Les réseaux de neurones RNNs dont les LSTMs (Hochreiter et Schmidhuber, 1997) et GRUs (Chung et al., 2014), ont été fermement établis comme des approches de pointe dans la modélisation de séquences et les problèmes de transduction tels que la modélisation du langage et la traduction automatique. Nous vous conseillons vivement de vous reporter à notre précédent article : Aller plus loin en deep learning avec les réseaux de neurones récurrents (RNNs) pour plus d’informations.
De nombreux efforts ont depuis permis de repousser les limites des modèles de langage récurrents et des architectures codeurs-décodeurs.
Les modèles récurrents (RNNs) génèrent une séquence d’états cachés, fonction de l’état caché précédent et de l’entrée pour la position actuelle. Cette nature intrinsèquement séquentielle empêche la parallélisation dans les exemples d’apprentissage, qui devient critiques à des séquences plus longues, car les contraintes de mémoire limitent le traitement par lots (batch). De plus, lorsque les séquences sont trop longues, le modèle a tendance à oublier le contenu des mots distants ou à le mélanger avec le contenu des mots suivants. Par exemple, plus on s’éloigne du sujet, plus il est difficile de savoir s’il est au singulier ou au pluriel. Et enfin, pour les longues séquences, le problème dit des “vanishing gradients” peut apparaître. Ces modèles ont généralement une structure encodeur-décodeur. L’encodeur mappe une séquence d’entrée de représentations de mots à une séquence de représentations continues. Le décodeur génère ensuite une séquence de sortie de mots, un élément à la fois. Dans l’encodeur, l’état caché à chaque étape est associé à un certain mot dans la phrase d’entrée, généralement l’un des plus récents. Par conséquent, si le décodeur accède uniquement au dernier état caché du décodeur, il perdra les informations pertinentes sur les premiers éléments de la séquence.

Les modèles d’Attention sont devenus l’une des solutions pour surmonter le problème de l’oubli des modèles. En effet, ils permettent la modélisation des dépendances sans tenir compte de leur distance dans les séquences d’entrée ou de sortie. Plus particulièrement, un Transformer est une nouvelle architecture qui vise à résoudre des tâches “séquence à séquence” tout en gérant facilement les dépendances à longue portée. Il repose entièrement sur le “Self-Attention” pour calculer les représentations de son input et de son output sans utiliser les modèles récurrents. De plus, il permet une parallélisation beaucoup plus importante en introduisant la notion de Multi-Head Self-Attention (Wolf et al., 2020 ; Khan et al., 2021). Nous allons voir ces notions dans cet article.
Les Transformers fournissent des milliers de modèles pré-entraînés pour effectuer des tâches sur des textes (classification, l’extraction d’informations, la réponse aux questions, le résumé d’information, la traduction, la génération de texte et plus encore dans plus de 100 langues). Parmi ces modèles, les plus populaires sont BERT (Devlin et al., 2018), GPT v1-3 (Radford et al., 2018), RoBERTa (Liu et al., 2019) et T5 (Raffel et al., 2019). L’impact profond des modèles Transformer est devenu plus clair avec leur évolutivité vers des modèles de très grande capacité. Par exemple, le modèle BERT-large avec 340 millions de paramètres a été largement surpassé par le modèle GPT-3 qui a plus de 175 milliards de paramètres tandis que le dernier transformateur Switch de Google s’adapte à 1,6 milliards de paramètres ! Dans cet article, nous nous concentrerons sur l’article
principal qui a tout déclenché : Attention Is All You Need (Vaswani et al., 2017).
Qu’est-ce que l’Attention?
L’Attention permet de se concentrer sur des parties de la séquence d’entrée pendant que le modèle prédit la séquence de sortie. Par exemple, si le modèle a prédit le mot “Cerise”, nous sommes très susceptibles de trouver un poids élevé pour les mots “rouge” et “fruit” dans notre séquence d’entrée. L’Attention, d’une certaine manière, permet de tracer une certaine connexion/corrélation entre des mots d’entrée et des mots de sortie.
Il existe trois types d’Attention :
- Attention Encodeur-Décodeur : Attention entre la séquence d’entrée et la séquence de sortie;
- Self-Attention dans la séquence d’entrée : c’est un mécanisme reliant différentes positions d’une même séquence d’entrée afin de calculer une représentation de la séquence. En termes plus simples, le Self-Attention aide à créer des connexions similaires mais au sein de la même séquence ;
- Self-Attention masquée dans la séquence de sortie : la portée du Self-Attention est limitée aux mots qui se produisent avant un mot donné. Cela évite toute fuite d’informations lors de l’apprentissage du modèle. Cela se fait en masquant les mots qui se produisent après et ce pour chaque étape. Ainsi pour l’étape 1, seul le premier mot de la séquence de sortie n’est pas masqué, pour l’étape 2, les deux premiers mots ne sont pas masqués et ainsi de suite.
Le calcul de l’Attention peut se faire à l’aide de trois matrices : Clés, Valeur et Requête (en anglais : Key, Value et Query), calculées en multipliant le vecteur d’entrée X avec des matrices de poids qui sont apprises pendant l’entraînement. Chaque colonne des matrices fait référence à un mot de la séquence.
Où dk représente la dimension des matrices Q et K. Ce calcul cherche à trouver la similarité entre Q et K via le produit scalaire de la requête avec toutes les clés, suivie d’un softmax. Plus le produit est élevé, plus la similarité est forte. Ce produit est ensuite multiplié par les valeurs de V. Les valeurs multipliées par un grand softmax recevront plus d’attention que les autres.
Les modèles Transformers
L’architecture globale du Transformer, illustrée sur la figure ci-dessous, est basée sur un Self-Attention empilé et des couches (layers) entièrement connectées (Feed Forward) pour l’encodeur et le décodeur (Vaswani et al., 2017).
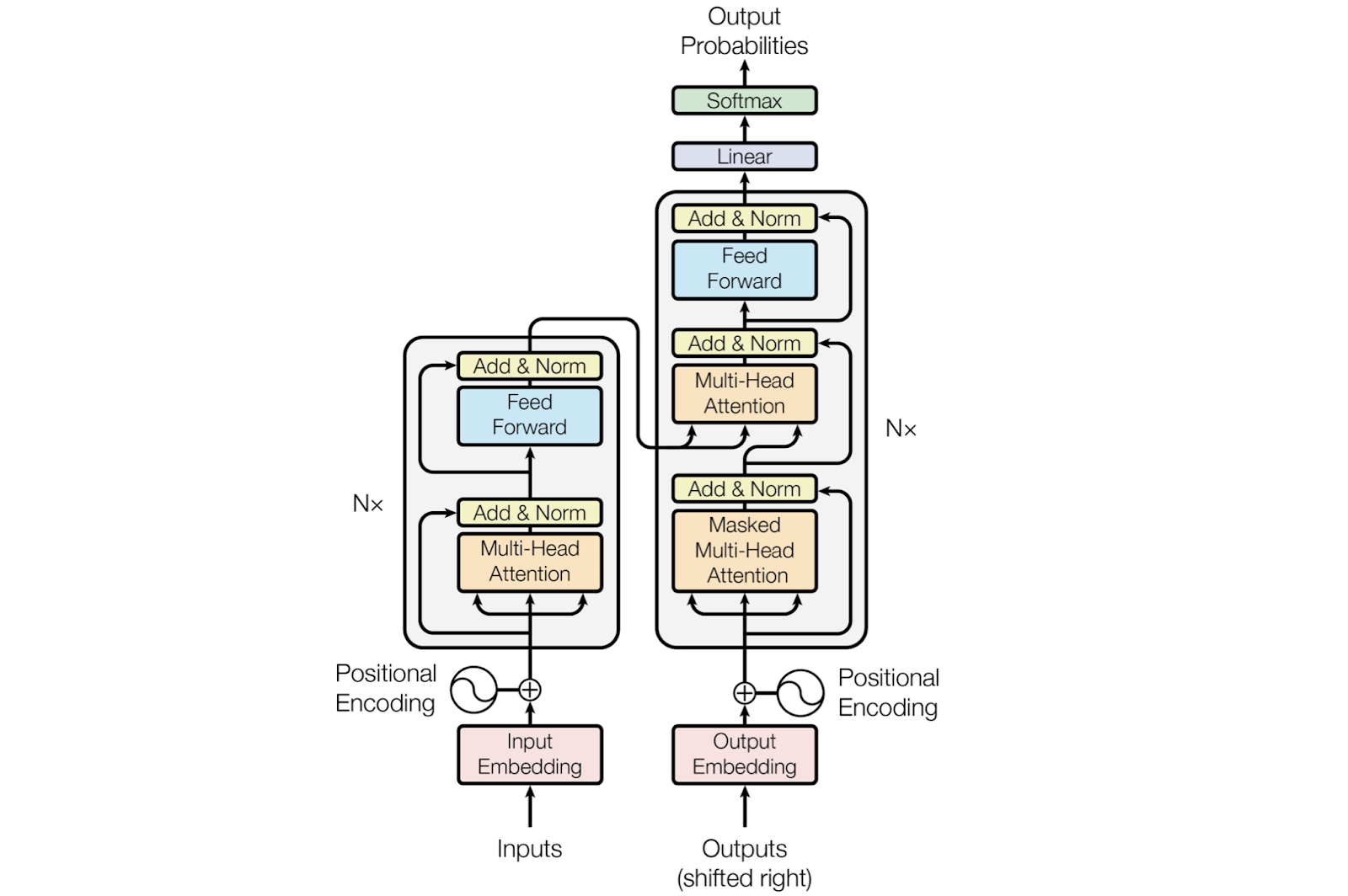
Figure 1 : Le transformateur – architecture générale (Source : Vaswani et al., 2017)
Sur la figure ci-dessus, l’encodeur est à gauche et le décodeur est à droite. Ils sont tous les deux composés de modules qui peuvent être empilés les uns sur les autres N fois. Nous voyons que les modules sont principalement constitués de couches : Multi-Head Attention et Feed Forward.
À un niveau élevé, l’encodeur mappe une séquence d’entrée dans une représentation continue abstraite qui contient toutes les informations apprises de cette entrée. Le décodeur prend ensuite cette représentation continue et génère étape par étape une sortie unique tout en étant également alimenté par la sortie précédente. Dans ce qui suit, nous allons présenter la procédure pas à pas.
Couche d’encodeur
Nous avons maintenant la couche d’encodeur. Il contient deux sous-couches :
- un Multi-Head Attention ;
- un réseau Feed Forward.
Il existe également des connexions résiduelles autour de chacune des deux sous-couches suivies d’une normalisation de couche (pour accélérer l’apprentissage des réseaux de neurones).
Nous pouvons en plus empiler l’encodeur N fois (la sortie d’un encoder sera l’entrée de l’encoder suivant) pour coder davantage les informations, où chaque couche a la possibilité d’apprendre différentes représentations de l’attention, augmentant ainsi potentiellement la puissance prédictive du réseau de transformateurs.
Input Embeddings et Positional Encoding (connexion résiduelle)
La première étape, Input Embeddings, consiste à envoyer l’entrée dans une couche embedding layer: chaque mot est représenté par un vecteur avec des valeurs continues.
L’étape suivante, “Positional Encoding”, consiste à injecter des informations de position dans les embeddings. Les Embeddings représentent un jeton de dimension d, où les jetons ayant une signification similaire seront plus proches les uns des autres. Mais les Embeddings n’encodent pas la position relative des jetons dans une phrase. Ainsi, après avoir ajouté le Positional Encoding, les jetons seront plus proches les uns des autres en fonction de la similitude de leur signification et de leur position dans la phrase.
Une façon de faire est d’utiliser les fonctions sinus et cosinus. Pour chaque indice pair (respectivement impair) sur le vecteur d’entrée, nous créons un vecteur à l’aide de la fonction sinus (respectivement cosinus). Nous additionnons ensuite ces vecteurs à leurs Input Embeddings correspondants. La formule de calcul du Positional Encoding est la suivante :

où pos est la position et i est la dimension.

Figure 2 : Positional Encoding (script Python)
Multi-Head Attention
Le Multi-headed Attention dans l’encodeur applique un mécanisme de Self-Attention. Pour en faire, il faut couper (horizontalement) les matrices Requête, Clé et Valeur en h matrices avant d’appliquer le Self-Attention aux matrices tranchées. Les matrices obtenues sont concaténées en une seule matrice avant de passer à la couche linéaire finale (multiplier par une matrice de poids supplémentaire).

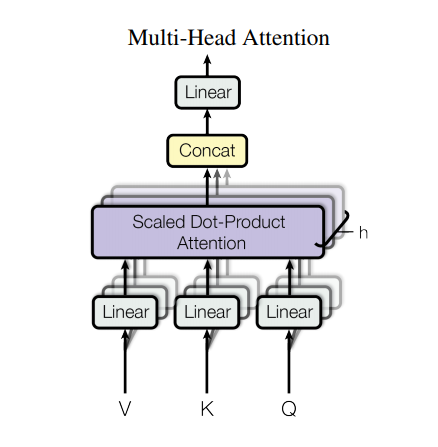
Figure 3 : Multi-Head Attention (Source : Vaswani et al., 2017)
La matrice de sortie du Multi-Head Attention est sommée au Positional Input Embedding initial (connexion résiduelle), puis passe par une couche normalisation.

Figure 4 : Scaled dot product Attention (script Python)
Réseau Feed Forward
Le réseau Feed Forward est constitué de deux couches linéaires avec une activation ReLU entre les deux.
FFN(x) = max(0, xW1 + b1)W2 + b2.

Figure 5 : Réseau Feed Forward (script Python)
La sortie de celui-ci est ensuite à nouveau additionnée à l’entrée du réseau puis normalisée. Les connexions résiduelles aident à éviter le problème dit des vanishing gradients dans les réseaux profonds. Les normalisations de couches sont utilisées pour stabiliser le réseau, ce qui réduit considérablement le temps d’apprentissage nécessaire. Le réseau Feed forward est utilisé ensuite pour projeter les sorties d’attention en lui donnant potentiellement une représentation plus riche.
La sortie de l’encodeur est ensuite transformée en un ensemble des vecteurs d’attention K et V. Ceux-ci doivent être utilisés par chaque décodeur dans sa couche Encoder-Decoder Attention qui aide le décodeur à se concentrer sur les endroits appropriés dans la séquence d’entrée (voir le paragraphe suivant).

Figure 6 : Couche Encoder (script Python)
Couche du décodeur
Le décodeur est constitué de trois sous-couches :
- Multi-Head Attention masqué ;
- Multi-Head Encoder-Decoder Attention ;
- Réseau Feed Forward.
Chacune de ces sous-couches est suivie d’une connexion résiduelle et une normalisation. Le décodeur est bouclé d’une couche linéaire qui agit comme un classificateur et d’un softmax pour obtenir les probabilités d’un mot.
Le décodeur est autorégressif, il commence par un jeton de démarrage et prend en entrée une liste des sorties précédentes, ainsi que les sorties du codeur qui contiennent les informations d’Attention de l’entrée. Le décodeur arrête le décodage lorsqu’il génère le jeton de fin.
Classificateur linéaire et softmax final pour les probabilités de sortie
La sortie de la couche Feed Forward passe par une couche linéaire qui agit comme un classificateur. Le classificateur est aussi grand que le nombre de classes que nous avons. Enfin, une couche softmax, qui produira des scores de probabilité. Nous prenons l’indice du score de probabilité le plus élevé, et cela équivaut à notre mot prédit.
Le décodeur prend ensuite la sortie, l’ajoute à la liste des entrées du décodeur et continue à décoder à nouveau jusqu’à ce qu’un jeton soit prédit. Dans notre cas, la prédiction de probabilité la plus élevée est la classe finale qui est attribuée au jeton de fin.

Figure 7 : Couche Decoder (script Python)
GPT and BERT
Nous ne pouvions pas parler de NLP sans évoquer les modèles GPT et BERT qui démontrent l’efficacité des modèles Transformer. Ces modèles sont efficaces sur des tâches d’analyse de texte spécifiques et utilisent des modèles de langage pré-entraînés sur des corpus à grande échelle.
GPT (Radford et al., 2018) utilise une variante de l’architecture Transformer. C’est-à-dire qu’il utilise un modèle de langage basé sur un décodeur multicouche (12 couches dans l’article original). Chaque bloc a une taille cachée de 768 et 12 Multi-Head-Attention. Les poids sont entraînés sur BooksCorpus.
BERT (Devlin et al., 2018) est un encodeur bidirectionnel multicouche. L’article original fournit deux structures BERT : BERT-Base, se compose d’un bloc de l’encodeur bidirectionnel à 12 couches avec une taille cachée de 768 et 12 Multi-Head-Attention ; BERT-Large comprend des blocs d’encodeur bidirectionnel à 24 couches avec une taille cachée de 1024 et 16 Multi-Head-Attention. Les poids sont entraînés sur BooksCorpus et Wikipedia anglais.
Les deux modèles GPT et BERT utilisent pratiquement la même architecture. En fait, GPT et BERT-Base utilisent le même nombre de couches et de dimensions. La seule différence est que BERT est bidirectionnel car il essaie de remplir des mots individuels en fonction de leur contexte, alors que GPT utilise des têtes de Self-Attention masquées.
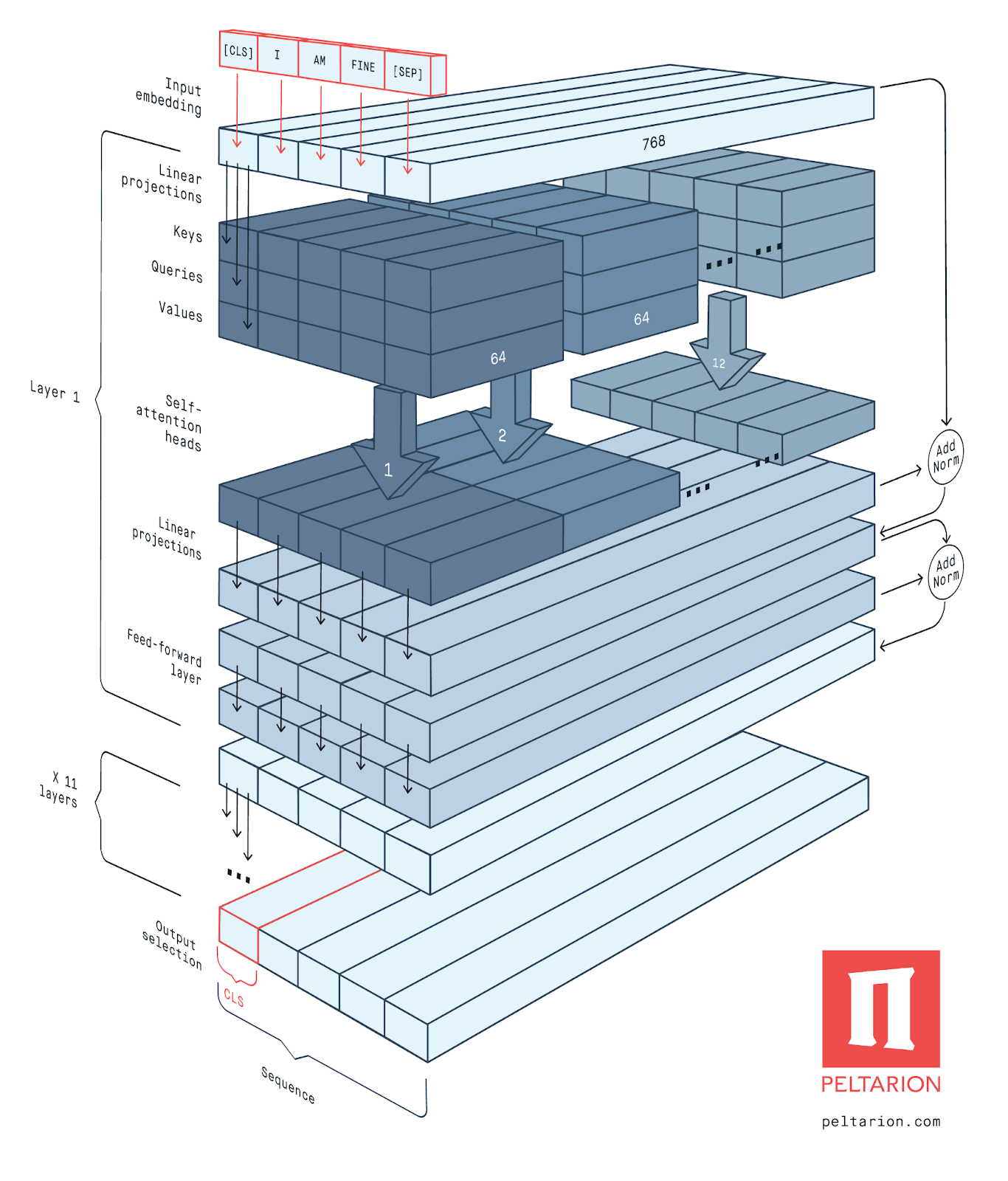
Figure 8 : Architecture générale de BERT (Source : Peltarion, 2020)
Les Transformers exploitent la puissance du mécanisme d’Attention pour faire de meilleures prédictions. Les réseaux de neurones récurrents essaient de réaliser des choses similaires mais souffrent d’une mémoire à long terme défaillante. Les Transformers peuvent être meilleurs, surtout si l’utilisateur souhaite encoder ou générer de longues séquences. Pour les tâches de traduction, le Transformer peut être entraîné beaucoup plus rapidement que les architectures basées sur des couches récurrentes ou convolutives (Wolf et al., 2020 ; Khan et al., 2021).
L’architecture Transformer remplace les cellules RNNs par des couches de Self-Attention et de modèles Feed Forward, qui sont hautement parallélisables et donc moins chères à calculer. Avec l’encodage positionnel, les Transformers sont capables de capturer des dépendances à longue portée avec des positions de jetons relatives vagues.
Nous avons conscience que cet article est compliqué et, pour approfondir vos connaissances, nous vous invitons à relire les articles autour du deep learning de notre blog et à parcourir les publications proposées tout au long de cet article. N’hésitez pas à consulter les articles suivants sur notre blog :
- Mieux comprendre le Deep Learning appliqué à la reconnaissance d’images
- Aller plus loin en deep learning avec les réseaux de neurones récurrents (RNNs)
Références :
- (Chung et al., 2014) Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555.
- (Devlin et al., 2018) Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- (Hochreiter et Schmidhuber, 1997) Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
- (Khan et al., 2021) Khan, S., Naseer, M., Hayat, M., Zamir, S. W., Khan, F. S., & Shah, M. (2021). Transformers in vision: A survey. arXiv preprint arXiv:2101.01169.
- (Liu et al., 2019) Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692
- (Peltarion, 2020) English BERT. https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/blocks/english-bert
- (Radford et al., 2018) Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
- (Raffel et al., 2019) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
- (Vaswani et al., 2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
- (Wolf et al., 2020) Wolf, T., Chaumond, J., Debut, L., Sanh, V., Delangue, C., Moi, A., … & Rush, A. M. 2020, October. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 38-45).

