
Le traitement du langage naturel (connu en anglais sous les termes “NLP, Natural language processing”) est un domaine de l’intelligence artificielle dans lequel les ordinateurs analysent, comprennent et donnent du sens aux contenus textuels et sonores des êtres humains.
En utilisant le NLP, les développeurs peuvent organiser et structurer les connaissances pour effectuer des tâches linguistiques telles que : la synthèse/le résumé automatique de contenus textuels, la traduction d’une langue vers une autre, la reconnaissance d’entités nommées dans un texte (lieu géographique, nom propre, adresse, …), l’analyse des sentiments (message positif, message à caractère sensible, …), la reconnaissance vocale ou encore la segmentation des sujets (classification des textes en fonction de leur thématique principale).
Le NLP est un domaine applicatif de l’IA assez complexe parce que comprendre le langage humain, c’est comprendre non seulement les mots, mais aussi les concepts sous-jacents et la façon dont, liés entre eux, des mots assez proches peuvent former des phrases complètement différentes.
Ce domaine n’a cessé d’évoluer ces dernières années et nous vous proposons dans cet article, une brève rétrospective des principales techniques utilisées aujourd’hui en entreprise.
Les techniques de pointe en NLP
Les outils de NLP ont évolué : des réseaux de neurones récurrents (RNN) aux modèles “Transformers”, en passant par les réseaux de mémoire à long court terme (LSTM). Aujourd’hui, il existe de nouveaux modèles révolutionnaires, notamment pour l’analyse de contenus textuels en langue française.
Retour sur les réseaux de neurones récurrents (RNN)
Nous l’avons vu dans l’article précédent (Attention is all you need : comprendre le traitement naturel du langage avec les modèles Transformers), un réseau de neurones récurrents (RNN) est un type de réseau de neurones artificiels qui utilise des données séquentielles ou des données de séries chronologiques. Ce type d’algorithme d’apprentissage profond est couramment utilisé pour la résolution de problèmes temporels, tels que la traduction, la reconnaissance vocale et le sous-titrage d’images. On peut retrouver cet algorithme dans des applications populaires comme Siri ou Google Translate.
À l’instar des réseaux de neurones à propagation avant (Feedforward) et convolutifs (CNN), les réseaux de neurones récurrents utilisent des données d’entraînement pour apprendre. Ils se distinguent par leur « mémoire » car ils prennent des informations d’entrées antérieures pour influencer l’entrée et la sortie actuelles. Alors que les réseaux de neurones profonds traditionnels supposent que les entrées et les sorties sont indépendantes les unes des autres, la sortie des réseaux de neurones récurrents dépend des éléments antérieurs de la séquence. Les événements futurs sont également utiles pour déterminer la sortie d’une séquence donnée mais les réseaux de neurones récurrents ne peuvent hélas pas tenir compte de ces événements dans leurs prédictions.
Nous l’avions vu dans les articles précédents, le modèle LSTM est une architecture de RNN qui a été introduite comme solution au problème dit des “Vanishing Gradients”. En effet, si l’état précédent qui influence la prédiction actuelle n’est pas dans un passé proche, le modèle RNN peut ne pas être en mesure de prédire avec précision l’état actuel du système. Pour y remédier, la typologie des LSTM est spécifique avec des « cellules » dans les couches cachées du réseau de neurones. Ces cellules sont constituées de trois portes : une porte d’entrée, une porte de sortie et une porte d’oubli. Ce sont ces portes qui contrôlent le flux d’informations nécessaire pour prédire la sortie dans le réseau.
Vers de nouvelles techniques innovantes : le mécanisme d’attention
L’article « Attention Is All You Need » (Vaswani et al., 2017) publié par Google Brain et Google Research en 2017 présentait des techniques pour le calcul parallèle de masse sur Google TPU.
Le mécanisme d’attention est au cœur de cet article (que nous vous conseillons à nouveau de lire : https://arxiv.org/pdf/1706.03762.pdf). L’attention permet au réseau d’effectuer un zoom avant précis et de se concentrer sur les mots contextuels pertinents à la fois dans la séquence d’entrée et dans les sorties prédites. La prédiction devient alors ultra-spécifique. Les modèles “Transformers” sont basés sur un mécanisme d’attention via un système d’encodeur/décodeur. Ils reposent entièrement sur le Self-Attention pour calculer de nombreuses représentations de son input et de son output. Il s’agit en fait de modèles capables d’attentions multiples à l’origine d’une amélioration très nette des prédictions en sortie du modèle.
Modèles de Transformers
Les Transformers fournissent des milliers de modèles pré-entraînés pour effectuer des tâches de traitement sur des corpus de textes : la classification, l’extraction d’informations, la réponse aux questions, le résumé/la synthèse, la traduction, et ce dans une centaine de langues. Parmi ces modèles, les plus populaires sont BERT (Devlin et al., 2018), GPT v1-3 (Radford et al., 2018), RoBERTa (Liu et al., 2019) et T5 (Raffel et al., 2019).
Dans cette section, nous parlerons brièvement de certains modèles de Transformers populaires. Dans la section suivante, nous analyserons les modèles de grandes tailles qui nécessitent d’énormes capacités de calcul.
Le modèle GPT, Generative Pre-trained Transformer
Les Transformers génératifs pré-entraînés sont des modèles de langage développés (en 2018 pour GPT-3) par OpenAI. Ces modèles facilitent le développement d’applications d’apprentissage automatique tout en permettant aux personnes ayant peu d’expérience en tant que développeur informatique de créer des applications.
GPT-3 est l’un des modèles les plus populaires de cette famille. Il s’agit de la troisième génération des Transformers pré-entraînés génératifs, qui fonctionne avec environ 175 milliards de paramètres.
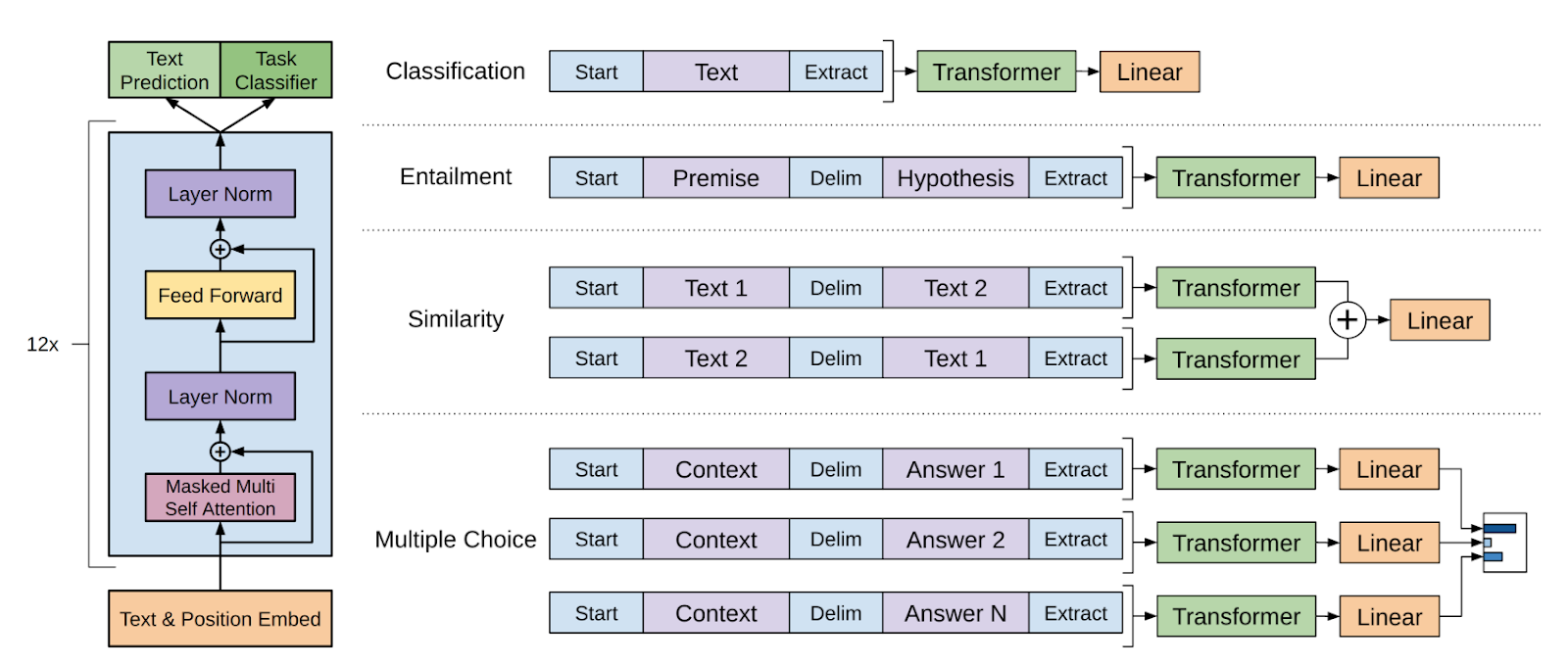
Figure 1 : (Gauche) Architecture générale du modèle GPT (Radford et al., 2018).
(Droite) Transformations et différentes tâches (Radford et al., 2018)
Le modèle BERT, Bidirectionnel Encoder Representations from Transformers
BERT (Devlin et al., 2018) est un article publié par des chercheurs de Google AI. Il a fait sensation au sein de la communauté en présentant des résultats meilleurs pour une grande variété de tâches de NLP.
L’innovation technique clé de BERT consiste à appliquer l’entraînement bidirectionnel du Transformer. Contrairement aux modèles unidirectionnels, qui lisent le texte saisi de manière séquentielle (de gauche à droite ou de droite à gauche), l’encodeur du Transformer dans le modèle de BERT lit toute la séquence de mots en une fois. Cette caractéristique permet au modèle d’apprendre le contexte d’un mot en fonction de tout son environnement (gauche et droite du mot).
Il faut savoir que BERT est pré-entraîné sur deux tâches de NLP différentes mais liées : la modélisation du langage masqué (en anglais on parle de MLM, Masked Language Model) et la prédiction de la phrase suivante (NSP, Next Sentence Prediction). Le MLM fonctionne comme suit : l’algorithme commence par masquer un mot dans une phrase. Ensuite, l’algorithme va chercher à prédire quels mots ont la plus grande probabilité d’être de bons remplaçants du mot caché, et ce en fonction du contexte. La NSP fonctionne en prédisant si deux phrases données ont une connexion logique (ou séquentielle) ou bien s’il n’y a pas de relation entre les phrases. Par exemple : Pierre est malade. Il a la grippe. Dans la dernière phrase, le pronom “il” renvoie à Pierre. Il y a donc une connexion logique causale entre ces deux phrases.
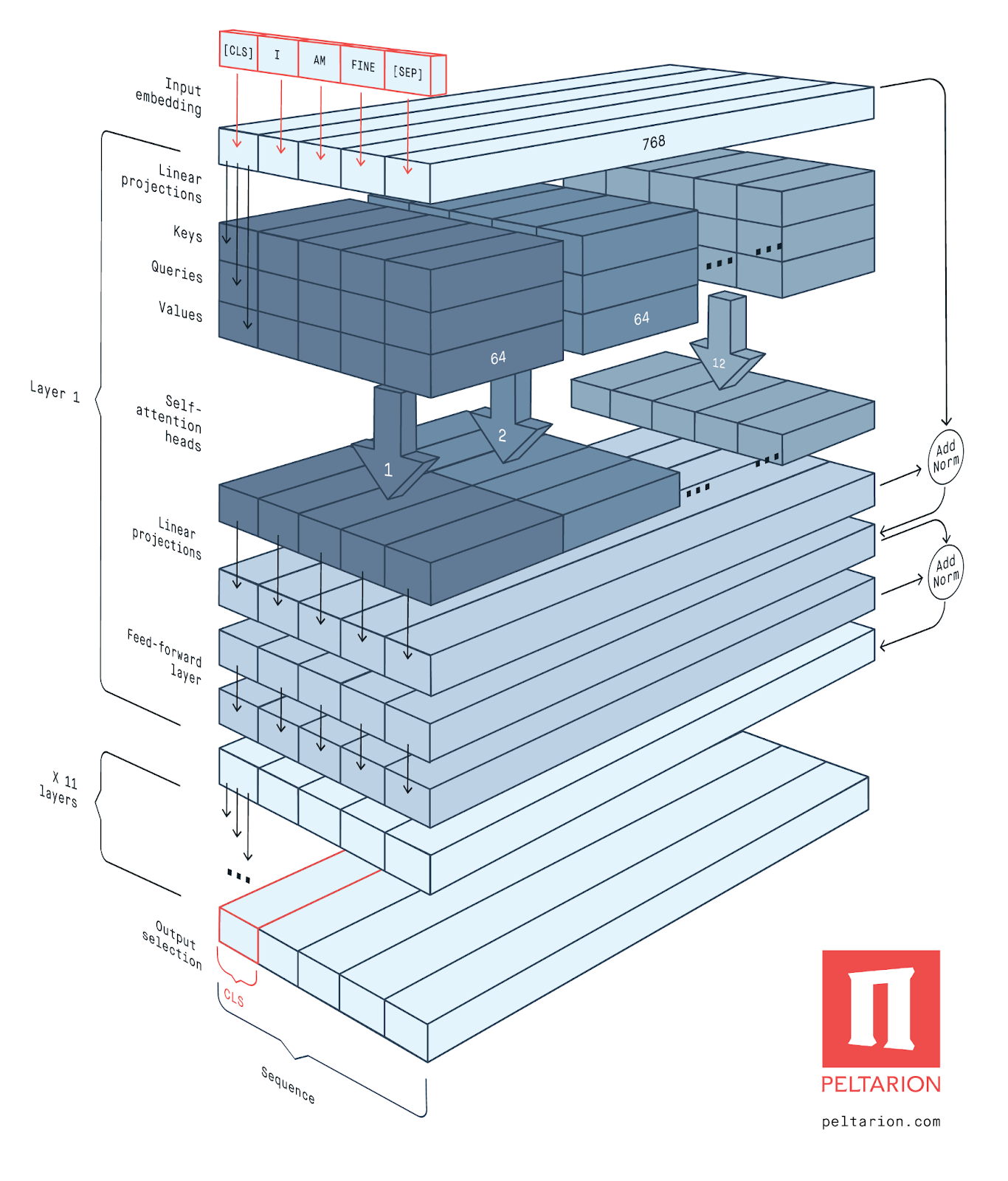
Figure 2 : Architecture générale de BERT (Peltarion, 2020)
RoBERTa
RoBERTa (Liu et al., 2019) s’appuie sur la stratégie de masquage MLM du modèle BERT, dans laquelle le système apprend à prédire des sections de texte intentionnellement cachées dans des exemples de langue non annotés. Au niveau technique, RoBERTa est une version de BERT pour laquelle certains hyperparamètres du pré-entraînement ont été modifiés. Pour RoBERTa, le méta-modèle NSP a été supprimé. De plus, en s’entraînant avec des mini-lots et des taux d’apprentissage beaucoup plus importants, RoBERTa est capable d’améliorer l’objectif de modélisation du langage masqué par rapport à BERT. Cela permet d’aboutir à de meilleures performances sur un grand nombre de tâches NLP.
CamemBERT
Les modèles de langage pré-entraînés sont désormais omniprésents dans le traitement du langage naturel. Malgré leurs succès, la plupart des modèles disponibles ont été formés soit sur des corpus textuels en langue anglaise, soit sur la concaténation de données dans plusieurs langues. Cela rend l’utilisation pratique de tels modèles limitée en France par exemple. Ainsi en France, CamemBERT a vu le jour. Il s’agit d’une version française des encodeurs bidirectionnels pour transformateurs (BERT).
CamemBERT (Martin et al., 2019) est un modèle linguistique de pointe pour le français, basé sur l’architecture RoBERTa pré-entraînée sur le corpus multilingue OSCAR. CamemBERT améliore l’état de l’art pour la plupart des tâches envisagées.
FlauBERT
Quelques mois après la sortie de CamemBERT, FlauBERT apparaît (Le et al., 2019). Il s’agit d’un modèle BERT français formé sur un corpus français très large et hétérogène. Des modèles de différentes tailles sont entraînés à l’aide du nouveau supercalculateur Jean Zay du CNRS (Centre National de la Recherche Scientifique). A noter que ce référentiel partage tous les modèles pré-entraînés, toutes les données, tous les codes-sources au grand public (si cela vous intéresse).
Avec FlauBERT vient FLUE : une configuration d’évaluation pour les systèmes NLP français similaire au célèbre benchmark GLUE. L’objectif est de permettre d’autres expériences reproductibles dans le futur et de partager des modèles pour la langue française. Les performances de FlauBERT et de CamemBERT sont très proches.
|
BERT |
RoBERTa |
CamemBERT |
FlauBERT |
|
| Langue |
Anglais |
Anglais |
Français |
Français |
| Données d’entraînement |
13 Go |
160 Go |
138 Go |
71 Go |
| Objectifs de pré- entraînement |
NSP et MLM |
MLM |
MLM |
MLM |
| Nombre de paramètres |
110 million |
125 million |
110 million |
138/373 million |
| Tokenizer |
WordPiece 30K |
BPE 50K |
SentencePiece 32K |
BPE 50K |
| Stratégie de masquage |
Statique + Masquage de sous-mots |
Dynamique + Masquage de sous-mots |
Dynamique + Masquage de mots entiers |
Dynamique + Masquage de sous-mots |
Figure 3 : Comparaison entre les différentes variantes de BERT (Le et al., 2019)
Text-to-Text Transfer Transformer (T5)
T5 Transformer (Raffel et al., 2O19) est une architecture de Google basée sur le Transformer qui utilise une approche de texte à texte. Le principe d’entraînement est le suivant : chaque tâche est conçue pour alimenter le texte modèle en entrée et l’entraîner à générer du texte cible. Ce modèle est basé sur la théorie de l’apprentissage par transfert, où un modèle est d’abord pré-entraîné sur une tâche globale, riche en données avant d’être affiné sur une tâche plus spécifique.
T-NLG, Turing Natural Language Generation & MT-NLG, Megatron-Turing Natural Language Generation
T-NLG de Microsoft (Turing-NLG, 2020) est un modèle de langage génératif basé sur Transformer, ce qui signifie qu’il peut générer des mots pour accomplir des tâches textuelles ouvertes. En plus de compléter une phrase inachevée, il peut générer des réponses directes aux questions et des résumés de documents. T-NLG est un modèle de langage à 17 milliards de paramètres qui surpasse l’état de l’art sur de nombreuses tâches NLP courantes.
Dans le cadre d’un récent partenariat avec Microsoft, NVIDIA a présenté l’un des plus grands modèles de langage de Transformer, le modèle MT-NLG, Megatron-Turing Natural Language Generation à plus de 530 milliards de paramètres. Ce modèle est alimenté par les modèles de Transformer DeepSpeed et Megatron. L’entraînement de MT-NLG a été possible, grâce aux efforts combinés de NVIDIA et de Microsoft. Ces entreprises ont atteint une efficacité d’entraînement sans précédent en combinant l’infrastructure d’entraînement accélérée par GPU SOTA, avec une pile logicielle d’apprentissage distribuée.
Taille des modèles NLP et performances
Ces dernières années, les modèles de langage basés sur des Transformers en NLP ont connu des progrès rapides, alimentés par le calcul à grande échelle, de grandes bases de données et des algorithmes de plus en plus sophistiqués.
Les modèles de langage avec un grand nombre de paramètres, bénéficiant de plus de données et de plus de temps d’entraînement acquièrent une compréhension plus riche et plus nuancée du langage. En conséquence, ils se généralisent avec une grande précision sur de nombreuses tâches NLP. Il n’est pas surprenant que le nombre de paramètres dans les modèles NLP de pointe ait augmenté à un rythme très soutenu. Ci-dessous, nous vous présentons dans l’ordre chronologique (mis-à-jour en Octobre 2021) les performances des principaux modèles NLP depuis 20218.
Il faut noter que l’entraînement de tels modèles est souvent difficile pour deux raisons principales :
- Il n’est pas possible de renseigner les paramètres de ces modèles dans la mémoire même du plus gros GPU
- Le grand nombre d’opérations de calculs requis peut entraîner des temps d’entraînement trop longs. Il faut alors chercher à optimiser les algorithmes, les logiciels ou le matériel.
MT-NLG possède 3 fois plus de paramètres par rapport aux plus grands modèles existants, y compris GPT-3 (175 milliards de paramètres), Turing NLG (17 milliards de paramètres), Megatron-LM (8 milliards de paramètres) et autres.
L’impact profond des modèles Transformers est devenu plus clair avec leur évolutivité vers des modèles de très grande capacité. Par exemple, le modèle BERT-large avec 340 millions de paramètres a été largement surpassé par le modèle GPT-3 avec 175 milliards de paramètres.
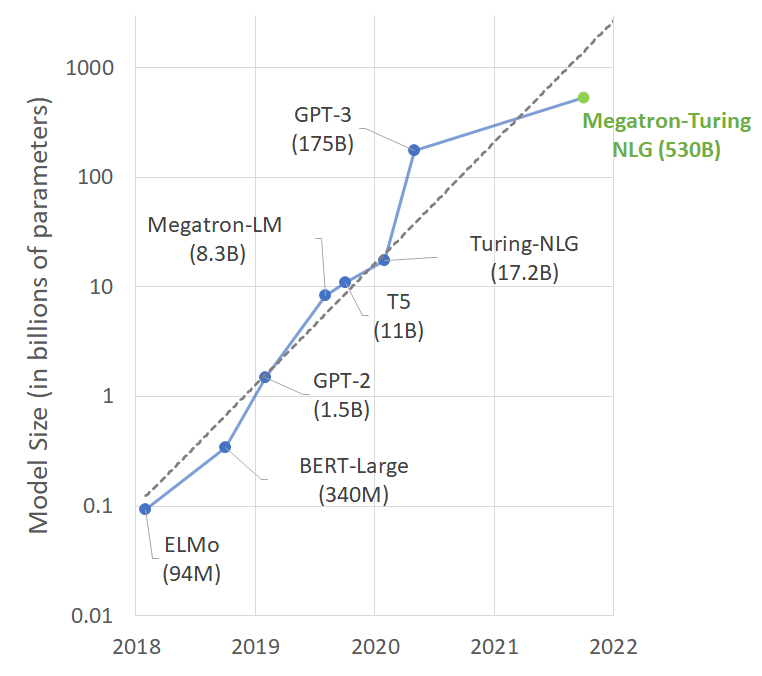
Figure 4 : Nombre de paramètres de plusieurs modèles de langage pré-entraînés récemment publiés (NVIDIA, 2021)
Le NLP est un domaine de l’IA qui évolue très rapidement. S’il existe de nombreux modèles, chacun d’entre eux possède des spécificités propres. Et, nous vous conseillons de bien vous documenter avant de partir dans l’industrialisation d’un modèle en particulier. En effet, si vous souhaitez entraîner un modèle capable d’extraire des entités dans un texte en français, il sera préférable d’utiliser FlauBERT plutôt que BERT ou RoBERTa, par exemple.
Actuellement, il existe peu de solutions industrialisées en entreprise dans le domaine du NLP à cause de la complexité des techniques d’IA. Cependant, nous sommes convaincus que le NLP est un levier de développement considérable pour l’automatisation de processus métiers en entreprise (processus dans lequel les données sont principalement textuelles comme les Ressources Humaines par exemple).
Bibliographie
(Clark et al., 2020) Clark, K., Luong, M. T., Le, Q. V., & Manning, C. D. (2020). Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555.
(Devlin et al., 2018) Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
(Le et al., 2019) Le, H., Vial, L., Frej, J., Segonne, V., Coavoux, M., Lecouteux, B., … & Schwab, D. (2019). Flaubert: Unsupervised language model pre-training for french. arXiv preprint arXiv:1912.05372.
(Liu et al., 2019) Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
(Peltarion, 2020) English BERT. https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/blocks/english-bert
(Martin et al., 2019) Martin, L., Muller, B., Suárez, P.J.O., Dupont, Y., Romary, L., de La Clergerie, É.V., Seddah, D. and Sagot, B., 2019. Camembert: a tasty french language model. arXiv preprint arXiv:1911.03894.
(NVIDIA, 2021) Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model. Oct 11, 2021
(Radford et al., 2018) Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
(Raffel et al., 2019) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
(Raffel et al., 2O19) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
(Turing-NLG, 2020) Turing-NLG: A 17-billion-parameter language model by Microsoft. (2020)
(Vaswani et al., 2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).

