremment un cloud privé tel que : VMware, OpenStack ou CloudStack par exemple.
Découvrez notre playground Distributed Cloud

