
RFM : un modèle de segmentation client créé il y a 25 ans…
Malgré un changement fort dans les habitudes d’achat des clients, et notamment la digitalisation des interactions, la plupart des entreprises utilisent encore un modèle de segmentation client créé il y a 25 ans, à savoir le modèle RFM.
Mais ce modèle a été pensé pour refléter les comportements des consommateurs dans un environnement qui s’est complètement modifié, transformé. Il ne correspond plus aux attentes actuelles et il paraît essentiel et urgent de proposer un nouveau modèle pour le remplacer.
Si Christophe Coussen, Consultant en CRM et expérience client, après une longue expérience en retail et en transformation digitale au sein des groupes L’Oréal (DGA du Club des Créateurs de Beauté), 3Suisses, et désormais Directeur Marketing Clients et Digital chez Yves Rocher, estime aujourd’hui que « la segmentation cliente issue du modèle RFM a inspiré et inspire encore de nombreux acteurs du retail. Très puissante si elle est bien utilisée et comprise, elle permet notamment de donner du sens à la relation client et surtout d’aider les marketeurs à piloter leur action notamment sur la qualité de leurs offres et leurs plans de contacts avec leurs différentes typologies de clients », il affirme également que depuis quelques années le modèle a atteint ses limites.
Et C. Coussen de compléter : « Créée pour un monde retail et direct mail, monocanal, elle n’intègre pas ou peu les interactions mobiles consommateurs et plus globalement l’influence du digital sur les parcours d’achat en mode omnicanal. »
C’est pour répondre à cet enjeu d’adéquation du modèle avec son époque que Ysance relève aujourd’hui ce défi marketing. Spécialiste du retail notamment omnicanal (on parle d’omnicanalité lorsque l’ensemble des canaux de contact et de vente sont mis en œuvre entre une entreprise et ses clients), Ysance propose la modernisation de modèle RFM par l’IA, « et surtout de le faire progresser sans en perdre ses qualités originelles » souligne C. Coussen.
Cette tribune est la première d’une suite de 5 articles sur l’état actuel de la segmentation client, et la révolution retail que nous défendons. Le temps de lecture de cet article est estimé à 10 min.
Les parcours d’achat se sont digitalisés…
Le secteur du B2C est marqué par un changement d’habitudes majeur depuis la création du modèle RFM en 1995 : l’avènement d’internet.
En effet, 85% de la population française de plus de 2 ans se connecte à internet au moins une fois par mois soit 52,8 millions de français. Ce chiffre est en constante évolution depuis le début des années 2000 avec une croissance de 25% du nombre d’internautes sur les 5 dernières années. Parmi ces internautes, 86% se connectent quotidiennement (soit 73% de la population).
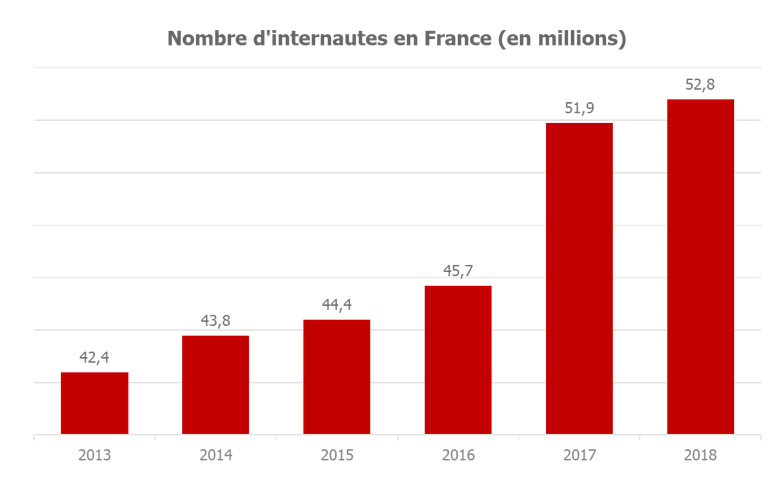
En s’intéressant plus particulièrement au retail, le chiffre d’affaires e-commerce en France s’élève à 92,6 milliards d’euros en 2018 (+13% par rapport à 2017) soit 9,1% du chiffre d’affaires global du commerce de détail (Source : Fevad).
Mais plus que les achats en ligne, les prospects se renseignent maintenant sur internet avant d’aller faire un achat en magasin. C’est ce qu’on appelle l’effet ROPO : Research On-line, Purchase Off-line, traduisez « Rechercher en ligne et acheter en magasin ». (voir : Voyage au coeur du ROPO).
Les consommateurs sont donc de plus en plus influencés par le web et les sites marchands. Il est primordial de tenir compte de ces nouveaux usages.
Mais les modèles éprouvés n’ont pas évolué…
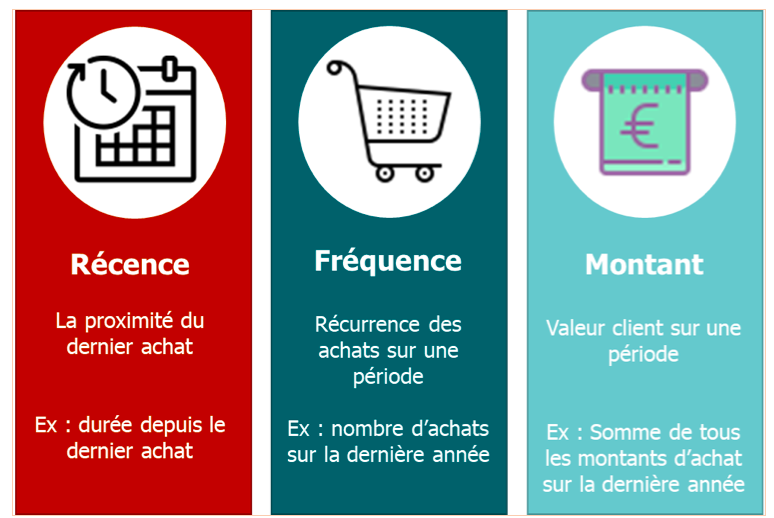
Le modèle RFM (Récence, Fréquence, Montant) est un outil de marketing analytique utilisé pour identifier différents segments de clients et notamment pour définir ses « meilleurs » clients. Il s’appuie sur les comportements d’achat historiques des clients.
Ce modèle de segmentation client est basé sur 3 facteurs quantitatifs :
(Pour en savoir plus sur le modèle RFM, voir la note en fin d’article.)
Le modèle RFM est donc très intuitif, extrêmement facile à mettre en place et nécessite peu de puissance de calcul. Le résultat est facilement interprétable et est très parlant, même pour les non-initiés. Il dispose néanmoins d’une limite importante, il a été créé en 1995 pour répondre à des comportements d’achats qui ont bien changés, comme démontré au chapitre précédent.
Ce modèle étant largement utilisé et ayant fait ses preuves, il est apparu comme le point de départ évident ou naturel pour la création d’un nouveau modèle de segmentation client.
Adapter la segmentation client aux nouvelles habitudes d’achat : avènement du eRFM.
La question à traiter, c’est celle de la E-influence ou la mesure de l’impact du web sur les ventes. Il paraît aujourd’hui absolument nécessaire d’intégrer l’impact d’internet dans toute segmentation client. Pour ce faire, il faut réconcilier les données clients on-line et off-line : c’est-à-dire savoir reconnaitre un client qui achète sur le site quand il est déjà client magasin (ou inversement).
La RMP Ysance est une solution qui permet de disposer de ces données réconciliées et dédupliquées. La solution permet également de récupérer des informations de navigation sur le site marchand des clients identifiés. Il est donc possible d’intégrer à la fois les achats magasins et web, mais aussi quantifier l’influence du site internet de l’enseigne dans le parcours d’achat du client. Cela permet l’ajout d’un paramètre supplémentaire aux 3 existants (R, F, M) : la e-influence.
Il est important d’adresser différemment les clients fortement e-influencés et les clients adeptes du choix en magasin. Ce premier point permet donc de s’adapter aux changements d’habitudes de consommation des dernières années : un volume d’achat en ligne croissant et une influence du web et du mobile sur les achats en magasin toujours plus importante (effet ROPO).
Renouveler la méthode de segmentation avec le Machine Learning.
En plus du changement sur les paramètres utilisés, il importe également de renouveler la méthode de segmentation client en utilisant les outils actuels : les algorithmes de machine learning.
Pourquoi changer de méthode ? Essentiellement parce que le modèle RFM présente deux limites importantes dans sa construction même :
- Le modèle RFM n’est pas un modèle quantitatif précis : en utilisant les données d’achat historique des clients, il évalue la valeur d’un client en se basant sur une méthode biaisée par une sélection subjective. En se basant sur la loi de Pareto, le modèle RFM suggère de créer 5 partitions pour chaque paramètre. Ce nombre est défini arbitrairement et biaise l’analyse.
- Chaque paramètre (R, F, M) a une importance différente pour différentes industries. Pour certaines industries la fréquence d’achat sera beaucoup plus importante que la récence du dernier achat et pour d’autres cela sera l’inverse. Le modèle RFM est incapable de pondérer ces différents paramètres pour créer un indicateur unique.
Bien que le modèle RFM soit très utilisé, il comporte des limites de taille, notamment le biais amené par le choix de 5 partitions par paramètre et le fait que la population soit séparée en groupes égaux. Il est fort probable qu’il soit plus intéressant de prendre des groupes de taille différente en les définissant grâce à la donnée récoltée sur le comportement de ses propres clients.
Et Dieu créa le Machine Learning ! Il importe de réduire les biais de sélection que le modèle RFM impose, tout en conservant ses points positifs (notamment la facilité d’interprétation pour l’utilisateur final).
Le recours aux algorithmes (de Machine Learning) d’apprentissage non-supervisé s’est rapidement imposé. Ces algorithmes ont été créés pour trouver des groupements d’individus similaires (ou homogènes), aussi appelé clusters, selon les attributs, ou caractéristiques, disponibles. L’objectif d’un algorithme de clustering est de trouver un ensemble de groupes qui maximise :
- la ressemblance entre les individus d’un même groupe,
- la différence entre deux individus de deux groupes différents.
Les algorithmes d’apprentissage non-supervisé ne sont pas des modèles prédictifs, leur objectif est de regrouper des individus semblables.
En d’autres termes, l’algorithme va rassembler des consommateurs ayant des comportements d’achats similaires au sein d’un même groupe.
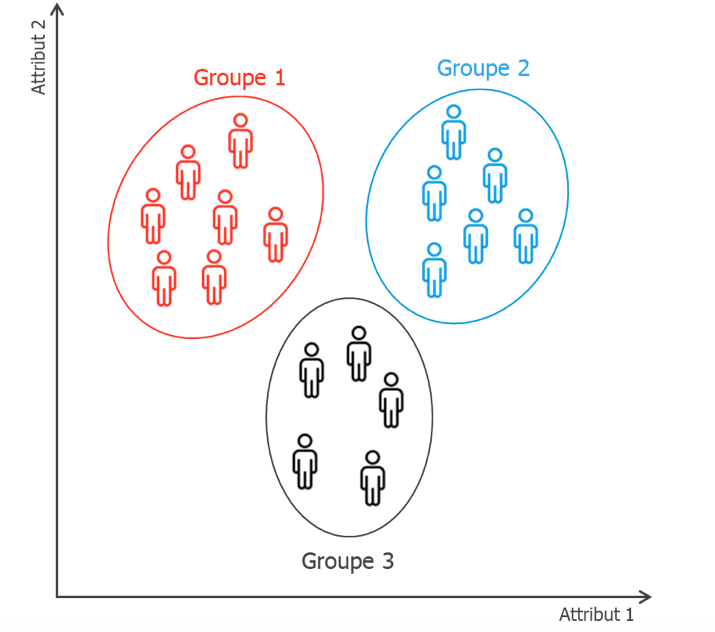
Exemple de clustering en trois groupes sur une population avec deux attributs.
Une fois les groupes découverts par l’algorithme, un data scientist doit interpréter les résultats. Il s’agit ici de découvrir quels sont, au sein de chaque groupe, les facteurs communs qui font que les individus sont regroupés.
Ysance a donc développé un algorithme d’apprentissage non-supervisé. Cet algorithme a été sélectionné en particulier pour la facilité d’interprétation de ses résultats mais aussi car il dispose d’un fort pouvoir explicatif : on peut donc facilement expliquer pourquoi le modèle a créé ces groupes et pourquoi, pour chaque individu, ils sont assignés à tel ou tel groupe.
Cette méthode a de nombreux points forts :
- Les biais de sélection dont nous parlions pour le modèle RFM, sont fortement limités. L’algorithme forme les groupes par rapport aux données et non par une sélection arbitraire (rappel : 5 groupe pour le modèle RFM).
- L’importance de chaque paramètre (récence, fréquence, montant, e-influence) est défini par la donnée. L’algorithme prend en compte les paramètres en fonction de leur capacité à découvrir des groupes homogènes. Par exemple dans un premier cas, la récence peut être le facteur le plus important alors que dans d’autres cas le montant d’achat le sera.
- Une fois l’interprétation faite par le data scientist, les résultats sont très facilement compréhensibles par les équipes métiers.
A ceci s’ajoute une étude des « matrices de migration » : on s’intéresse à la migration d’individus d’un groupe a un autre, en comparant deux périodes données, pour expliquer pourquoi ces individus ont changé de groupe. Cette étude permet de découvrir quelles actions peuvent être mise en place pour stimuler certains groupes de clients et faire migrer ses membres vers des groupes plus « profitables ».
Pour conclure, Ysance est fier de proposer un modèle qui :
- d’une part prend en compte les changements d’usage des consommateurs qui se tournent de plus en plus vers le web pour faire leurs achats, ou qui se renseignent avant de se rendre en magasin,
- d’autre part innove dans sa conception, en se basant sur le machine learning,
- élimine une grande partie des limites du modèle RFM.
Notre prochain article sera consacré à la mise en pratique de ce nouveau modèle : quelle nouvelle valeur peut-on en tirer ? Qu’est ce qu’il permet de voir concrètement qui n’est pas atteignable avec le modèle RFM ? Et comment tirer profit de ces nouvelles informations.
Pour aller plus loin… le modèle RFM
Le modèle RFM a été créé en 1995 par Bult & Wansbeek dans le papier « Optimal Selection for Direct Mail » publié dans Marketing Science. Le modèle se repose sur 3 paramètres : la Récence, la Fréquence et le Montant.
Récence : le postulat est ici que plus le client a réalisé un achat récent, plus il sera probable que le client pense au même retailer pour ses prochains achats. En effet, un client récent sera plus enclin à réaliser un nouvel achat qu’un client qui n’a pas réalisé d’achat durant une longue période. Cette information peut être utilisée pour recontacter les clients récents et les inviter à revenir en leur proposant, pourquoi pas, des incitations à l’achat.
Fréquence : la fréquence apporte 2 informations importantes : la récurrence d’achat et la cyclicité (action qui se répète sur un intervalle donné, par exemple un achat de capsule de café une fois par mois en début de mois).
Connaître la fréquence des achats de ses clients permet d’adapter sa communication. Plus un client achète régulièrement, plus la fréquence de communication peut être élevée.
De plus, en réussissant à identifier un schéma qui se répète dans les comportements d’achat du client, il est alors possible de lui proposer le bon produit au bon moment.
Montant : l’information sur la valeur client permet de cibler les clients qui dépensent le plus et de continuer de les stimuler. Les clients avec une forte valeur client sont susceptibles de reproduire ce comportement d’achat ce qui peut amener un meilleur retour sur investissement des campagnes marketings.
Le modèle RFM est basée sur la loi de Pareto : les 20% des clients avec le plus gros montant d’achat réalisent 80% du chiffre d’affaires, les 80% restants en réalisent seulement 20%. Il est donc primordial d’identifier ses top clients dans ce modèle.
Voici comment se calcule le score RFM : pour chacun des 3 paramètres vus précédemment, chaque individu se verra attribuer un score.
Voici un exemple pour le paramètre R (Récence) :

On découpe donc la population en groupes égaux en la séparant en 5 fois 20 %. Chaque groupe se verra attribuer un score de 1 à 5 (1 étant assigné aux individus du groupe le moins intéressant et 5 pour les individus du groupe le plus intéressant). Pour la Récence, le groupe le plus intéressant est celui contenant les individus ayant fait leur dernier achat récemment (et donc avec une durée depuis le dernier achat la plus courte).
C’est la combinaison des scores des 3 paramètres qui permettra la segmentation de la clientèle : Un score R, un score F et un score M. Le groupe des « meilleurs » clients aura alors la combinaison de score suivante : R = 5, F = 5, M = 5.
Sources : Yeh, I-Cheng, Yang, King-Jang, and Ting, Tao-Ming, « Knowledge discovery on RFM model using Bernoulli sequence » Expert Systems with Applications, 2009
Icones : https://icons8.com/
A propos de Sylvain Franco…
Issu d’une formation en école de commerce, Sylvain débute sa carrière professionnelle en mettant sa passion pour l’analyse de données et la modélisation statistique au service du Retail, notamment chez LEGO où il a travaillé sur la mesure de l’impact des communications digitales sur les ventes (online et offline) et en web marketing. Toujours plus motivé par la résolution de problèmes métiers concrets, il s’est réorienté dans la Data Science en 2017.

