Deep learning signifie littéralement en anglais « apprentissage profond » et correspond à des modèles d’IA (Intelligence Artificielle) très spécifiques qui utilisent l’apprentissage par couches successives. Ainsi, on entend parler de réseau de neurones convolutifs, de réseau convolutionnel, de DNN (pour « deep neural network ») ou encore de CNN (pour « convolutional neural network »). Tous ces termes restent synonymiques.
Les réseaux de neurones sont des méthodes d’apprentissage automatiques qui permettent de modéliser avec un haut niveau d’abstractions des données, par un apprentissage profond reposant sur l’idée que le monde est compositionnel. Ainsi, le réseau de neurones convolutif va, au travers des couches peu profondes, apprendre à reconnaître les traits verticaux, horizontaux et obliques. Puis, en profondeur du réseau, le modèle va combiner les motifs appris lors du passage dans les couches peu profondes pour reconnaître des formes plus complexes.
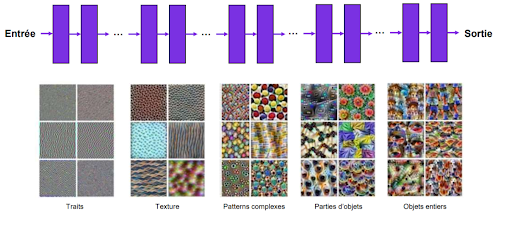
Figure 1 : Principe d’apprentissage simplifié d’un réseau de neurones convolutif
Il faut savoir qu’il existe trois grands courants pour le deep learning :
▪ la reconnaissance d’images pour la reconnaissance d’objets dans une image et/ou pour la classification d’images d’une base de données
▪ la reconnaissance vocale et l’analyse de signaux sonores
▪ le traitement automatique du langage naturel pour la classification de contenus textuels, la recherche d’entités (zone géographique, nom propre, lieu, …) et d’intentions dans un texte
Cet article présente ce qu’est le deep learning appliqué à la reconnaissance d’images et comment fonctionne un réseau de neurones convolutif.
Quelques exemples d’application du deep learning pour la reconnaissance d’images
Le deep learning fait beaucoup parler de lui auprès du grand public, et ci-dessous, nous vous présentons quelques exemples d’applications amusantes.
DeepSketch to face est une technique d’interprétation par le deep learning d’un croquis. A titre d’exemple, les équipes de Disney ont présenté courant de l’été 2020, la dernière version de leur système DeepSketch to face. C’est un bel exemple de ce que les départements R&D des grands studios sont capables de produire pour optimiser le temps de production d’un film.
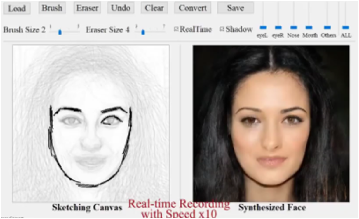
Figure 2 : Illustration des techniques de DeepSketch to face
source : http://geometrylearning.com/DeepFaceDrawing/
L’art style transfert learning permet de transformer une image (ou vidéo) en une nouvelle image (ou vidéo) en y appliquant le style d’une œuvre d’art (ce style ayant été appris par le réseau de neurones). Dans l’exemple ci-contre, l’algorithme a rapproché le visage de la photo au style de l’artiste peintre Delaunay pour un résultat assez bluffant.

Figure 3 : Art style transfert learning “A la manière de Delaunay“
Le deepfake, ou hypertrucage est une technique de synthèse d’images qui permet de superposer des fichiers audios et vidéos existants sur d’autres vidéos (par exemple : pour changer le visage et la voix d’un acteur dans un film). Le terme deepfake est un mot-valise formé à partir des mots deep learning et de fake. Cette technique est largement utilisée pour créer des infox.
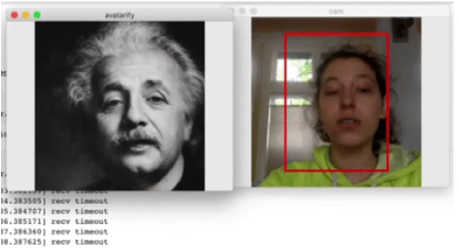
Figure 4 : Deep fake… et si j’étais Einstein ?
Source : https://github.com/DashBarkHuss/100-days-of-code/blob/master/post-log.md#avatarify-1
Principe de fonctionnement d’un réseau de neurones convolutif
Pour permettre à un modèle d’IA d’apprendre à partir de vos données, il faut commencer par scinder vos données en une base d’apprentissage et en une base de test.
En fait, dans notre cas d’application, l’apprentissage repose sur des données étiquetées, c’est-à-dire que votre base d’entraînement contient des images pour lesquelles vous connaissez l’étiquette (on parle aussi de « label »). Par exemple, vous avez une image de chien associée au label chien (image associée au bon label pour permettre au réseau d’apprendre correctement).
A partir de votre base d’entraînement, votre réseau de neurones va donc apprendre par lui-même à reconnaître les labels associés à chaque image.
Pour ce faire, au cours de l’apprentissage, votre réseau de neurones va apprendre à calculer des poids pour chaque neurones du réseau. Ces poids sont calculés par propagation-avant (« forward propagation ») et propagation-arrière (« backward propagation ») : on parle de rétropropagation d’une fonction d’erreur pour calculer ces poids.
En fait, la rétropropagation est l’opération qui consiste au recalcul de tous les poids de connexion dans le réseau en corrigeant la valeur des poids en fct des erreurs/écarts mesurés lors des propagations précédentes. Il y a une succession de propagations-avants, propagations-arrières … jusqu’à ce que le réseau sache bien prédire pour l’ensemble de la base de données d’entraînement, l’étiquette correcte associée à son image.
Une fois que votre réseau de neurones est entraîné, vous pouvez faire fonctionner votre modèle sur vos données de test et vérifier vos prédictions sur des images que votre réseau ne connaît pas. Les prédictions sont-elles correctes ? Quelle est la performance de votre modèle de deep learning ?
Détails sur chaque bloc de construction du réseau de neurones
Au niveau technique, l’architecture d’un réseau de neurones se compose de différents types de couches : les couches de convolution, les couches de pooling, les couches intégralement connectées (« fully connected ») et la couche de sortie associée à une fonction softmax.
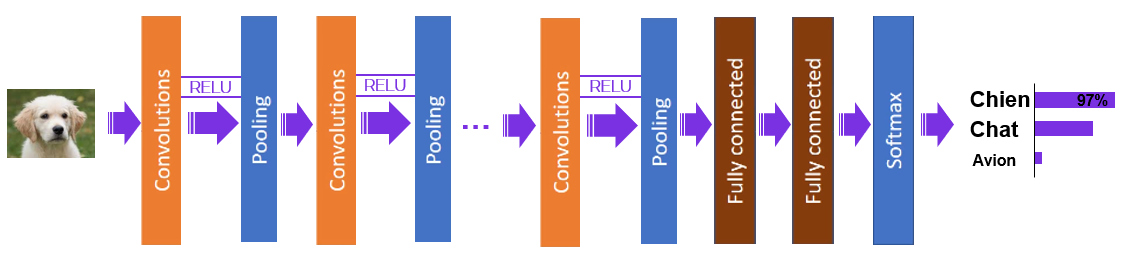
Figure 5 : Blocs de construction d’un réseau de neurones convolutifs (CNN)
Couches de convolution
Ce sont les principaux blocs de construction utilisés dans les réseaux de neurones convolutifs.
Dans une couche de convolution, les neurones ne sont pas connectés à chaque pixel de la couche précédente mais uniquement aux pixels dans leurs champs récepteur. Le champ récepteur correspond à un petit rectangle, filtre appliqué sur l’image comme le montre la figure ci-dessous.
Cette architecture permet au réseau de se focaliser sur les caractéristiques de bas niveau dans les premières couches, c’est-à-dire que le réseau comprend les formes simples (traits horizontaux, obliques et verticaux). Puis, au fur et à mesure qu’on progresse en profondeur du réseau, le modèle combine les caractéristiques de bas niveau avec des caractéristiques de plus haut niveau (des formes complexes).
La taille du filtre appliqué (champ récepteur qui contient l’ensemble des poids) est plus petite que la taille de l’entrée et ceci permet au filtre d’être appliqué plusieurs fois à différents endroits de la couche. La convolution est donc l’opération de mouvement du champ récepteur (filtre) sur les images/couches du réseau.
A noter que les valeurs des filtres (dans l’exemple ci-dessous, matrice ([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]) sont les poids que le réseau de neurones apprend lors de la phase de l’apprentissage.
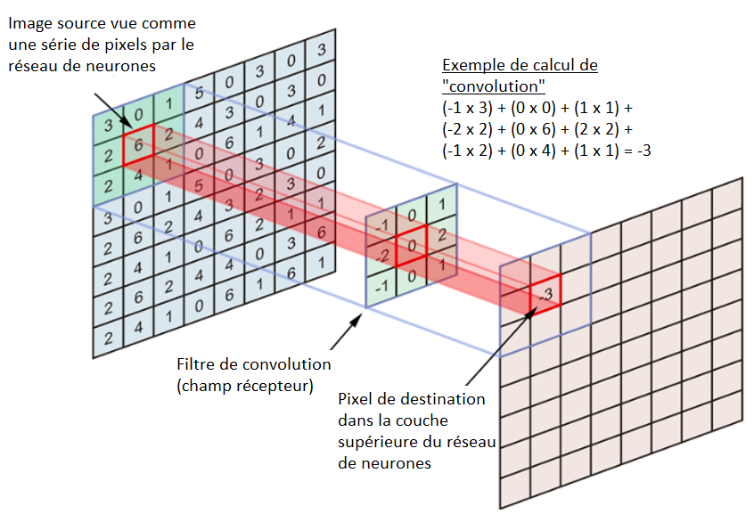
Figure 6 : Opération de convolution appliquée à la reconnaissance d’images
Fonction d’activation
La fonction d’activation est une technique pour résoudre un problème majeur lié au processus de rétropropagation de l’erreur dans le réseau de neurones.
En effet, le réseau de neurones convolutif apprend par propagations-avants (apprentissage de l’entrée du réseau de neurones vers la couche de sortie) et propagations-arrières (rétropropagation de l’erreur dans le réseau, c’est-à-dire couche de sortie vers la couche d’entrée).
Au cours de ces passes, une mise à jour des poids de connexions est réalisée de manière à bien apprendre la bonne étiquette d’une image.
Il y a 2 problèmes majeurs rencontrés lors de la rétropagation de l’erreur :
- Il se peut que les gradients d’erreurs disparaissent, c’est-à-dire qu’au fur et à mesure que l’information progresse dans les couches du réseau, les gradients deviennent très petits et par conséquent, la mise à jour des poids de connexion n’est presque plus effectuée. Alors, le modèle ne converge jamais vers une bonne solution.
- Ou alors au contraire, les gradients d’erreurs deviennent de plus en plus grands et explosent. Alors, les poids de connexion deviennent très grands à leur tour et le modèle diverge.
A noter qu’il existe un autre problème : pour les réseaux de neurones très profonds, l’entraînement peut être extrêmement long.
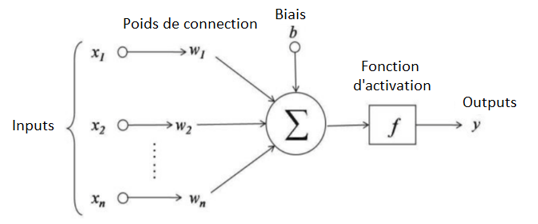
Figure 7 : Principe de fonctionnement d’une fonction d’activation
Bien choisir la fonction d’activation nous garantit une performance optimale.
Voici une liste non exhaustive des fonctions d’activation les plus couramment utilisées :
- Sigmoïd : fonction populaire et ancienne mais hélas, elle présente des problèmes de saturation. La convergence du modèle de deep learning n’est alors plus garantie. Pour en dire quelques mots, cette fonction prend n’importe quelle valeur et retourne des valeurs comprises entre 0 et 1.
- ReLU : fonction linéaire rectifiée (ReLU) est l’une des fonctions d’activation les plus populaires et efficaces. Elle est simple d’utilisation et permet un entraînement plus rapide en nous évitant les problèmes de la fonction Sigmoid.
Elle présente, néanmoins, un problème majeur connu sous le nom de “Dying ReLu” où certains neurones peuvent devenir inactifs/mourir.
- Leaky ReLU : fonction inspirée de la ReLU mais qui permet de surmonter les problèmes de “Dying ReLu”.
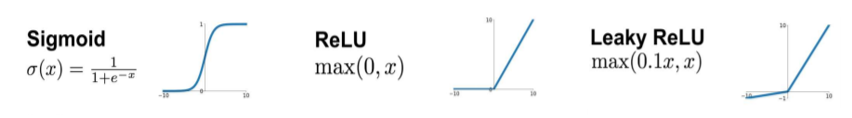
Figure 8 : Formules mathématiques des principales fonctions d’activation
Couches de Pooling
Le problème avec les cartes de caractéristiques (« feature maps ») constituant les couches de convolution, c’est qu’elles peuvent être très nombreuses et quasiment similaires entre elles.
Pour pallier ce problème, on a recours aux couches de Pooling. C’est la deuxième étape clé dans une architecture d’un réseau de neurones convolutifs. Une couche de pooling est une nouvelle couche ajoutée après la couche de convolution. Il s’agit d’une étape de synthèse mathématique de la convolution qui permet de sous-échantillonner (rétrécir) l’image d’entrée en réduisant le nombre des caractéristiques présentes dans une région de la carte des caractéristiques, générée par une couche de convolution.
Cette étape permet alors de réduire l’utilisation de la mémoire, le nombre de paramètres à apprendre et la quantité de calculs effectués dans le réseau.
En pratique, il existe deux méthodes courantes de Pooling :
- Le Max Pooling : calcule la valeur maximale pour chaque fenêtre de la carte des caractéristiques, c’est-à-dire que l’on garde la valeur maximale du pixel de cette région de l’image.
- L’Average Pooling : calcule la valeur moyenne de chaque fenêtre de la carte des caractéristiques, c’est-à-dire que l’on conserve la moyenne de tous les pixels contenus dans la région de l’image.

Figure 9 : Illustration des techniques de Max pooling & Average pooling
Couches « Fully Connected »
Il s’agit de l’une des dernières étapes du réseau de neurones. L’entrée de la couche “fully connected” correspond à la dernière couche de Pooling. Comme le nom anglais l’indique, cette couche est complètement connectée, c’est-à-dire que tous les neurones sont connectés les uns aux autres, permettant l’apprentissage de combinaisons non linéaires entre les « feature maps » de la dernière couche du réseau de neurones. Comme pour les couches de convolution, les couches « fully connected » sont associées à une fonction d’activation. Il s’agit de la fonction softmax qui permet d’associer à chaque sortie du réseau de neurones convolutifs un score, ensuite transformé en probabilité d’appartenir à un certain label d’image.
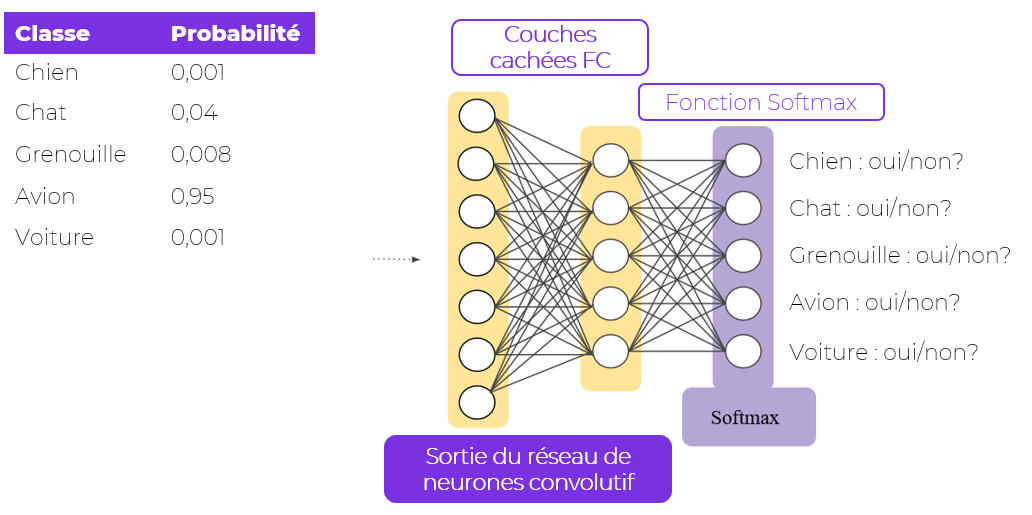
Figure 9 : Couches Fully Connected (FC) & Fonction Softmax
Nous avons vu dans cet article les blocs élémentaires d’un réseau de neurones convolutif. Il faut savoir qu’il existe des architectures éprouvées en deep learning. Ces architectures apportent des performances connues et présentent une structure type : succession de couches de convolution, de pooling et enfin quelques couches FC+Softmax.
A titre indicatif, le LeNet-5 est un modèle de réseau de neurones développé en 1998 et qui a fait ses preuves pour des cas d’usage relatifs à la reconnaissance de chiffres manuscrits sur chèque bancaire (par exemple). Cette architecture est composée de 7 couches : 3 couches convolutives, 2 couches de Pooling et 2 couches intégralement connectées.
Actuellement, les meilleures architectures pour la reconnaissance d’images sont :
- Le modèle GoogleNet composé de 22 couches profondes et qui utilise des sous-réseaux appelés « module d’inception ».
- Le Resnet (« Residual Network ») est un modèle ultra profond composé de plusieurs centaines de couches. La spécificité de ce réseau, c’est l’utilisation de connexions de sauts. Une connexion de saut est un by-pass dans le réseau de neurones qui permet un apprentissage plus robuste du modèle.
Nous vous invitons à regarder par vous-même les différentes architectures de deep learning existantes pour approfondir davantage ce sujet.
Vous souhaitez en savoir plus ?
{{cta(’75c19cbf-9575-4604-8ca3-ebb91649dbff’)}}

