Nous prédisons le futur en permanence dans notre vie quotidienne : en anticipant la trajectoire d’un automobiliste, en cherchant quelle météo il fera, en terminant la phrase d’un ami… Et, pour anticiper, prédire, notre cerveau comprend le monde comme séquences logiques d’événements. En effet, vous avez sans doute déjà essayé de dire une phrase à l’envers. Si c’est difficile au début, après un peu d’entraînement, le cerveau comprend la mécanique à adopter. Les réseaux de neurones récurrents font partie d’une catégorie d’algorithmes basés sur ce concept de mémoire séquentielle pour réaliser des prédictions. Cela peut vous faire penser au thriller des années 2000 de Nolan, Memento, où un homme atteint de graves troubles de l’amnésie ne dispose d’une mémoire à court terme que de 15 minutes. Excellent film pour cet amnésique qui parviendra malgré sa maladie à enquêter sur la mort de sa femme !
Dans cet article, nous allons étudier les réseaux de neurones récurrents, les définir, illustrer leurs différentes architectures en pesant les avantages et inconvénients.

Qu’est-ce qu’un RNN ?
Les réseaux de neurones récurrents (RNR ou RNN : Recurrent Neural Network, en anglais) font partie des algorithmes de deep learning (Pour rappel des principaux concepts en deep learning, vous reportez à notre premier article sur ce sujet : Mieux comprendre le Deep Learning appliqué à la reconnaissance d’images).
Les réseaux de neurones récurrents ont une architecture d’apprentissage profond capable de prédire des séries temporelles ou des séquences.
Cette architecture est largement utilisée dans des applications récentes et dans de nombreux domaines. Nous citons par exemples, la prévision de la météo, l’analyse des prix des actions en bourse, le traitement automatique du langage naturel (NLP) pour faire de la traduction automatique, de la reconnaissance automatique de la parole, de l’analyse de sentiments à partir d’un texte ou d’un fichier audio.
Les réseaux de neurones récurrents sont capables de travailler sur des séries de longueurs quelconques plutôt que sur des entrées de taille figée comme c’était le cas avant l’émergence des RNNs. Pour faire une prédiction performante, comme pour tout algorithme d’intelligence artificielle, les modèles doivent être entraînés sur des données historiques robustes et généralisables.
Principe de fonctionnement des neurones récurrents
Un RNN est très similaire à un réseau de neurones non bouclé classique, dans lequel le flux des activations se dirige dans un sens unique, depuis la couche d’entrée vers la couche de sortie. Son architecture est composée d’une couche d’entrée, de couches cachées et d’une couche de sortie.
En revanche, le RNN se distingue par la capacité de certaines connexions à revenir en arrière dans le réseau.
Expliquons le principe de fonctionnement du RNN à partir d’un RNN constitué par un seul neurone.
Ce neurone reçoit des entrées et produit une sortie. Dans le détail, à chaque étape temporelle t, ce neurone récurrent reçoit le vecteur d’entrée x(t) ainsi que sa propre sortie produite à l’étape temporelle précédente y(t-1). Nous pouvons représenter ce réseau le long d’un axe du temps. On dit alors qu’on a « déplié le réseau dans le temps ».
A chaque étape temporelle t, chaque neurone récurrent reçoit à la fois le vecteur d’entrée x(t) et le vecteur de sortie de l’étape temporelle précédente y(t-1).
Chaque neurone récurrent possède 2 types de poids :
– des poids (notés W sur le schéma ci-dessous) reliant les entrées à la sortie (comme pour un réseau de neurones classique)
– des poids (notés R) entre la sortie et l’entrée de la couche, qui sont les connexions récurrentes.
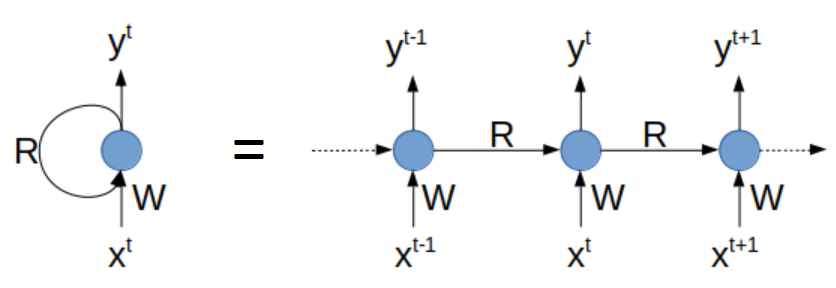
Figure 1 : RNN et sa version « dépliée dans le temps »
(Source : Découvrez le fonctionnement des réseaux de neurones récurrents – Initiez-vous au Deep Learning – OpenClassrooms)
Y(t) est une fonction de X(t) et de Y(t-1), qui est une fonction de X(t-1) et de Y(t-1), qui elle-même est une fonction de X(t-2) et de Y(t-3), … Par conséquent, Y(t) est une fonction de toutes les entrées depuis l’instant t=0. Lors de la première étape temporelle, à t=0, les sorties précédentes n’existent pas (en général, sont supposées nulles).
En fait, la sortie d’un neurone récurrent étant une fonction de toutes les entrées des étapes précédentes, on considère que ce neurone possède une forme de mémoire.
On appelle cellule de mémoire, la partie du réseau de neurones récurrent qui conserve un état entre plusieurs étapes temporelles.
L’état d’une cellule à l’étape t, noté h(t) (h pour « hidden » layer qui signifie couche cachée), est une fonction de certaines entrées à cette étape temporelle et de son état à l’étape temporelle précédente : h(t) = f(h(t-1), x(t)).
La sortie est donc fonction de l’état précédent et des entrées courantes.
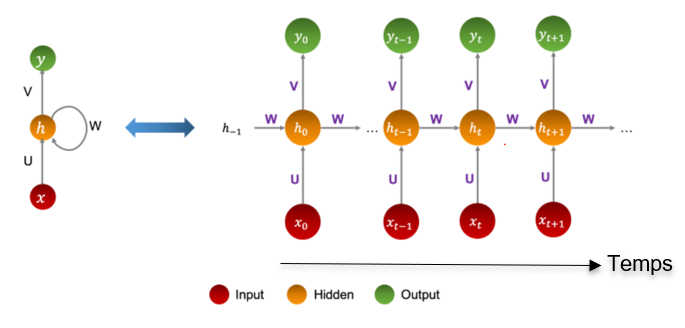
Figure 2 : L’état caché d’une cellule de mémoire (Source : https://ichi.pro)
Nous verrons plus loin que ces cellules peuvent être plus complexes à l’instar des cellules de longue mémoire à court terme que nous retrouvons dans les réseaux portant le même nom LSTM (Long short-term memory).
Propagation-avant
La propagation-avant dans un RNN (« forward propagation » en anglais) comme son nom l’indique est la transmission du flux des activations depuis la couche d’entrée jusqu’à la couche de sortie en passant par les couches cachées. Chaque neurone reçoit l’information, la traite à travers une fonction d’activation afin de casser la linéarité et la passe enfin à la couche suivante.
Les fonctions « tangente hyperbolique » et « sigmoïd » sont les fonctions couramment utilisées pour les RNNs. Comme expliqué précédemment, pour un réseau de neurones non bouclé, chaque liaison entre les neurones est associée à un poids W.
La spécificité des RNNs réside dans le fait que les poids sont égaux pour toutes les couches. Ceci permet de réduire le nombre de paramètres du modèle et ainsi sa complexité.
En premier lieu, un vecteur d’entrée est fourni au réseau. Puis, nous calculons son état en fonction de son entrée et des états précédents. Son état actuel devient alors un état précédent pour l’étape temporelle suivante. Il y a mémorisation et déplacement de l’information dans l’ensemble des couches cachées jusqu’à la couche de sortie.
Une fois tous les états à toutes les étapes temporelles calculés, l’état actuel final est utilisé pour calculer la sortie.
La valeur de la sortie nous sert enfin à calculer la valeur de l’erreur qu’il faudra minimiser.
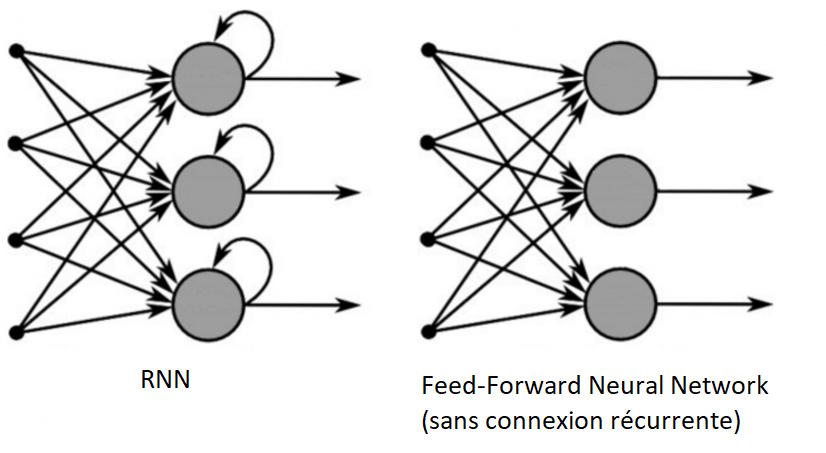
Figure 3 : RNN versus Feed-forward Neural Network (Source : All About Recurrent Neural Network (RNN) – XpertUp)
Quelques techniques pour l’initialisation des poids d’un RNN
Pour qu’un RNN soit efficacement entraîné, et afin d’éviter une mauvaise configuration des poids du réseau, il est important de s’assurer de la bonne initialisation des poids.
Classiquement, il existe différents types d’initialisation d’un modèle de deep learning :
- L’initialisation de He : cette méthode consiste à calculer des valeurs aléatoires qui suivent une distribution gaussienne de probabilité avec valeur moyenne nulle et écart-type égale à 2/n, où n est le nombre d’entrées.
- L’initialisation de Xavier/Glorot : l’initialisation des poids repose sur le calcul des valeurs aléatoires suivant une distribution uniforme de probabilité situées entre -1/n et 1/n, où n est le nombre d’entrées.
Chain rule
Nous l’avons évoqué dans le précédent article, la rétropropagation correspond à la propagation du gradient d’erreur dans tout le réseau, selon deux phases : une phase de propagation-avant et une phase de propagation-arrière.
En fait, après avoir calculé la fonction de coût, l’objectif principal est de minimiser l’erreur. Cela passe par la mise à jour des paramètres (poids et biais) associés à chacune des connexions.
Le cœur de l’algorithme de rétropropagation s’appelle également la « chain rule ». Afin d’ajuster les paramètres du modèle et pour calculer ces gradients, nous utilisons la règle de dérivation en chaîne. Cette technique consiste à dériver une fonction composée qui traduit la relation entre les neurones du réseau et permet d’obtenir le gradient de la fonction d’erreur par rapport à chaque poids. Nous pouvons ainsi mesurer l’influence de chaque paramètre et le mettre à jour ce qui permettra de minimiser la perte de la fonction d’erreur.
Des cycles de propagation-avant et de rétropropagation se produisent autant que nécessaire jusqu’à atteindre le minimum global de la fonction d’erreur.
Différents types de RNNs
Les réseaux de neurones récurrents sont capables de gérer plusieurs types de données en entrée comme en sortie.
- Le réseau de neurones récurrents « one-to-one » correspond à un RNN prenant un vecteur x(t) en entrée et retournant une seule sortie y(t).
- Le réseau de neurones récurrents « one-to-many » est un modèle capable de renvoyer une série de vecteurs en sortie pour un seul vecteur d’entrée.
Exemple : algorithme de génération de phrases capable de continuer l’écriture d’un texte. - Le réseau de neurones récurrents « many-to-one » (aussi appelé « sequence to vector model») est un modèle utilisé pour générer un vecteur de sortie unique à partir d’une série d’entrées. C’est un modèle utilisé principalement dans des applications d’analyse des sentiments.
Exemple : analyse de l’intention d’une phrase, c’est-à-dire dire si la phrase a une connotation positive ou négative. - Le réseau de neurones récurrents « many-to-many » (aussi appelé « sequence to sequence model ») est un modèle utilisé pour renvoyer des séquences de vecteurs en sortie à partir d’une séquence de vecteurs en entrée. Ce type de RNN prend une série d’entrées et produit une série de sorties. On utilise cette topologie de RNN pour prédire des séries chronologiques (le prix d’une action en bourse). On fournit les valeurs sur les N derniers jours et le RNN produit les valeurs décalées d’un jour dans le futur.
Exemple : algorithme de traduction d’une langue vers une autre. - Variante « many-to-many » : ce type de modèle peut avoir une autre représentation, cette fois-ci synchronisée. Cela signifie que chaque vecteur de la séquence d’entrée le modèle génère, au fur et à mesure, un vecteur de sortie.
Exemple : algorithme de labellisation des images d’une vidéo.
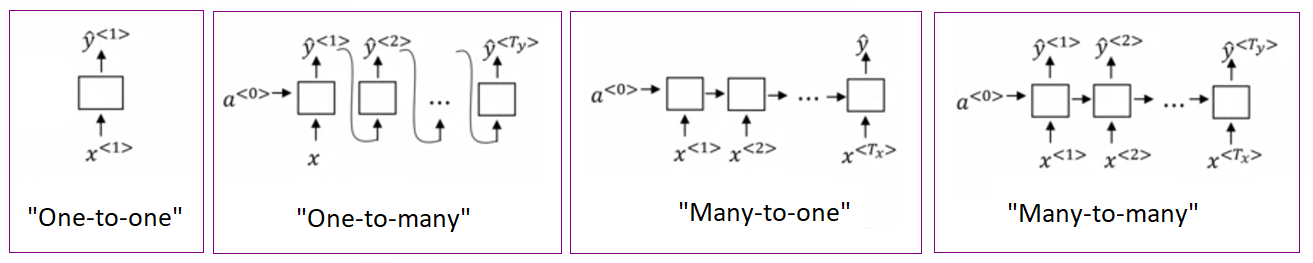
Figure 4 : Résumé des principaux modèles de RNNs
Avantages/Inconvénients
|
Avantages (+) |
Inconvénients (-) |
|
+ Capacité à modéliser et prédire à partir de séquences de longueurs variables |
– Disparition/Explosion des gradients de la fonction de coût (erreur) |
|
+ Exécution rapide des modèles |
– Impossibilité de réaliser le traitement de séquences de très grandes tailles. Temps d’entraînement extrêmement long. |
|
+ Utilisation modérée des ressources |
– Problème lié à la mémoire courte des RNNs : les premières entrées disparaissent progressivement. La traversée du réseau favorise la perte des informations à chaque étape temporelle. Au bout d’un certain temps, l’état du RNN ne contient quasiment plus de traces des premières entrées. |
Solutions courantes : Transformers
Le LSTM (Long Short-Term Memory)
Le LSTM (Long Short-Term Memory), cellule de longue mémoire à court terme est un RNN particulier qui permet de pallier aux problèmes liés à la disparition/explosion du gradient et à celui de la mémoire courte des RNNs.
Nous pouvons utiliser des réseaux de longue mémoire pour traiter de longues séquences et ces modèles sont généralement plus rapides à entraîner avec des performances bien meilleures qu’un RNN de base.
Le principe de fonctionnement est le suivant : le LSTM apprend ce qu’il faut stocker dans l’état à long terme, ce qui peut être oublié par le réseau et ce qu’il faut y lire.
Le parcours de l’état à long terme au travers du réseau va de la gauche vers la droite. Il passe d’abord par une porte logique dite d’oubli (qui laisse de côté certaines informations), puis en ajoute de nouvelles par opération d’addition. Les informations ajoutées sont sélectionnées par la porte d’entrée et le résultat est directement envoyé sans transformation.
La porte de sortie filtre le résultat via une fonction d’activation.
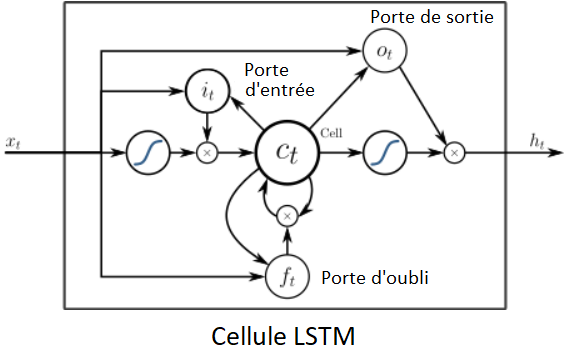
Figure 5 : Architecture du LSTM (Source : Long short-term memory – Wikipedia)
Au niveau de l’architecture, 4 couches sont intégralement connectées :
▪ une couche principale qui joue le rôle d’analyse des entrées courantes et de l’état précédent.
▪ 3 couches qui jouent le rôle de contrôleur des portes avec :
▪ une porte d’oubli qui décide des parties de l’état à long terme qui doivent être effacées.
▪ une porte d’entrée qui décide de l’addition des parties à ajouter à l’état long terme du réseau
▪ une porte de sortie qui sélectionne les parties de l’état à long terme qui doivent être lues.
Le modèle GRU
Le modèle GRU est une deuxième solution optimisant le fonctionnement des RNNs classiques.
La cellule d’unité récurrente à porte (GRU, Gated Recurrent Unit) est une version simplifiée de la cellule LSTM. Ces performances sont bonnes et quelques simplifications sont à noter par rapport au LSTM :
- un seul contrôleur de porte gère l’oubli et l’entrée.
- la porte de sortie n’existe plus : le vecteur d’états complet est sorti à chaque étape temporelle.
Nous avons vu rapidement les modèles LSTM et GRU dans cet article. Ils ont énormément contribué au succès de RNNs en les rendant extrêmement populaires ces dernières années.
Nous avons pu nous familiariser avec les réseaux de neurones récurrents et leurs différents aspects techniques.
Afin d’aller plus loin dans les notions, nous vous invitons à lire prioritairement l’ouvrage : TensorFlow et Keras ; l’intelligence artificielle appliquée à la robotique humanoïde, Henri Laude, Collection Eni Epsilon. Ce livre propose une initiation aux outils mathématiques de référence pour faire du deep learning. En fin d’ouvrage, un chapitre est consacré à l’exploitation et la mise en œuvre de RNN avec les frameworks TensorFlow et Keras. Vous aurez également accès à des liens vers du code tiers répertorié sur GitHub.
Dans cette même logique d’approfondissement de vos connaissances sur le sujet, nous vous recommandons les livres suivants :
▪ L’Intelligence Artificielle pour les développeurs. Concepts et implémentations en Java, Virginie Mathivet, Collection Eni (2e édition).
▪ Intelligence artificielle vulgarisée. Le Machine Learning et le Deep Learning par la pratique, Aurélien Vannieuwenhuyze, Collection Eni.
Soulignons également que nous proposons deux webinars autour du deep learning appliqué à la reconnaissance d’images, pour mieux comprendre ce qu’est le deep learning. Nous proposons également un itinéraire de formations sur le NLP. Ce sujet fera l’objet du prochain article.

