

Au sein de Bouygues Telecom, la mission de l’Innolab Tech est d’imaginer et de concevoir les services et produits de demain. L’arrivée de l’intelligence artificielle générative a naturellement ouvert de nouveaux cas d’usage innovants, destinés aux clients finaux, aux conseillers en boutique, ou à l’ensemble des collaborateurs de l’entreprise. Bouygues Telecom a ainsi développé “Ensemble ce soir”, le nouveau service TV qui permet en moins de 5 minutes de trouver le contenu idéal à regarder en famille. Ce service de recommandation de contenus basé sur l’IA générative a été conçu en collaboration avec Amazon Web Services et l’accompagnement de Devoteam.
Dans cet article, Laurent Sauvage, responsable du Lab Innovation et Thomas Foucher, Ingénieur IA, répondent à nos questions sur la réalisation de ce projet innovant, et la collaboration avec les équipes de Devoteam sur les sujets d’IA.
Quelles sont les missions du laboratoire ?
Laurent : InnoLab Tech est une équipe d’ingénieurs dont le rôle est de proposer les produits et services de demain. Théoriquement, notre mission est d’aller jusqu’à la mise en place du prototype, puis de passer la main à une autre équipe pour l’industrialisation. Cependant le périmètre évolue, et nous allons parfois jusqu’à la mise en production des projets pour raccourcir le time to market.
Comment concevez-vous les services du futur ?
Laurent : Nous sommes attentifs à la veille technologique. Nous nous intéressons à chaque nouveauté, en évaluant son potentiel pour nos produits et services, qu’ils soient destinés à l’interne ou au grand public. A la sortie de Chat GPT, nous avons regardé de très près les possibilités offertes par les LLM. Contrairement aux projets d’IA classiques, qui demandent un grand volume de données étiquetées, une équipe de spécialistes et beaucoup de temps pour un résultat parfois incertain, les LLM nous permettent de répondre rapidement à de nombreux cas d’usage car ils sont déjà entraînés. C’est comme cela que nous avons imaginé le service “Ensemble ce soir”.
Comment avez-vous choisi de concevoir un service basé sur l’IA générative ?
Thomas : Au départ, notre réflexion était de trouver comment exploiter l’IA générative dans la TV, avec un service destiné au grand public. AWS nous a accompagnés dans cette recherche, sur la partie liée à l’infrastructure, ce qui nous a permis de nous concentrer sur les sujets d’IA.
A quel cas d’usage répond ce service ?
Laurent : Il vise à résoudre un problème récurrent dans les foyers : avec la richesse actuelle des catalogues de SVOD, comment trouver un contenu vidéo (film, documentaire…) qui plaise à l’ensemble des membres de la famille sans y passer trop de temps ? L’idée est de fournir un outil qui permette de réduire le temps passé à trouver un contenu qui convienne à tout le monde, et parvenir à un résultat plutôt que de finir en dispute familiale ! En moyenne, une famille met plus de 20mn à choisir un contenu.
Ensemble ce soir permet de rendre cette recherche ludique, d’en faire un moment agréable, et de parvenir à un résultat en quelques minutes.
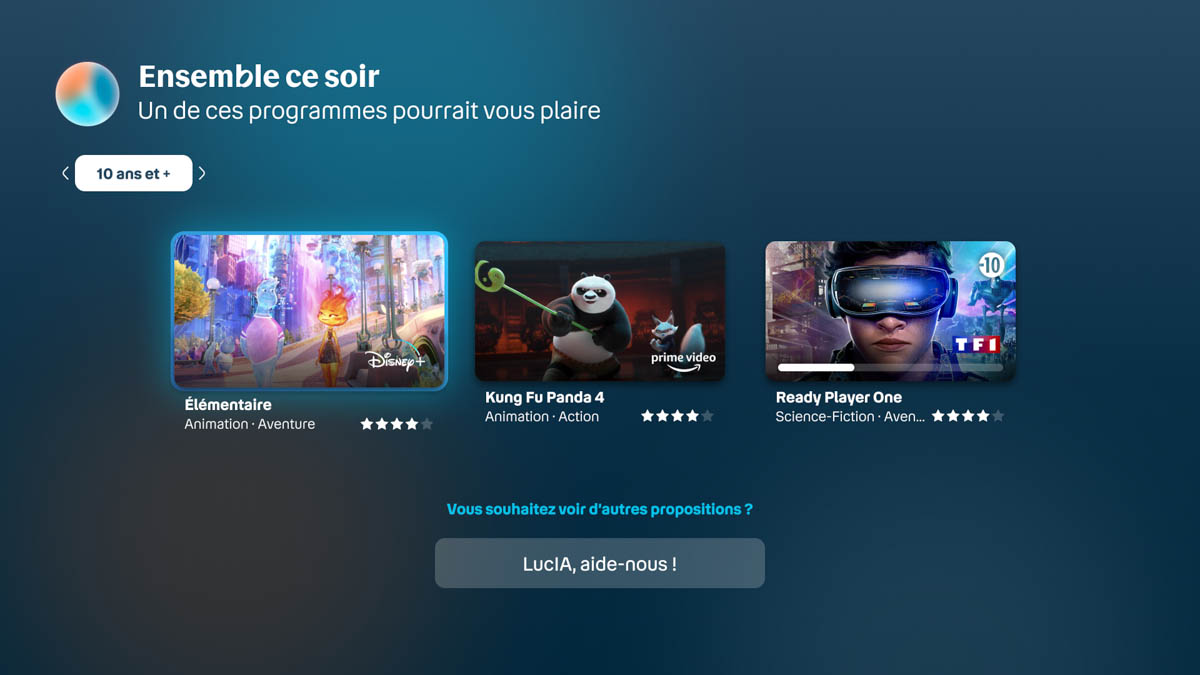
Comment le service fonctionne-t-il ?
Laurent : Une application sur la box permet de lancer le service et ensuite discuter avec une IA selon différentes modalités. On peut utiliser le service avec la télécommande de sa TV, et répondre aux questions de l’IA qui évalue les envies des différents membres de la famille et leur humeur du moment. Avec la télécommande, chaque personne choisit sa réponse parmi des choix prédéfinis. La télécommande est une interface limitée, mais qui permet de récupérer des réponses exploitables.
La véritable expérience utilisateur commence quand l’utilisateur flashe un QR code : il peut alors discuter librement avec l’IA via son smartphone, et exprimer ses envies en langage naturel. L’IA prend ensuite en compte l’ensemble des réponses et des résultats du sondage, et donne ensuite 3 recommandations argumentées. Apporter ces recommandations les plus pertinentes possibles est un vrai challenge, sur lequel nous progressons tous les jours.
Quel environnement technique avez-vous choisi ?
Laurent : Nous avons mené un benchmark des différents LLM disponibles, et nous avons choisi Claude 3 via Amazon Bedrock. C’est un modèle avec un excellent ratio coût/efficacité, et qui nous donne la possibilité d’intégrer les catalogues des différents éditeurs grâce au RAG, pour aboutir aux recommandations. L’application fournit une justification, elle explique pourquoi elle recommande ce contenu : elle ne résume pas le film, mais explique comment il répond aux différentes demandes de la famille.
Thomas : le service fonctionne avec une application Android et une web app qui discutent au travers d’API Gateway. L’API s’interface avec le système d’IA via des Lambdas. Nous utilisons Amazon Bedrock, Haiku de Claude 3, et le système de Knowledge Base pour faire du RAG.
Que vous apporté l’usage d’un service managé comme Amazon Bedrock ?
Thomas : Utiliser Amazon Bedrock nous a fait gagner du temps à un moment où nous avions besoin de tester très vite. Bedrock nous a simplifié la vie, et nous a permis d’accélérer dans la réalisation de la solution
Quels ont été les principaux challenges de ce projet ?
Thomas : La principale difficulté, c’est de réussir à faire discuter une application d’IAG avec le système de recommandation : comment condenser l’information récoltée auprès des utilisateurs, sous plusieurs formes, et faire en sorte qu’elle soit utilisable par le système de recommandation ?
L’IAG comprend très bien le langage, on essaie ensuite de faire matcher le besoin exprimé des utilisateurs avec la base de contenus. A noter que si les utilisateurs ne sont pas forcément d’accord sur leurs envies : potentiellement, on peut avoir une demande à laquelle il est difficile de répondre. C’est vraiment le cœur du sujet, et nous travaillons encore pour l’améliorer.
Quels étaient les enjeux en termes d’interface utilisateur ?
Thomas : Il y a eu beaucoup de réflexion pour faire en sorte que l’usage soit simple et contourner les limites de la télécommande TV. L’IA devient vraiment intéressante quand on peut entrer du texte libre, cependant nous ne voulions pas passer par une application à télécharger. Pour contourner ce problème, nous utilisons un QR Code, qui fluidifie le process pour l’utilisateur. Cela implique aussi des contraintes, un client web est forcément plus limité qu’une application.
Où en êtes-vous aujourd’hui ?
Thomas : Nous avons montré un premier prototype fonctionnel lors du salon Vivatech en mai 2024. Nous en avons ensuite fait un veritable produit, nous avons amélioré la partie recommandations, et après un premier test en interne, nous avons mené en septembre une deuxième phase de test auprès d’un échantillon de clients. Et nous réfléchissons déjà à l’ajout de nouvelles fonctionnalités !
Que retenez-vous de ce projet ?
Thomas : Sur le plan technique, c’est un sujet assez nouveau, et nous avons dû nous montrer inventifs pour faire fonctionner l’interface entre l’IA et le moteur. C’était un travail très intéressant, on a mis en place de nombreuses techniques pour améliorer la recherche dans la base. Quand on parle d’IA, le grand public s’attend à ce que cela soit “magique”, donc les attentes sont hautes ! Nous espérons que les utilisateurs seront bluffés par le résultat.
Nous avons pu nous appuyer sur l’expertise IA de Devoteam pour relever ce challenge et développer ce nouveau service en moins de 3 mois.
Comment Devoteam vous a accompagnés dans ce projet ?
Laurent : Devoteam nous soutient sur ce type de sujets novateurs depuis que nous avons lancé notre programme autour de l’IAG. Nous avons pu nous appuyer sur leur expertise IA pour relever ce challenge et développer ce nouveau service en moins de 3 mois.
Comment avez-vous réparti les tâches entre l’équipe interne et Devoteam ?
Thomas : Les équipes de Devoteam sont complètement intégrées dans le développement, on ne fait pas de différence entre Devoteam et l’interne sur ce projet. La séparation des tâches se fait en fonction des envies de chacun, et de ce qui est plus critique à un instant T. Nous sommes dans un partenariat de confiance avec Devoteam qui dure depuis plusieurs années. Nous avons avancé sur les sujets au même rythme, et nous avons construit ensemble notre connaissance globale de l’IAG. Nous sommes donc complètement alignés dans notre compréhension du sujet, les objectifs, et la façon de travailler pour y parvenir.
Quelle a été la plus value de cet accompagnement ?
Laurent : Il est très appréciable de travailler avec un partenaire qui possède à la fois une maîtrise poussée de l’environnement Cloud, en particulier AWS, et une forte expertise des sujets d’IA et du RAG. Cette combinaison de l’expertise Cloud et IA en font un accompagnement très réussi.
L’expertise apportée par Devoteam nous aide à construire des architectures scalables et robustes, d’aller en production et donc d’accélérer le time to market.
Sur quels autres sujets d’IA travaillez-vous avec Devoteam ?
Laurent : Nous avons développé Lucia, un ChatGPT à usage interne, qui garantit la confidentialité des échanges. Pour ce faire, nous utilisons les API d’OpenAI, de façon sécurisée, avec un hébergement Cloud dédié. C’est un outil qui est largement utilisé en interne, et qui rend service de façon quotidienne à nos collaborateurs.
Nous avons aussi lancé en juillet un service de traduction destiné aux conseillers en boutique. Il se distingue par sa facilité d’usage : chaque interlocuteur discute dans sa langue, sur son smartphone. Là aussi, on lance l’application avec un flashcode, sans installation, et on rejoint la discussion par oral ou par écrit, de façon très simple et naturelle.
Le mot de la fin ?
Laurent : Notre mission initiale est d’aller jusqu’au prototypage, désormais nous menons régulièrement nos projets jusqu’à l’industrialisation. L’expertise apportée par Devoteam nous aide à construire des architectures scalables et robustes, d’aller en production et donc d’accélérer le time to market.

