Un article rédigé par Alexis Mckenzie qui nous a très aimablement autorisé à le traduire.
Cet article a été originellement publié ici : https://towardsdatascience.com/a-data-mesh-approach-to-data-warehousing-cd71e55490ba
Nous nous penchions dans un premier article sur les fondamentaux du Data Mesh, ses avantages et ses inconvénients. Quelle approche du Data Mesh appliquer pour l’entreposage de données ? Et comment migrer ? Quelques éléments de réponse et des conseils dans ce second article consacré à cette stratégie décentralisée de gestion des données.
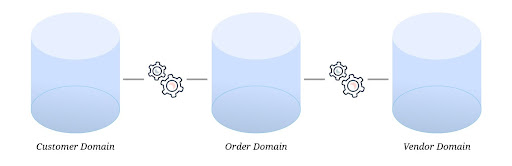
Image par l’auteur et John Do
L’autre objectif et bénéfice clé de l’adoption du Data Mesh est la désignation de points d’intégration clairs entre les domaines (l’élément interopérable des principes FAIR). On peut alors utiliser une table d’intégration ou un endpoint d’API, mais il peut également être intégré dans des tables de faits exposées en tant qu’API ou planifiées à l’avance. Par exemple, pour connecter votre domaine client à votre domaine commande, vous devez inclure un identifiant client dans le table des faits qui résume les détails de votre commande. Vous pouvez également choisir de l’inclure dans votre tableau de commande principal pour mieux lier les informations du client à celles de la commande (pas seulement les informations les plus macros).
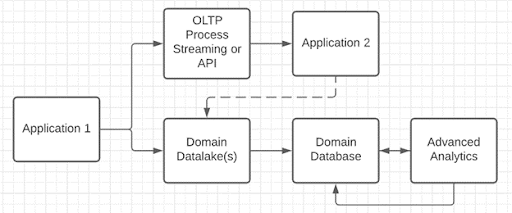
Image par l’auteur
Le schéma ci-dessus montre comment les transactions doivent être séparées de l’analyse pour garantir la conformité ACID et la robustesse des systèmes analytiques (on en reparle ci-dessous). ACID signifie atomicité, cohérence, isolation et durabilité… C’est une grille de compréhension clé dans le domaine des bases de données.
Une certaine approche du Data Mesh pour l’entreposage de données
Et si je veux des données rapides à différents niveaux de granularité ? Mon point de vue c’est que l’on peut utiliser le Data Mesh différemment. Je propose que nous n’abandonnions pas le Data Warehouse mais que nous créions plutôt des entrepôts de données orientés domaine qui capturent le plus petit grain de données disponible. Si vous travaillez avec un système conçu pour le e-commerce, vous souhaitez idéalement stocker toutes les mises à jour et modifications de la commande, pas seulement son statut actuel. Ce dernier peut être stocké dans une table de faits, et toutes ces données peuvent être consommées soit directement à partir de la table, soit dans une API. Même si les datas sont consommées directement à partir de la base de données, les réplicas en lecture peuvent s’avérer utiles pour améliorer les performances de lecture, car le réplica ne sera pas en concurrence avec la base de données principale. Les répliques en lecture ne sont pas exactement en temps réel, mais elles ont tendance à être cohérentes avec une latence à un chiffre en millisecondes, ce qui les rend suffisamment proches du temps réel pour répondre à la plupart des besoins de l’entreprise.
Les API à elles seules ne font pas une stratégie data, mais elles sont un pilier incontournable d’une stratégie de données robuste. Les approches API-first et API-only commencent par la mauvaise question ; elles demandent de déplacer des données sans poser la question de savoir si elles le devraient. Sans analyse préalable, il est difficile de concevoir comment vous devez faire les choses ou si l’application que vous cherchez à créer a du sens. Il est plus facile de prendre une base de données et de la transformer en API que l’inverse. Si vous souhaitez un jour obtenir des informations à partir de vos données, l’API-first et API-only ne sont pas les voies à suivre. Les API permettent aux applications de communiquer entre elles, donc API-first équivaut à application-first. Les API fournissent des données là où elles ne peuvent pas être utilisées à des fins analytiques, sans les déplacer dans un autre Data Product. Les API peuvent manquer d’efficacité et de performance en cas de besoin de calcul complexe, elles sont donc loin d’être une stratégie de données complète.
Les bases de données offrent une stabilité et une capacité de stockage pour contenir toutes les données dans un domaine particulier, telles que les commandes. Vous pouvez actuellement avoir plusieurs bases de données contenant des informations sur les commandes, mais cela vaut la peine de faire l’effort de les consolider pour éviter les transformations destructrices. Les transformations destructrices sont des transformations de données qui entraînent de la perte d’informations. Par exemple, si vous agrégez vos données de commande pour n’inclure que le statut actuel, en ignorant toutes les modifications de commande intermédiaires, vous masquez certaines données qui pourraient être utiles.
Un élément essentiel dans mon approche alternative au Data Mesh est qu’au niveau du Data Warehouse, les datas doivent exister au niveau de granularité le plus fin, en existant selon les besoins dans des tables de fait. Aussi, appliquer l’approche Produit aux données présentes dans des composants plus modulaires que l’EDW traditionnel est une clé de succès. Consolider ses bases de données de cette manière permet de rendre agiles les datas autant que possible. Si une colonne doit par exemple être ajoutée pour une raison quelconque, c’est assez simple à faire. Le développement de la base de données et de l’API doivent être réalisés en parallèle pour s’assurer que tous les prérequis sont en place et que le cycle de développement est aussi rapide que possible.
J’ai vu des bases de données beaucoup trop enchevêtrées, mais si un effort concerté est fait pour exclure les bases de données historiques “legacy” (ce qui est tout à fait possible), l’entreprise peut s’adapter plus facilement. Appliquer le Data Mesh aux Data Warehouses peut aider à contenir systématiquement les anciens EDW.
Il convient également de noter (pour défendre l’argument selon lequel les API seules ne sont pas une stratégie de données) que tous les outils de BI sur le marché nécessitent une connexion à une base de données ou peuvent avoir un connecteur API insuffisant. S’ils disposent d’un connecteur API, ils ont tendance à ne pas être aussi performants en raison des délais de réponse liés aux connexions. Mais, même si vous créez vos propres sockets pour diffuser des données de manière fiable, les API doivent correspondre aux schémas de table pour la cohérence des données et la facilité d’utilisation. Les API REST sont un volet important de la stratégie de données car elles favorisent la sécurité, sont indépendantes de la technologie utilisée et peuvent être mises en cache et mises à l’échelle via l’utilisation d’un bastion ou d’un proxy inverse.
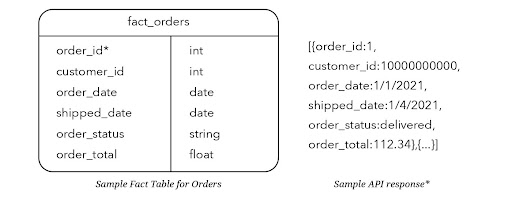
Image par l’auteur
*Cette API renverrait des données dans le même schéma que la table fact_orders, mais il pourrait également y avoir un paramètre pour sélectionner des commandes individuelles au lieu de simplement extraire toutes les données disponibles.
Comment migrer ?
Attachez-vous ! Ce n’est pas aussi complexe qu’il n’y paraît. Quelques étapes clés :
- Documentez vos systèmes actuels et les domaines qu’ils contiennent à un niveau élevé
- Ré-affectez la propriété des anciens EDW, au niveau du schéma sur les nouveaux systèmes
- Définissez clairement la répartition des responsabilités, quels Data Engineers pour quels domaines de données ?
- Soyez à l’aise avec l’idée de données dupliquées sur différents domaines. La duplication doit être minimisée, mais ce n’est pas la peine d’engager des ressources pour quelques colonnes qui pourraient être utilisées légèrement différemment dans différents domaines.
Les Data Engineers doivent discuter ouvertement de la granularité de données avec les parties prenantes et inclure le lignage au niveau du chargement. Construire le lignage est souvent aussi simple que de créer une colonne « source » ; dans de nombreux cas, les données historiques et nouvelles devront être utilisées ensemble, mais raffinées différemment. La provenance des données devrait être aussi transparente que possible pour améliorer efficacement leur qualité.
C’est beaucoup de travail de migrer un système legacy vers un (ou plusieurs) Data Mesh piloté par domaine, mais ça en vaut la peine. Les données n’ont pas besoin d’être une bataille perpétuelle. Toutes les entreprises peuvent prendre des mesures pour résoudre leurs problématiques data grâce à ce processus.
Nous avons choisi d’aller sur la Lune. Nous avons choisi d’aller sur la Lune au cours de cette décennie et d’accomplir d’autres choses encore, non pas parce que c’est facile, mais justement parce que c’est difficile. Parce que cet objectif servira à organiser et à offrir le meilleur de notre énergie et de notre savoir-faire, parce que c’est le défi que nous sommes prêts à relever, celui que nous refusons de remettre à plus tard, celui que nous avons la ferme intention de remporter, tout comme les autres.. — JFK
Tout comme aller sur la lune dans les années 1960, mettre de l’ordre dans vos données d’entreprise est complexe mais nécessaire. Cela demande un effort initial important, mais c’est un effort payant.
Vous pouvez retrouver la première partie de cet article sur le blog Ysance : Une approche Data Mesh pour le Data Warehousing

