

Vancelian est une application mobile de gestion de patrimoine. Qu’il s’agisse d’investir, de placer de l’argent, Vancelian propose des solutions d’épargne et d’investissement utilisant des technologies de pointe telles que la blockchain et l’IA. Simple d’utilisation, l’application propose entre autres un robot de trading pour automatiser son investissement.
Afin de répondre à la croissance de sa clientèle, Vancelian a lancé un projet de chatbot basé sur l’IA générative. Plus de clients implique en effet des demandes plus nombreuses et plus fréquentes auprès de l’équipe support, avec potentiellement un risque de goulot d’étranglement dans le traitement des questions. Le chatbot vise donc à assister l’équipe support pour répondre aux questions les plus récurrentes, et ainsi libérer du temps pour traiter des demandes plus complexes. Les équipes de Devoteam ont accompagné Vancelian dans ce projet basé sur Amazon Bedrock et le RAG.
Dans cet article, Remi Gelibert, CTO, et Alexis Segura Architecte Backend & Cloud, répondent à nos questions sur cet outil innovant qui facilite la relation client.

Dans quel contexte avez-vous sollicité l’accompagnement de Devoteam ?
Notre base client a fortement augmentée, cela entraîne une croissance des demandes auprès notre service support. Le support, basé en France, reçoit souvent des questions simples et récurrentes. Afin de faciliter leur traitement, nous avons développé un chatbot qui génère des réponses sur la base de notre FAQ et de la documentation interne.
Pour cette tâche, nous avons demandé à Devoteam de nous accompagner sur la partie Gen AI de ce projet, qui fait appel à Amazon Bedrock et au RAG pour l’ingestion de la documentation.
Comment avez-vous collaboré avec Devoteam ?
Mathieu (Devoteam) a mené un POC en amont du projet.
Nous avons ensuite constitué une équipe mixte : Alexis (Vancelian), en charge de la partie liée à l’outil de support Zendesk, et l’interface entre l’API de réponse et Zendesk, Damien et Alexandre (Devoteam) sur la partie technique GenAI et la création de l’API. Le développement a été organisé en sprints, avec Alexandre en lead, et Damien en ML Ops.
Quel est votre environnement technique ?
Toute notre infrastructure et notre workload sont sur le Cloud AWS. Bedrock étant un service natif AWS, c’était pour nous le choix le plus évident pour répondre à notre besoin. Nous avons utilisé des outils serverless, tels que API Gateway et des fonctions Lambda pour assurer automatiquement l’ingestion et la vectorisation des documents, ainsi que les échanges entre Amazon Bedrock et Zendesk.
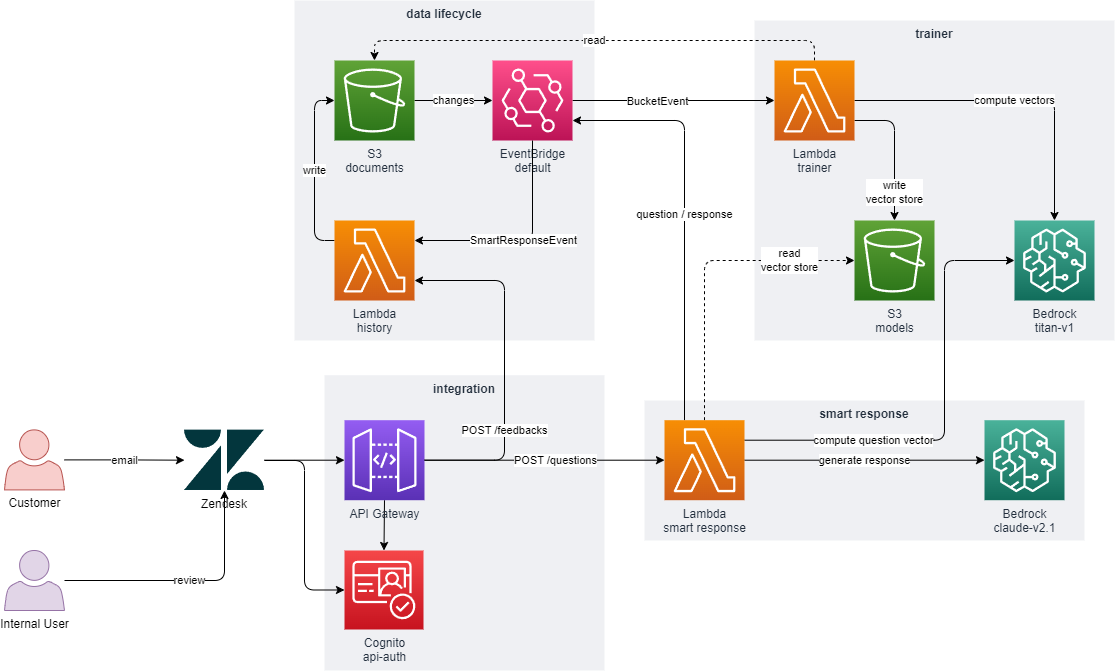
Comment le chatbot a-t-il appris de la documentation et de la FAQ ?
Les consultants Devoteam ont utilisé le pattern RAG pour ingérer de façon régulière et automatisée toute la base de données documentaire et la FAQ du support. Cette base a été vectorisée pour servir de base de connaissance au modèle Claude 3, afin qu’il puisse donner des réponses adaptées, cohérentes et pertinentes.
C’est une étape indispensable car nous sommes sur un domaine très régulé dans lequel nous ne pouvons pas utiliser certains termes ce qui impose beaucoup de vigilance dans la formulation des réponses.
Quel est le workflow suivi par une demande ?
Une requête auprès du support génère un ticket qui est envoyé au chatbot via API Gateway et Lambda. Il fournit sa réponse via l’API, et cette réponse est postée dans un desk, fournissant à l’agent de support des premiers éléments de réponse à donner.
L’agent évalue ensuite la pertinence de la réponse et sa conformité aux obligations réglementaires, la corrige si nécessaire. A la suite de cela, la base vectorielle est reconstruite avec ces corrections pour que le modèle dispose d’une base de connaissance en amélioration continue.
Quels challenges avez-vous rencontré lors du développement ?
Sur la partie GenAI, le plus complexe était d’intégrer la FAQ en 3 langues (anglais, français et italien) et de la vectoriser pour la rendre exploitable de façon automatisée et régulière. L’équipe Devoteam a donc développé des fonctions lambda qui surveillent la mise à jour de la FAQ sur un bucket S3, et qui automatisent le RAG et le prompt engineering pour valoriser certains comportements et en interdire d’autres.
Quelle valeur ajoutée vous a apporté l’accompagnement de Devoteam ?
Comme nous n’avons pas de compétences GenAI en interne, nous voulions être accompagnés par des spécialistes du sujet. Nous voulions aussi un partenaire qui puisse prendre en charge la gestion du projet, et là aussi l’accompagnement était parfait et les sprints très bien organisés. Nous avons juste eu à nous positionner en tant que partie prenante et prendre quelques tâches techniques.
Tout était très bien cadré, avec beaucoup de compétence. Il était aussi très appréciable d’avoir un partenaire qui puisse avancer très rapidement : c’est la première fois que nous travaillons avec un partenaire technique qui nous accompagne au rythme que nous souhaitons.
Quelles sont les prochaines étapes ?
Nous allons maintenant voir comment évolue la notation des réponses du chatbot pour améliorer le prompt engineering. A terme, notre objectif est que le chatbot puisse être directement interrogé par les utilisateurs du site, pour répondre à des questions générales sur l’application, mais aussi à des demandes spécifiques. Par exemple, il pourra aller chercher dans la base de données client une information comme la date d’envoi de sa CB.
Nous restons aussi en veille sur les nouvelles fonctionnalités d’Amazon Bedrock, comme Guardrails, qui permet d’appliquer des garde-fous spécifiques au modèle, ou les Knowledge Bases, qui pourraient aider à simplifier la partie RAG.

