Introduction
Pourquoi mesurer ?
Que l’on fasse partie d’une entreprise dans laquelle une transformation DevOps est déjà en cours ou bien que l’on soit au tout début du chemin, il est crucial de définir les objectifs que l’on souhaite atteindre, de disposer de métriques de suivi associées et d’en prendre le pouls régulièrement.
Alors pourquoi cette obsession de la mesure… La réponse tient en une citation attribuée à Peter Drucker : “If you can’t measure it you can’t improve it.”

En effet, si il n’y avait qu’un seul objectif d’entreprise à conserver au titre d’une transformation DevOps, je ne garderais que celui qui consiste à réussir à faire pivoter les équipes et les directions IT dans une culture profonde de transformation et d’amélioration continue.
La culture de la mesure et du partage transparent des indicateurs collectés entre les équipes à tous niveaux, sont parmi les activateurs les plus opérationnels et les plus efficaces de l’amélioration continue.
Mesurer, constater, analyser, améliorer et recommencer.
Que mesurer ?
Au sein des galaxies DevOps & Agile gravitent des écosystèmes entiers d’outils qui fournissent une multitude d’indicateurs qui peuvent être suivis, alors comment choisir ?
Premier élément de réponse: cela dépend !
Plus sérieusement, c’est intimement lié aux enjeux métier poursuivis par la transformation que vous avez initiée.
Que souhaitez-vous améliorer ? Quels sont les objectifs de votre transformation ? Quelle est la valeur créée ? Cela dépend du cœur de métier dans lequel vous opérez.
Éditeur de logiciels ? Le suivi des défauts ou erreurs & bugs sera sans doute crucial pour vous, avec un double objectif visant d’une part à réduire les délais de traitement et d’autre part à améliorer la qualité de vos livraisons applicatives.
Opérateur d’un service IT transverse à l’entreprise ? La supervision fine du MTTR (Mean Time To Recover) et la capacité de vos équipes à basculer vers des architectures élastiques & résilientes seront alors plus opportunes.
En bref, choisissez des métriques qui vous ressemblent et qui reflètent réellement les enjeux auxquels vous faites face.
Flow & Value
Un des aspects les plus importants de la démarche DevOps, intimement liée au Lean, est le flux de valeur. Accélérer et fluidifier le flux de valeur de bout en bout. Voilà le maître-mot. C’est le fameux “Time-To-Value”.
C’est donc un des périmètres de mesure les plus cruciaux, car il représente véritablement ce que la majorité des équipes essaie d’améliorer : le Time-To-Market !
En amont et durant vos différentes phases de transformation, les exercices de Value Stream Mapping (VSM) restent extrêmement importants. Qu’ils soient menés de manière formelle au travers d’ateliers pour embrasser tout le flux de bout en bout, ou qu’ils soient menés de proche en proche à chaque sprint pour s’améliorer au prochain cycle, la modélisation de vos flux de valeurs est essentielle.
Une fois cette modélisation connue et partagée, une fois ce flux formalisé, il conviendra bien évidemment de le mettre sous surveillance et d’observer son amélioration au travers des différentes actions opérationnelles de vos chantiers de transformation.
Il convient à ce niveau de distinguer 2 indicateurs qui peuvent être confondus :
- Lead Time
- Flow Time
Le schéma ci dessous représente ces deux indicateurs :
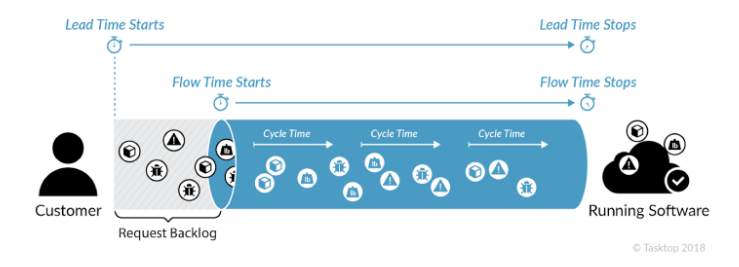
Lead Time : Le temps écoulé entre une demande issue d’un client et sa réalisation en production.
Flow Time : Le temps écoulé entre le moment ou l’on commence “réellement” à travailler sur une demande et sa réalisation en production.
Selon la configuration de votre métier et son contexte, il peut être normal d’avoir beaucoup d’éléments de demandes qui restent bloqués au niveau de votre backlog de requêtes.
Donc même si le “Lead Time” reste un des indicateurs les plus reconnus, et qu’il modélise bien l’entièreté du flux, il peut être plus adapté dans de nombreux contextes de suivre le Flow Time pour être plus représentatif de l’activité réelle des équipes, une fois que celles-ci sont vraiment engagées dans le flux de travail.
Dans tous les cas, ces indicateurs de suivi de votre flux de valeurs sont sans doute parmi les plus importants car ils permettent de réellement suivre l’amélioration de la vélocité de vos livraisons applicatives.
DORA Metrics
Passage obligé, impossible de ne pas présenter les quatre “Big Four” des métriques les plus connues et reconnues sur le marché. Formalisées et explicités par les équipes DORA (DevOps Research and Assessment), ces quatre indicateurs sont incontournables car ils résument les principaux leviers sur lesquels la démarche et les pratiques DevOps étendent leur influence.
Lead Time (Lead Time for Change)
Nota Bene : Il s’agit bien du Lead Time for Change ici, pas du Lead Time de bout en bout évoqué précédemment. (Définition en anglais du Lead Time for Change : “The amount of time it takes a commit to get into production”).
Cette métrique mesure le temps qui s’écoule avant qu’un code validé entre en production.
Alors que la fréquence de déploiement mesure la cadence de publication de nouveau code, le délai d’exécution des modifications mesure la vitesse de livraison du logiciel.
Il est utilisé pour mieux comprendre le temps des cycles de l’équipe DevOps et pour savoir comment une augmentation des demandes est gérée. Plus le délai d’exécution des modifications est court, plus le Lead Time est court, plus une équipe DevOps est efficace dans le déploiement de code.
Afin de mesurer le Lead Time for Change, deux éléments de données (ou horodatages) sont nécessaires : l’heure exacte de la validation et l’heure exacte du déploiement – en d’autres termes, le temps entre le début et la fin d’un produit. Le temps moyen est ensuite utilisé comme indicateur de la performance globale.
| Question it answers | Elite performers | High performers | Medium performers | Low performers |
| How long does it take to go from code committed to code successfully running in production? | Less than one day | Between one day and one week | Between one week and one month | Between one month and six months |
Deployment Frequency
Comme son nom nous l’indique déjà, la fréquence de déploiement fait référence à la fréquence des versions logicielles réussies en production. En d’autres termes, il mesure la fréquence à laquelle une entreprise déploie du code pour une application particulière.
La métrique qui utilise le nombre total de déploiements par jour comme guide de référence a été développée sur la base de concepts de fabrication qui mesurent et contrôlent la taille des lots de stocks qu’une entreprise livre.
Naturellement, les entreprises les plus performantes ont tendance à effectuer des livraisons plus petites et beaucoup plus fréquentes – ou dans le monde du DevOps, des déploiements plus fréquents mais plus petits.
En général, un déploiement par semaine est la norme, alors qu’une entreprise performante publie jusqu’à sept déploiements par jour. Bien sûr, ce nombre standard de déploiements se différencie selon le produit que vous manipulez (Application mobile, solution SaaS, …)
| Question it answers | Elite performers | High performers | Medium performers | Low performers |
| How often does your organization deploy code to production or release it to end-users? | On-demand (multiple deployments per day) | Between once per day and once per week | Between once per week and once per month | Between once per month and once every six months |
Change Failure Rate
Cette métrique capture le pourcentage de modifications apportées à un code qui ont ensuite entraîné des incidents, des retours en arrière ou tout type d’échec en production. Ainsi, le taux d’échec des modifications est une véritable mesure de la qualité et de la stabilité, tandis que les mesures précédentes, la fréquence de déploiement et le délai d’exécution des modifications, n’indiquent pas la qualité du logiciel, mais uniquement le rythme de livraison du logiciel.
Le taux d’échec des modifications est calculé en comptant le nombre d’échecs de déploiement, puis en le divisant par le nombre total de déploiements. Lorsqu’elle est suivie au fil du temps, cette métrique fournit un excellent aperçu du temps consacré à la correction des erreurs et des bugs par rapport à la livraison de nouveau code. Inutile de dire qu’une équipe DevOps doit toujours rechercher ici la moyenne la plus basse possible.
| Question it answers | Elite performers | High performers | Medium performers | Low performers |
| What percentage of changes to production or end-users results in degraded service? | 0-15% | 0-15% | 0-15% | 46-60% |
MTTR
La mesure du temps moyen de “récupération” ou de correction mesure le temps nécessaire à un service pour rebondir après une panne. Peu importe la performance d’une équipe DevOps, des pannes ou des incidents se produisent toujours. Et puisque les pannes ne peuvent toutes être évitées, c’est vraiment le temps nécessaire pour restaurer ou récupérer un système ou une application qui fait la différence.
Si une entreprise dispose de temps de récupération courts sur les incidents subis par ses services IT, les managers se sentiront généralement plus à l’aise lorsque leurs équipes leur proposeront des expérimentations et des innovations raisonnables.
Cette métrique est importante, car elle encourage les équipes à construire des systèmes plus robustes. Le MTTR est généralement calculé en suivant le temps moyen entre le moment où le bug/incident est rapporté et le moment où le correctif de bug/incident est déployé.
Nota : Le MTTR peut être utilisé de plusieurs façons différentes selon les contextes :
Ex 1 : Temps moyen entre un rapport de bug et le déploiement du correctif en production
Ex 2 : Temps moyen entre la déclaration d’un arrêt de service et son rétablissement
| Question it answers | Elite performers | High performers | Medium performers | Low performers |
| How long does it take to restore service when a service incident or a defect that impacts users occurs? | Less than an hour | Less than one day | Less than one day | Between one week and one month |
Autres indicateurs
Au-delà de ces quatre indicateurs centraux, il existe une multitude d’autres indicateurs extrêmement intéressants. En voici quelques-uns listés et explicités ci-dessous.
Indicateurs de Delivery
Cycle Time : Le temps passé par l’équipe pour travailler et livrer un “article” (une Work Unit)
>> Pertinent pour vérifier que l’équipe travaille bien sur des éléments « suffisamment » petits, et non pas sur des éléments trop importants qui leur nécessiteraient plusieurs cycles.
Waiting Time : Le temps passé à attendre des éléments ou des exigences externes
>> Pertinent pour vérifier par exemple qu’au fil de votre transformation, ces temps d’attente diminuent (temps de mise à disposition d’un environnement avant de pouvoir déployer, temps nécessaire pour avoir un rapport d’analyse de code, etc.).
% complete and accurate : La proportion d’éléments passés à l’étape suivante qui ne nécessitent pas de correction ou de réécriture.
>> Très intéressant, notamment mis en regard avec les indicateurs de Lead Time ou de Flow Time : rien ne sert de courir si c’est pour ne pas arriver à point. Dans notre cas, inutile d’avoir un Flow Time excellent si cela se traduit par des bugs et des correctifs incessants consécutifs aux mises en production.
Unplanned work rate : le rapport entre le temps consacré aux activités non planifiées et planifiées.
>> Pertinent pour mesurer à quel point les équipes sont submergées ou pas par des sollicitations de dernière minute venant impacter leur flux de travail nominal.
Indicateurs de Qualité
Test coverage : Le pourcentage du produit (Le nombre de lignes de code, le nombre de fonctionnalités, etc.) couvert par des tests, quels qu’ils soient.
>> Pertinent lorsque ces seuils ne sont pas fixés arbitrairement et qu’ils n’entraînent pas “du test pour du test”, uniquement pour avoir des seuils en phase avec les règles établies.
Defect escape rate : La mesure du taux “d’échappement” des défauts ou erreurs est utilisée pour identifier le taux de problèmes identifiés après la mise en production d’un logiciel.
>> Un taux d’échappement des défauts (trop) élevé peut notamment indiquer qu’il y a un problème avec les processus de test ou les outils de test automatisés utilisés.
Mean time to detection (MTTD) : La mesure du temps moyen nécessaire pour détecter un incident
>> Très intéressant quand lié au MTTR : plus un incident est détecté tôt, plus il est susceptible d’être résolu rapidement !
Availability / uptime (et Error Budget) : Le pourcentage du temps pendant lequel l’application ou le service est considéré comme disponible et totalement fonctionnel pour les utilisateurs.
>> Étendu et renforcé dans les pratiques SRE avec l’error budgeting, cela reste également un indicateur clef car il mesure bien la disponibilité du service en regard de l’accélération portée sur le delivery au travers de votre transformation.
Erreurs courantes
Trop de mesure tue la mesure !
C’est un évidence mais je préfère l’écrire…
La galaxie bouillonnante des acteurs de la démarche DevOps, évangélistes, éditeurs, prescripteurs, etc. fournit une liste presque infinie d’indicateurs qui peuvent être suivis par tous les acteurs de la DSI.
Facile donc de s’y perdre rapidement, et de voir fleurir des initiatives éparpillées menées par des équipes qui implémentent chacune leurs indicateurs. Pire, même lorsque ces initiatives sont centrales aux DSI et qu’elles se traduisent en tableaux de bord avec des dizaines d’indicateurs tous intéressants, mais trop nombreux pour fournir un vrai focus sur ce qui compte pour la réussite de leur transformation.
Un seul conseil à ce niveau, définissez un nombre restreint d’indicateurs de suivi, si possible pré intégrés et délivrés automatiquement par vos outillages en place. À ce titre, l’implémentation et le suivi des quatre métriques DORA sont et restent un bon point de départ.
The big fail : des indicateurs “DevOps” dans une feuille de calcul
Également évident, mais tellement déjà vu !
Interdiction absolue d’implémenter ces indicateurs ou de les agréger dans votre tableur préféré.
Tableur + DevOps = fail ! C’est un antipattern de la démarche !
La tentation du micromanagement
Ah, l’irrésistible envie d’envoyer via votre messagerie instantanée préférée une question à l’un de vos team leaders pour savoir pourquoi le nombre de d’erreurs à augmenté de 2% par rapport à la semaine précédente…
Et bien non, essayez de réfréner vos envies ! Ces indicateurs et tous ces tableaux de bord doivent être partagés en toute transparence (le partage est un des piliers DevOps !), et surtout utilisés avec beaucoup de bienveillance. Ces données fournissent des informations, des indications, des tendances, qui doivent être partagées et discutées avec les équipes, et non pas utilisées en mode réactif et dans l’instantanéité. Cela serait contreproductif et par-dessus tout potentiellement toxique avec des équipes, matures ou pas d’ailleurs, qui verraient dans ce type de comportement un frein puissant à leur envie de partage de leurs métriques. Pour les équipes au début de leur démarche, cela se traduirait par une crispation sur leur activités par peur de “mal faire” et que “cela se voit”. Pour les équipes matures, cela serait vécu comme une incursion inopportune dans leur activité, et potentiellement comme une méconnaissance de leur activité quotidienne .
A éviter donc !
Proxy Indicators
Ils peuvent être utiles, mais sont à éviter en tant que réelles métriques de suivi complet de votre transformation. Mais juste un instant… que sont ces “proxy indicators” ?
Définition : Il s’agit d’un indicateur quantitatif qui fournit des informations sur un aspect précis d’un contexte. Exemple dans notre cas : le nombre d’utilisateurs actifs de votre plateforme de CI/CD, le nombre de personnes ayant suivi un parcours de formation, etc.
Ces indicateurs quantitatifs restent donc intéressants, dans les exemples donnés ci-dessus ils permettent notamment de suivre une progression d’utilisation d’outillage ou de vérifier le pourcentage des équipes ayant bénéficié de contenus de formation support de votre transformation.
Par contre, ces indicateurs ne témoignent pas réellement de la progression et de l’ancrage de votre transformation, et encore moins de sa réussite par rapport aux objectifs que vous poursuivez.
Ces indicateurs doivent donc être manipulés avec précaution et ne doivent être que des indicateurs complémentaires de ceux mis en place pour monitorer le “cœur” de votre transformation.
Conclusion
Si vous ne deviez retenir qu’une métrique : Le Lead / Flow Time.
Si vous ne deviez en retenir que quatre : Les métriques DORA.
Pour tous les indicateurs : à partager en toute transparence, à utiliser avec bienveillance !
Sinon, une fois de plus et en accord avec la démarche DevOps : démarrez petit, avec peu d’indicateurs, reflétant bien vos enjeux. Ensuite, après quelques cycles, définissez avec vos équipes les indicateurs à conserver, ceux à sacraliser, … en bref inscrivez-vous une fois encore dans une démarche d’amélioration continue !
Et pour finir, lorsque vous en avez la capacité, agrégez ces indicateurs avec d’autres au niveau Delivery, Production, ITSM, etc … et créez avec et pour vos équipes des tableaux de bord composites 365°. En effet, rien de plus puissant qu’un tableau de bord visuel unique où sont mis en regard la vélocité, les courbes d’évolution de bugs, la disponibilité du service, la charge des composants techniques sous-jacents… pour créer des terrains de discussion et d’amélioration au sein et entre vos équipes.
Sources diverses d’inspiration
Explication des 4 métriques DORA sur le portail Google Cloud (et plein d’autres ressources hyper interressantes) : https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance
Topo Pal’s DevOps Metrics & Measurements Playlist : https://itrevolution.com/topo-pal-metrics-playlist/

